はじめに
最近Hadoopに比べて100倍速い(?)といわれるApacheSparkが注目を集めています。
そのApacheSparkをなるべく手間をかけずにGoogleCloud上に構築する手順を解説します。
はじめにDeveloperConsoleのWeb画面上から操作できるクリックデプロイの方法を解説し、最後に同じことをコマンドラインツールで行う場合の手順も解説します。
Googleの課金可能な開発者アカウントがあることを前提にしています。
クリックデプロイ

まずはGoogle Developer Consoleを開き、デプロイと管理->クリックデプロイを選択します。
Apache Sparkは見当たりませんがApache Hadoopを選びます。
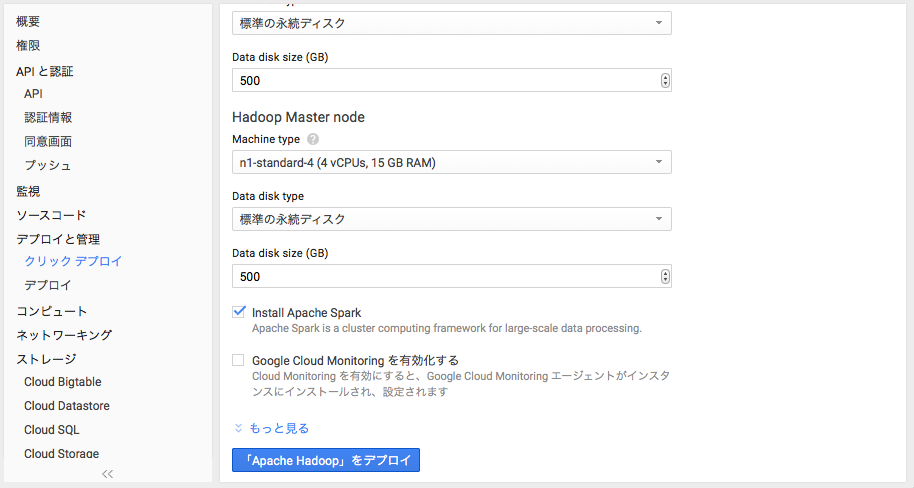
最低限必要な項目
・Cloud Storage Bucket (必須)
GoogleCloudStorageにバケットが1つもなければDeveloperConsoleの
ストレージ->Cloud Storage->ストレージブラウザ
から事前に作成しておきます。
Spark実行時にデフォルトの入力ファイルの読み込み先になり相対パスで入力ファイルを指定できます。ただ、あくまでデフォルトなのでSpark実行時にsc.textFile("gs://....")とすればどのバケットからも読めるのであまり悩まず決めましょう。
またsc.textFile("hdfs://....")とすれば公式サンプルのようにhdfsからも読めます。
・Install Apache Spark
Sparkインストールするので要チェック。
ちょっと検討してもいい項目
・Zone
usのほうがインスタンスの時間単価は安いが日本からはasiaのほうがレスポンス速いと思われる。
デフォルトのマシンタイプのインスタンス使用料は時間あたりで以下になります。
us : $0.252、それ以外 : $0.276
・Hadoop version
デフォルト1系だが2系のほうがいいかも。
・Node count
デフォルトの2だとmaster1台、worker2台の3台構成になります。
デプロイ完了
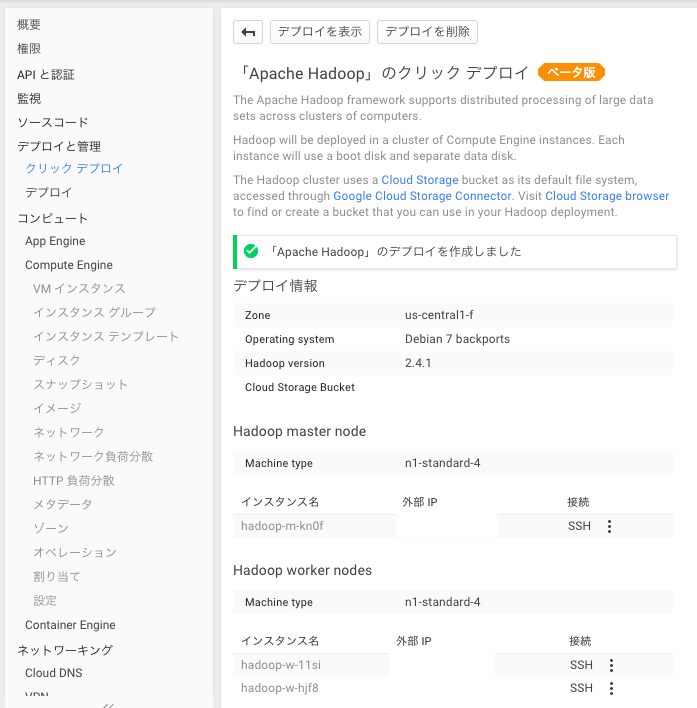
Spark対話シェルで動作確認
ssh接続(簡易版)
DeveloperConsoleのコンピュート->Compute Engine->VM インスタンス

SSHボタンを押すとブラウザからSSHと同様の操作ができます。通常のSSHで接続するにはgcloudコマンドでいったん認証する必要があるので別途「コマンドラインツールからデプロイ」で説明します。
hadoopというユーザのホームディレクトリ下にもろもろデプロイされているのでユーザを変えます。
$ sudo su - hadoop
どのようなディレクトリが置かれているか確認しておきます。
$ ls -l
hadoop-2.4.1.tar.gz
hadoop-install
scala-2.10.3.tgz
scala-install
spark-1.1.0-bin-hadoop2.4.tgz
spark-install
*.tar.gzや*.tgzは入力補完にひっかかって邪魔なので削除するかバックアップディレクトリを作って移動しておきましょう。
spark-shell実行
Sparkの対話式の実行環境であるspark-shellを起動します。
$ ~/spark-install/bin/spark-shell
わらわら起動ログが出てscala>が表示されれば入力可能です。(一度Enter押さないと出ないかもしれません。)
ファイルの行数をcountしてみる
scala> val text = sc.textFile("gs://<GCS上にあるファイルのパス>")
scala> text.count()
res0: Long = 406
406が計算結果の行数になります。
これで準備は整いました。Spark環境を楽しみましょう!
その後
管理画面
Sparkの管理用Web画面でmasterが認識してるworkerを確認したり実行中のJobを確認したりできます。
そのためにはネットワークの設定からポートを開ける必要があります。
Developer Consoleのコンピュート->Compute Engine->ネットワーク
詳しくは解説しませんがある程度アクセス元のIPを絞ったうえで以下のポートを開けるとよいと思います。
8080→http:<masterの外部IP>:8080でworkerの確認、実行中のJobの確認ができる。
4040→http:<masterの外部IP>:4040でSparkジョブの実行状況の詳細が見れる。
50070→http:<masterの外部IP>:50070でHadoopの管理画面が見れる。
インスタンスの停止と起動
Developer Consoleのコンピュート->Compute Engine->VM インスタンス
からインスタンスを選んで停止・起動ができます。
使わない間は停止しておくとコスパが高まるでしょう。
ちなみにインスタンスを再起動すると外部IPは変わります。
現状クリックデプロイしたインスタンスは再起動するとsparkのデーモンプロセスが自動で起動しないようなので以下のように手動で起動する必要があります。(workerも起動します)
$ ~/spark-install/sbin/start-all.sh
コマンドラインツール(bdutil)からデプロイ
bdutilからのデプロイはセットアップ手間はかかりますがクリックデプロイに比べて以下のメリットがあります。
■新しいバージョンのSparkが利用できる
コマンドラインからのデプロイのほうが新しいバージョンの反映が早いようです。
bdutilからデプロイされるSparkのバージョンは以下のあたりを見るとわかります。
https://github.com/GoogleCloudPlatform/bdutil/blob/master/extensions/spark/spark_env.sh#L28
■Sparkクラスタを何個でもデプロイできる
クリックデプロイは制約で一度に1つのSparkクラスタしか作れない。いったん「デプロイを解除」でインスタンスを削除しなければならない。
■コマンドラインからインスタンスの起動停止ができる
インストール
GoogleCloudSDKとbdutilを以下からダウンロード、インストールします。
https://cloud.google.com/hadoop/downloads
gcloudを認証
gcloud auth login
ブラウザで指定のURL開いて認証して表示されるので、コンソールに戻って認証キーを入力します。
gsutilを認証
gsutil config
また認証用のURLが表示されるのでブラウザで認証します。
認証コードを入力し、その後プロジェクトIDの入力を求められます。
これをやっておかないとデプロイ時にバケットが見れなくエラーになります。
デプロイ
bdutilをインストールしたディレクトリに移動して
$ ./bdutil -p <プロジェクトID> -b <バケット名> -n 2 -P <インスタンスにつける名前> --env_var_files hadoop2_env.sh,extensions/spark/spark_env.sh deploy
デプロイ自体はこれだけです。
gcloudコマンドを使ったSSH接続

・・・(縦)のボタンを押してgcloud コマンドを表示を選択。
gcloud compute --project <プロジェクトID> ssh --zone <ゾーン> <インスタンス名>
のようなコマンドが表示されるのでコンソールに貼り付けて実行するとSSHで接続できます。
以上となります。