各社から発売され熱を帯びてきているスマートスピーカーですが、比較的安価に自作することもできます。今回はGoogle AIY Voice Kitを用いてスマートスピーカーを自作し、会議音声をクラウドにアップロードするものを作りました。その中で感じたスマートスピーカーのメリットやサービス作成における悩ましい点、今後のサービスについて感じた所を紹介します。

スマートスピーカーとは?
スマートスピーカーはマイクとスピーカーを内蔵する本体と音声アシスタント(メーカーによって呼称が異なります)で構成されます。ディスプレイやボタンなどは極力排除されており、多くは音声によって操作が行われます。各製品はハード面とソフト面で強みが異なっています。
ハード面でいうとマイクの性能があげられます。マイクは複数個搭載されている物が多く、製品によっては多人数での発言や話者の方向を検知できるなど性能に違いがあります。また、スピーカーで言うと音楽を楽しむために重低音を重視したものなど、各社力の入れ具合が異なります。
ソフト面では音声アシスタントの音声認識精度と拡張機能です。音声認識精度については各社しのぎを削り、日々性能向上に取り組まれています。また、音声認識結果から拡張機能(アプリ)を実行することが可能であり、アシスタントごとにラインナップが異なります。Alexaであれば「スキル」と呼ばれ、国内でも100社以上が265スキルが提供されているように注目度が上昇中です。
https://m.media-amazon.com/images/G/01/mobile-apps/dex/alexa/alexa-skills-kit/jp/skills/Alexa_Skills_List_1108.pdf
スマートスピーカーを自作する
Google AIY Voice Kit
Google AIY Voice Kit(以下Voice Kit)はスマートスピーカー自作キットです。「Do-it-yourself artificial intelligence」を掲げるAIY Projectの第一弾です。Voice Kit自体はマイクとスピーカー、ボタン、Raspberry Pi用アドオンボードが入っているのみで、自前でRaspberry Piを用意する必要があります。これとクラウド(GCP)で提供されている音声アシスタントを連携させることによってスマートスピーカーが完成します!
作成したもの
今回は会議室に配置する想定で、「会議音声録音・アップロード」を行ってくれるスマートスピーカーを作成しました。近年では会議内容を録音するケースが増えてきましたが、会議後に音声を録音デバイスから取り出し、指定した箇所にアップロードするのは手間です。そこで、スマートスピーカーで録音し、完了後はクラウド上のGoogle Cloud Storage(GCS)にアップロードを自動的に行なう機能を作成しました。概要図は以下です。
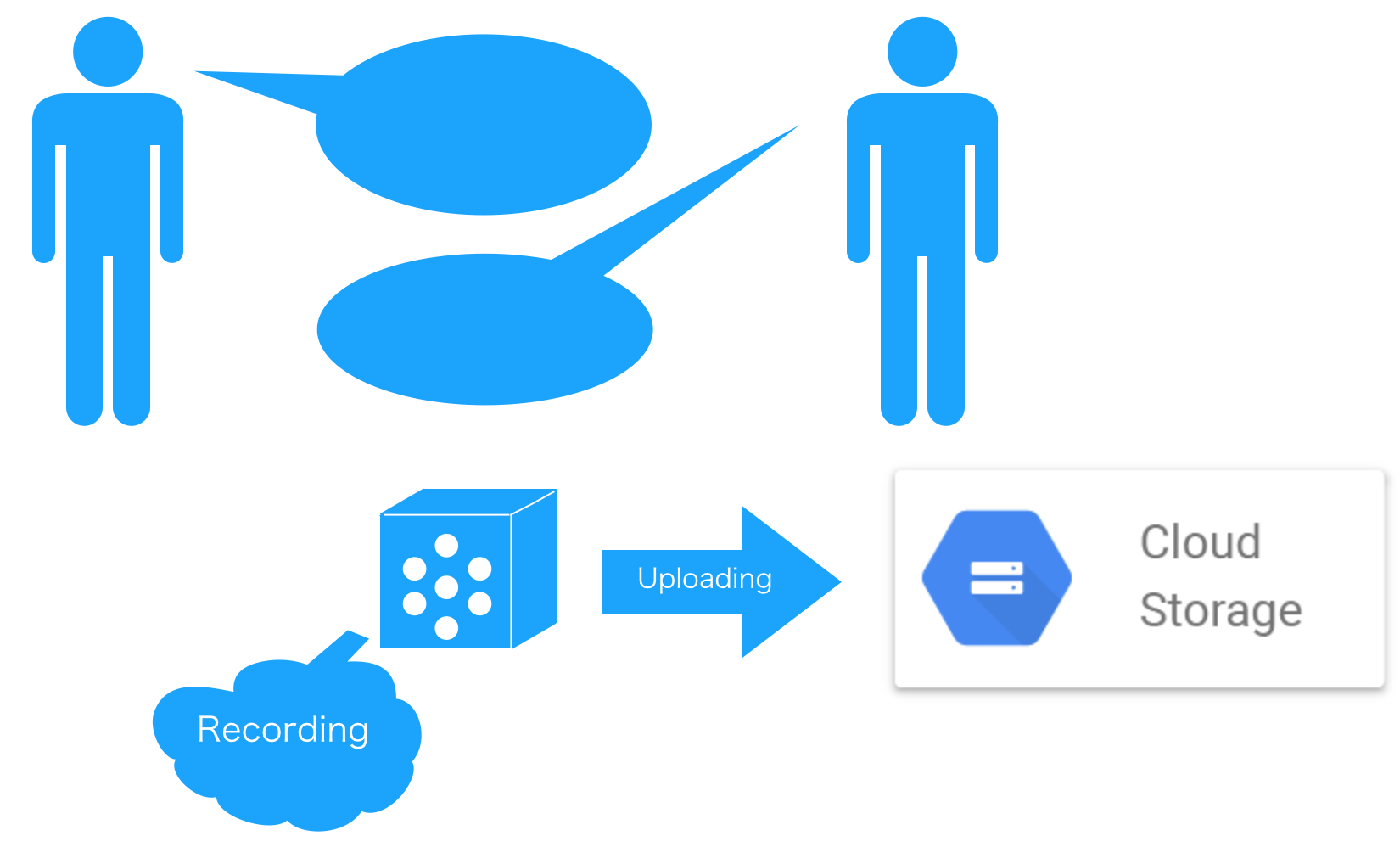
組み立ては手順通りにやっていれば躓く所なく、30分〜1時間程度で完成します。ラズパイにはVoice Kitのサンプルが含まれるImageをまるっと焼くだけでよいので簡単です。
https://aiyprojects.withgoogle.com/voice/
Voice Kitを用いる利点として、マイクやスピーカーやボタン押下時の動作、ボタン部LEDの発光などのハードウェア制御するプログラムが既に用意されています。ソフト側の開発に注力できるのは嬉しいですね。
利用方法と今後
利用方法としては本体上部のボタン押下で録音スタートし、もう一度押下すると録音終了と同時にGCSにアップロードが行われます。
実は後述のウェイクワードの問題があり、本来やりたかった音声起動をあえて実装していません(それでスマートスピーカーと言えるかは…)。また、録音完了時やアップロード完了時に音声で知らせてくれる昨日もつけたかったのですが実装できていません。
作成して感じたスマートスピーカーのメリット
日常生活に溶け込む
スマートスピーカーのメリットとして、日常生活において気軽に利用出来る点があります。基本的には部屋に配置する事が前提であるとともに、いつでもスタンバイ状態であるためさっと利用したい時にさっと利用できます。
作成して感じたスマートスピーカーの問題
ウェイクワードの問題
スマートスピーカーに処理をお願いする際はウェイクワードを呼びかける事から始まります(Googleアシスタントでいうと「OK,Google」)。製品によっては自分で変更できるものもありますが、自分で設定する場合は少し頭を悩ませてしまいます。
ウェイクワードに適する条件としては分かりやすく、誰もが知っているフレーズであるということがあります。スマートスピーカーはスクリーンやディスプレイを持っておらず、音声以外で情報を得ることができません。そのため呼び出し方を知っていなければ、ただの文鎮と化してしまうため分かりやすくしておく必要があります。(今回始めて知ったのはCortanaのウェイクワードは「コルタナさん」でした。知らなかった…)
ウェイクワードに適する条件の2点目は日常会話で使わないフレーズであることです。スマートスピーカーは起動の時を今か今かと待っています。そのためウェイクワードを一般的な単語にした場合、そのつもりがなくても雑談を捉えて、誤爆してしまう可能性があります。よって、普段使わないようなフレーズにしておかなければいけません。製品では「Hey,Siri」など「呼びかけ+製品名」で設定されていることが多いですね。
今回は見た目空ではGoogle製品とわかりづらいので、「OK,Google」と呼びかけるのではなく、ボタンにまかせてしまいました。
呼びかけるのが恥ずかしい問題
音声で制御するという行為に対して、ユーザー側の心理的障壁があります。利用してみて実感したのですが、無機物に呼びかけるのは恥ずかしいと言う気持ちが考えてた以上にありました(みなさんは人前でスマホに「Hey,Siri」と呼びかけれますか?)。ただ、はじめは奇異に見られても利用者が増えれば一般的に浸透すると思う(ハンズフリー電話など)ので、ガンガン話しかけていこうと思います!
スマートスピーカーのこれからを考えてみる
スマートスピーカーを何に利用するかはまだまだ考えられている最中であり、スマホのように万人に受け入れられるかは現時点では五分五分だと感じます。
音声のみと言う特性が利用方法に大きな制約を与えていると私は考えます。一説によると人は外部情報を8割を視覚、1割を聴覚から得ると言われたりしています。何を情報量とするかや割合の信憑性は置いておいても、音声のみであると大きく情報量が落ちるのは納得して頂けるのではないでしょうか。
その状況で適する利用法としては、短文で利用できる内容でないでしょうか。例えば検索を音声などで行った場合、検索結果を読み上げてもらっても理解出来る量は多くは無いと思います。それよりも「今日の天気予報を教えて」「晴れです」など短い答えが決まっていたり、「タクシーを呼んで」などの指示などが適していると思います。ただし、音楽などは別で感覚に訴える情報の場合は長時間でも問題ないでしょう。
もうちょっと面白い使い方ができないか、引き続きスマートスピーカーをいじりながら考えて見たいと思います。皆様も1台作って遊んでみてはいかがでしょうか。