はじめに
皆さん、Webで探している情報がなかなか出ずに時間を浪費してしまった経験はないでしょうか。
私も気をつけないと延々と検索してしまっていることがあります。このような何度検索しても欲しい情報が得られない検索迷子状態になったことは少なからずあると思います。
検索迷子状態を客観的に判断できれば無為な時間を過ごさなくて良くなると思い、手元にある情報で判定できそうか調査を行いました。
本記事では数人の検索履歴を用い、検索クエリがどのように変遷しているのかを分析することにより検索迷子状態を判定できないか調査、分析しました。
結果として検索迷子状態を明確に判定することは出来ませんでしたが、分析の変数を増やしたり別の切り口で傾向をつかむことは出来るのではないかと感じました。
検索迷子状態について
仮定
今回は検索迷子状態になっている状況を判断する要素として検索クエリの変化が有効であると仮定しました。
単語の組み合わせを変えて繰り返し検索を行っても似たページばかりヒットしてしまうのは当然だと思います。また、言い回しを変えただけであっても有益なページに出会う確率は低いでしょう。
つまり、検索クエリの変化が乏しければ検索迷子状態になりつつあると言えると思います。
問題解消のための既存技術
一方で検索迷子状態ではないと言えるのは検索対象について新たな情報が得られたり、新しい発想で検索クエリを変更することにより求めていたページに近づいていると言えます。
検索迷子状態を防ぐためにGoogle Suggestなどに代表されるクエリ拡張や、他のユーザーの検索情報を利用した協調フィルタリングを基に、ユーザーの嗜好から検索結果の推薦を行なうなどにより解決が図られています。
今回の確認点
一方で、本記事では検索迷子状態の解消ではなく検知することは出来ないかを確認しました。
具体的な語句についての検索であれば既存技術で解消することはできますが、検索語句がはっきり理解できていない事による検索迷子状態はまだうまく解決出来ないことがあると考えています。
そこでまずは検索迷子状態になった状況を把握することで周囲からサポートを貰うように促したいと考えたため、判定することが出来るのかを調査しました。
解析概要
今回は以下の流れで調査を行いました。

1.Google Chromeから検索クエリの取得
2.Pythonを用いて検索クエリの変遷を分析
3.結果をグラフ化
環境・用いたもの
・Mac
・Google Chromeの検索履歴
・Python(3.6.0)
解析
Google Chrome 検索履歴
検索履歴データの配置箇所
Google Chromeでは閲覧したページ履歴だけでなく、検索クエリの情報や対象URLの最終閲覧日などの情報がローカルに保存されています。
~/Library/Application\ Support/Google/Chrome/Default/History
Local Settings/Application Data/Google/Chrome/User Data/Default/History
検索履歴データの閲覧
Historyはアプリケーション上で動作するRDBMSであるSQLite3形式で保存されています。
閲覧するためにはMacであれば特別に用意しなくてもCUIから閲覧することが出来ます。
閲覧の際は一度コピーを取ってから行なうほうがよいでしょう。
$sqlite3 History
oracleなどと似たようなSQL文で扱うことができるのでRDBMSに触れたことがある人ならデータ取得などには特に困らないと思います。
よく利用する特徴的なコマンドとして スキーマ情報を出力する.schema やテーブル一覧を出力する.table、 出力先を変更する.outputなど覚えておけば苦労しないと思います。
外部SQLファイルを読み込んで実行する事も.read ファイル名とすることでも実行出来ます。
[参考]
http://qiita.com/northriver/items/3f48f27b60f6362d330c
http://l-w-i.net/t/sqlite/ext_001.txt
https://www.dbonline.jp/sqlite/sqlite_command/list.html
また、以下アプリケーションをインストールすることによりGUIで扱うことが出来ます。(Windows,Mac両方対応してます)
DB Browser for SQLite
検索履歴データについて
今回は検索クエリ履歴テーブルの情報であるkeyword_search_termsを利用しました。

また、History内のデータについて、詳しい情報がなかなか無かったので調査をして判明した情報を記載しておきます。
・カラム名について
各テーブルに同名カラム名がありますが、同じ意味であるとは限らないので注意が必要です。
例)urls.id = visits.url
・日付時刻の情報について
カラムによって基準日と単位が異なるので注意が必要です。
visits.visit_timeは1961年1月1日基準、単位はマイクロセカンド
downloads.start_timeは1970年1月1日基準、単位はセカンド
[参考]http://www.forensicswiki.org/wiki/Google_Chrome
・transitionについて
カラムによってはフォーマットが不明なため、理解できない項目が多くあります。
今回用いていませんが、urls.transitionはどの様にして該当ページに遷移してきたのかを示すコードです。
(他ページからのlinkや直接URLを入力して開いたtypedなど)
2進数から16進数に変換し、0xFFと論理積を取ることで遷移コードを求める事が出来ます。
[参考]遷移コード値の求め方
https://groups.google.com/a/chromium.org/forum/#!topic/chromium-discuss/r7UQ2i98Lu4
[参考]遷移コード値の意味
https://developer.chrome.com/extensions/history
検索効率 測定
検索スコアについて
検索の試行毎にこれまでの検索クエリとの類似度を計測し、類似単語が多ければ検索効率が悪くなることを示すスコアを算出しました。
- 前回までのと今回の検索クエリについて、単語毎に類似度比較を行なう
- 最も類似している組み合わせの類似度を採用
- 各単語の類似度の相加平均を求め、その検索の検索スコアとする
単語同士の類似度の計算はPythonに標準ライブラリとして用意してあるdifflibを用いました。SequenceMatcherで比較し、類似度を算出します。
以下のようにして用いることが出来ます。
類似度は0(全く一致しない)〜1(完全に一致する)で算出されます。
>>> difflib.SequenceMatcher(None, 'python','python3').ratio()
0.9230769230769231
これを用いて検索スコアを算出した例が以下となります。
赤線で結ばれたものが最も類似度が高い単語の組み合わせです。
検索2回目のスコアは「0.64」となります。
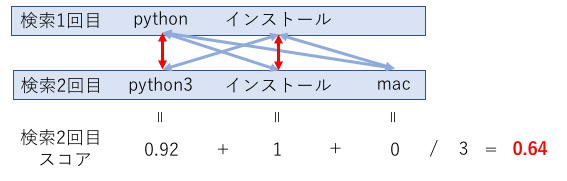
算出された検索スコアは0に近いほど類似度が低いと判断でき、検索迷子状態であるかの判断材料にしたいと思います。
実験
対象データ
4名の人からChromeのhistoryを頂き、確認を行いました。
履歴内容についてはこちらから提示した課題について10分間で検索してもらったいました。それに加え、普段利用していた任意の検索履歴を対象データとしました。
1名については私の先輩であり調査タスクの処理がとても早いです。他の3名は後輩です。
事前処理
ある一つの目的に沿って検索が行われたと思われる検索クエリの変遷のみを抽出し、テストデータとしました。
また、ChromeのHistoryは検索クエリそのままの情報と英字を全て小文字にしてある情報の両者を保持しているため、今回は小文字に変換されたほうの情報を用いました。
以下例題です。
postgresql mac インストール
postgresql mac インストール 場所
postgresql mac インストール 場所指定
postgresql mac インストール ディレクトリ 変更

横軸は検索試行回数であり、縦軸が検索スコアです。1回目は比較対象がいないため、0となっています。
この例では検索クエリがあまり変化していないため検索スコアが伸び続けています。
結果

共通課題のスコアについて
赤線が共通の課題について検索してもらった結果です。先輩は6回目にして目標情報にたどり着きましたが、他3名は時間切れになりました。
先輩は4回目から5回目に掛けて検索スコアが大幅に低下しており、クエリを確認したところガラッと変わっていました。ヒアリングを行なうと検索当初は抽象的な単語でしか検索できなかったが、進めていく中で検索すべき具体的な単語が見つかったとのことでした。
一方Aさん、Cさんは検索クエリになかなか大きな変化がなく、悩んでいる状況が読み取れました。
また、Bさんの青線のデータに着目した際に5回目〜6回目にスコアが低下していますが英語から日本語への読み替えを行っただけでした。これが頭打ち状況であると言えるか否かは賛否があると思います。
通常検索のスコアについて
グラフから読み取るに、調査能力の高い先輩は検索スコアが低くなっているとの印象を受けましたが、データが少ないため妥当性があるかは追加調査が必要そうです。
今後に向けて
・スコア算出方法の改良
検索迷子状態の傾向として仮定した検索スコアが有益である可能性はまだあると感じましたので、スコアの算出方法の改良を行っていこうと思います。
・検索スコアを利用したサービス
検索迷子状態を解消するために検索スコアのしきい値を定め、超えた場合はユーザーへ自覚してもらうために通知したり、周囲に連携するなどのサービスが作れたらと考えています。