はじめに
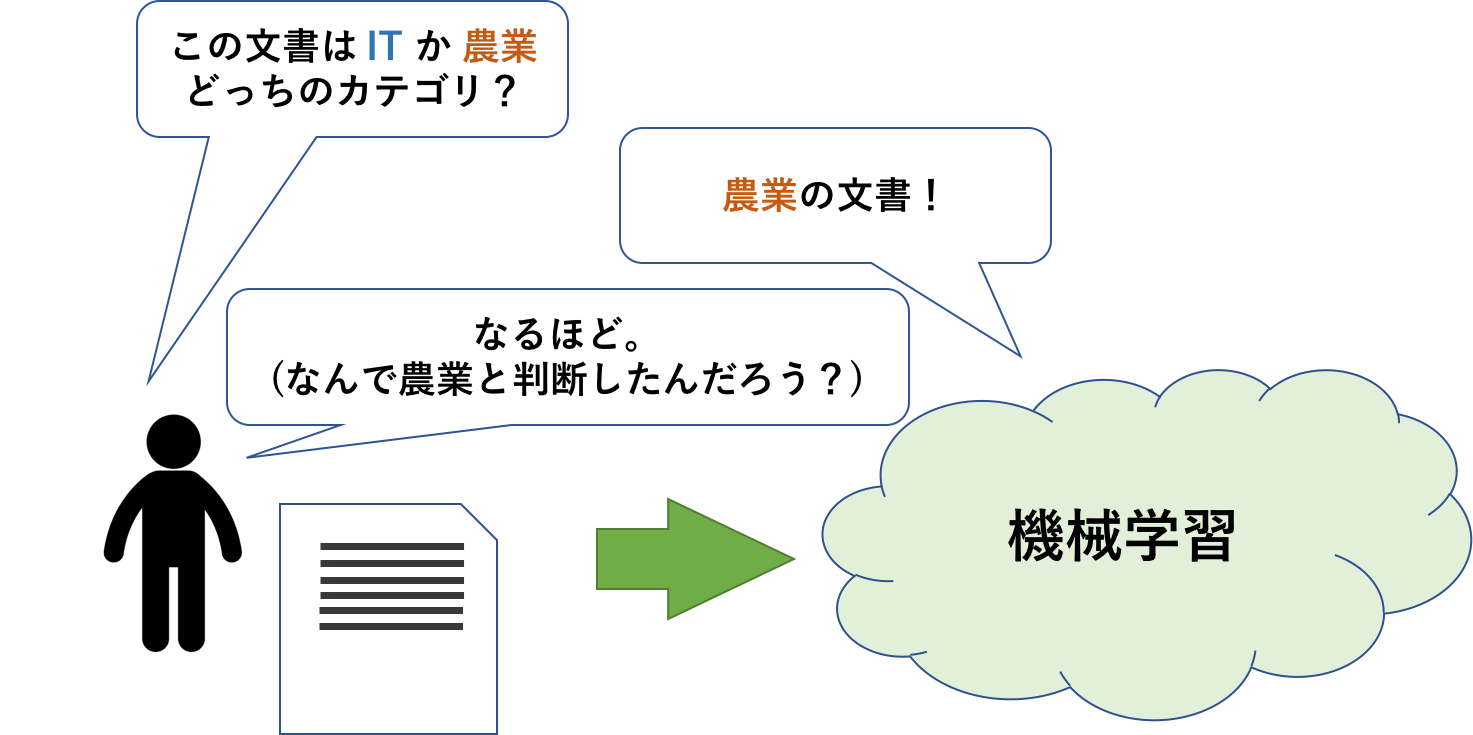
機械学習を使ってみたけど、なんでこんな結果になったの?と思ったことはないでしょうか。手法によっては要因を読み解くことができます。本記事ではナイーブベイズを題材とし、文書分類における単語の「尤度」について紹介します。
scikit-learnでの確認を**githubに公開しています**ので、合わせて御覧ください。
ナイーブベイズにおける文書分類
文書分類とは
文書分類は予め与えられた訓練データ(文書)をもとに学習し、新たな文書を与えられたカテゴリに分類するタスクです。
文書を学習する際何を元に分類させるか、特徴を与える必要があります。今回は単語を特徴として与える手法について説明します。
文書の特徴としての尤度
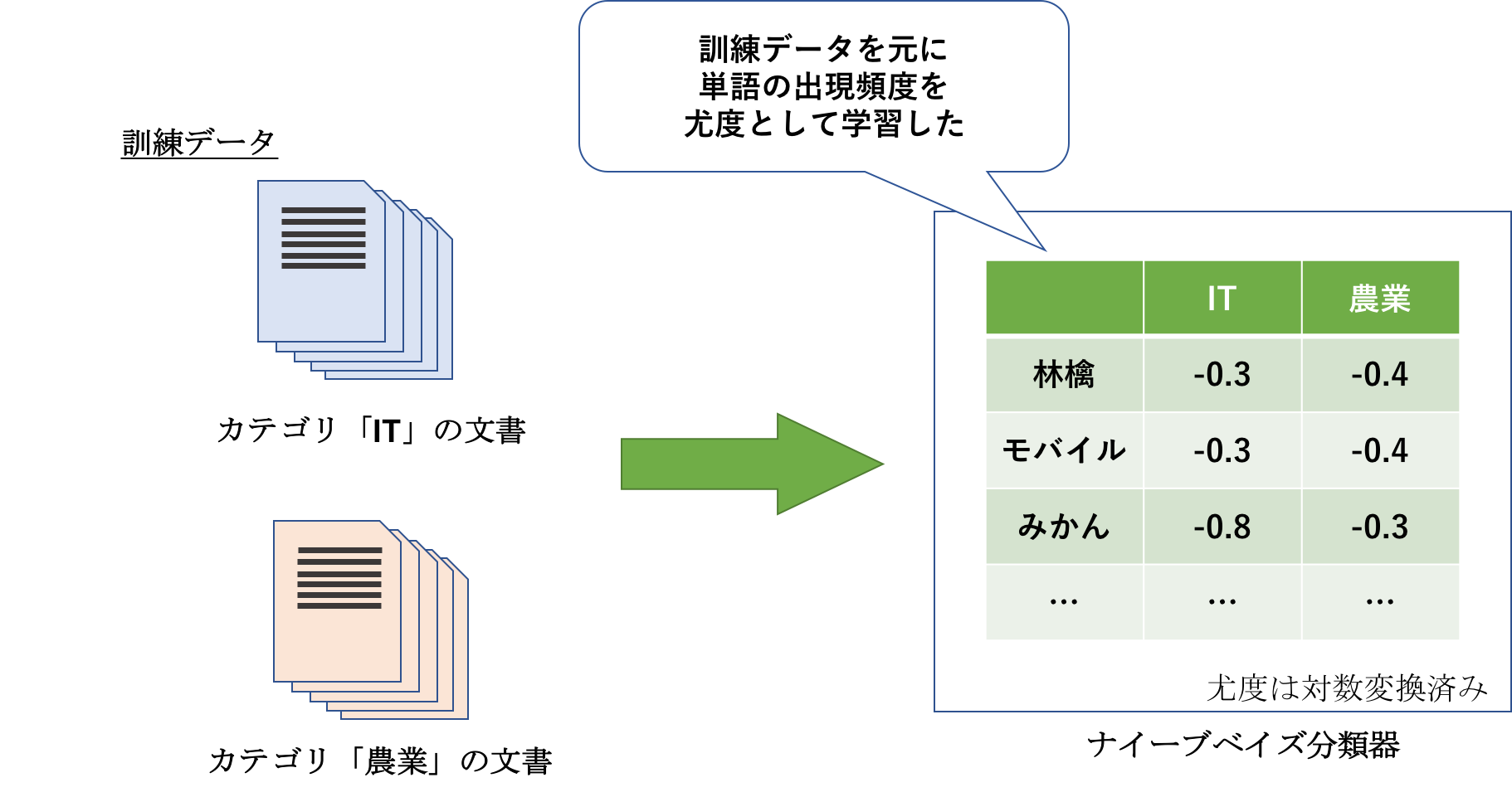
文書の特徴に単語を扱う中でも、出現頻度とする手法があります。学習において、出現頻度は各カテゴリ・単語毎に尤度として表されます(厳密には異なりますが、確率のようなものと考えて下さい)。
尤度がどのように分類に関わるのか、ナイーブベイズで用いられるベイズの定理を絡め、確認します。
ベイズの定理
文書判別は文書が各カテゴリに属する確率によって求められます。確率が最も高いカテゴリを推定結果とするということです。確率はベイズの定理で算出され、その中で尤度が用いられています。
- ベイズの定理
P(C|Fi) = \frac{P(C)P(Fi|C)}{P(Fi)}\\
(C:カテゴリ、Fi:特徴集合 ≒ 単語の集合、つまり文書)
■各要素の説明
- $P(C|Fi)$
- 文書FiがカテゴリCに属する確率(事後確率)。
- $P(C)$
- カテゴリCが出現する確率(事前確率)。 文書の内容を考慮せず、訓練データにおいて該当のカテゴリが出現した確率です。 例:2000文書中ITカテゴリが1400文書あったなら、0.7
- $P(Fi|C)$
- もしカテゴリCであるとした時、特徴集合Fiとして出現する確率です。(尤度)
- $P(Fi)$
- 文書がFiとして出現する確率です。 Cが関係していない通り、どのカテゴリの事後確率でも等しくなります。 判別の場合はカテゴリ毎の事後確率を比較すればよいので、除外して計算されることが多いです。
例題にて尤度計算の確認
以下条件時に、各カテゴリにおける各単語の尤度が学習結果から得られていたとします。
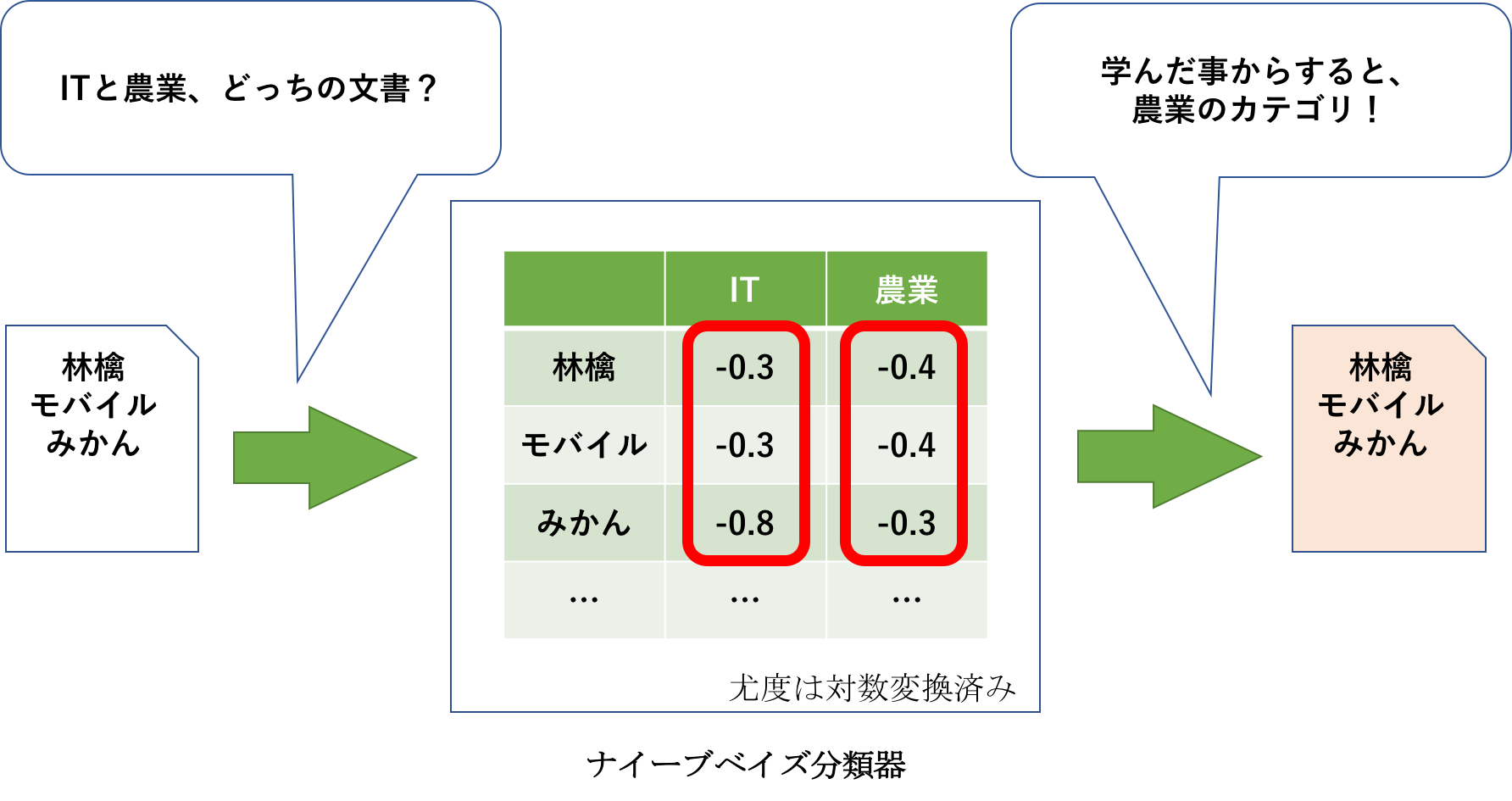
判別を行いたい文書の特徴集合が「林檎 発売 みかん」だった場合、各カテゴリの尤度P(Fi|C)は以下のように算出されます。P(Fi|C)は各尤度の積ですが、対数になっているので加算で求めることができます。
IT: $-0.3 + -0.3 + -0.8 = -1.4$
農業: $-0.4 + -0.4 + -0.3 = -1.1$
今回は尤度だけ見ると農業カテゴリと推定されることになります。
上記の通り、各単語の尤度が大きくなるほど事後確率も上がっている事が分かります。
例では「みかん」という単語の尤度に大きな差があり、判別に大きく影響していることが分かります。
事前確率にもよりますが、カテゴリ間で尤度の差が大きい単語ほどこの分類器では判別に影響すると言えます。
実データ確認
実データで尤度を確認してみます。映画レビューデータセットである「Movie Data Review」を用いて、ポジティブレビューとネガティブレビューを分類しました。学習後、尤度の差が大きかった単語上位10件は以下のようになりました。
「mulan」など固有名詞の他に、「worst」などの形容詞が表れています。
| 単語 | ネガティブ | ポジティブ | 尤度差(絶対値) |
|---|---|---|---|
| mulan | -10.83863242 | -9.33020901 | 1.50842341 |
| truman | -10.42987203 | -9.000858011 | 1.429014015 |
| worst | -8.809010658 | -10.1341868 | 1.325176141 |
| shrek | -10.87230098 | -9.598985497 | 1.273315479 |
| seagal | -9.529290176 | -10.78823673 | 1.258946555 |
| godzilla | -9.264337631 | -10.47190374 | 1.207566113 |
| flynt | -10.81220934 | -9.627421483 | 1.184787854 |
| lebowski | -10.82237984 | -9.664010458 | 1.158369383 |
| waste | -9.193245829 | -10.34277587 | 1.149530044 |
| stupid | -8.96333841 | -10.10326246 | 1.139924046 |
考察・所感
人気な映画、俳優などの固有名詞が判別に影響しているのは妥当性があると感じます。また、肯定的・否定的な形容詞も判別に影響していることが分かりました。これらの単語が判別に影響している事は、納得出来るのではないかと思います。
おわりに
単語の尤度を確認することで、どの単語が文書判別に影響しているか確認することが出来ました。いつでも理解できる内容ではないかもしれませんが、要因を確認することで求めている推定が行えているか確認することは大切だと感じました。
参考文献
ナイーブベイズの解説はこちらを参考させて頂きました。
→ナイーブベイズを用いたテキスト分類
尤度と確率の違いについてはこちらが分かりやすかったです。
→尤度とは何者なのか?
実装上出てきたスパースについてはこちらが分かりやすいです。
→scipy.sparseの内部データ構造