ADVENTARから25日分の記事情報を取得して、アプリに表示したいというケースがありました。
とここで悲報ですが、ADVENTARには公式で公開されているAPIがありません。。なのでスクレイピングしました。普段HTMLをあまり見ていないのと、スクレイピング自体が初めてだったこともあってなかなか大変でした。 ![]()
せっかく頑張ったので記録を残しておこうと思います。
当然のことですが、HTMLの構造が変わったら使えなくなる可能性が高いので、その点ご了承ください。 ![]()
環境
- Xcode14.2
- SwiftSoup2.4.3
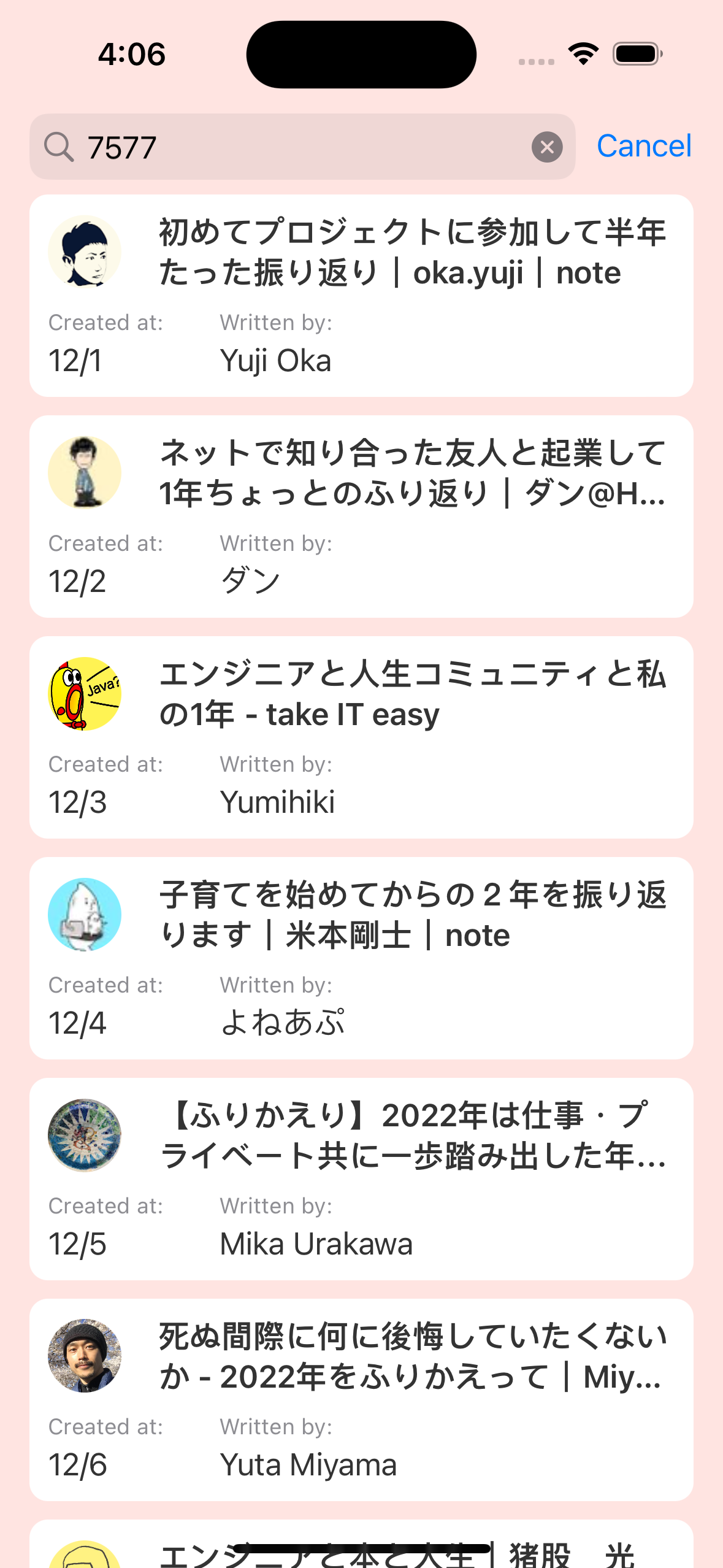
完成したもの
以下のデータを取得します。タイトルが設定されていなかった場合は、コメントをタイトルとして使用します。
- 日付
- 投稿者名
- 投稿者のプロフィール画像
- 記事タイトル
- コメント
- 記事URL
実装
前述したようにADVENTARにはAPIがないので、SwiftSoupというライブラリを使ってHTMLをパースすることにしました。流れとしては以下です。
- ADVENTARの特定のURLからHTMLを取得する(今回は「https://adventar.org/calendars/7577 」を使いました)
- SwiftSoupを使って頑張ってパースする
2つ目の頑張ってパースするところについて少し説明します。
まず取得したString文字列を、SwiftSoupが提供しているDocument型に変換します。
以下はコードの一部を取り出していますが、tryがついていることからもわかるように例外が投げられることがありますので、実際に書くときはdo catchで囲う必要があります。
let doc: Document = try SwiftSoup.parse(htmlString)
この後は、HTMLの要素を指定して、欲しいデータを取得していくことになります。
がその前に、パースしたいHTMLの構造をよく見て、どの要素に欲しいデータが入っているかを特定します。
まず今回はADVENTARのカレンダー表示の下にあるリスト?からデータを取得することにしました。
構造としては、EntryListというクラスのdivタグの中に、itemクラスのliタグがずらっと並んでいることがわかります。
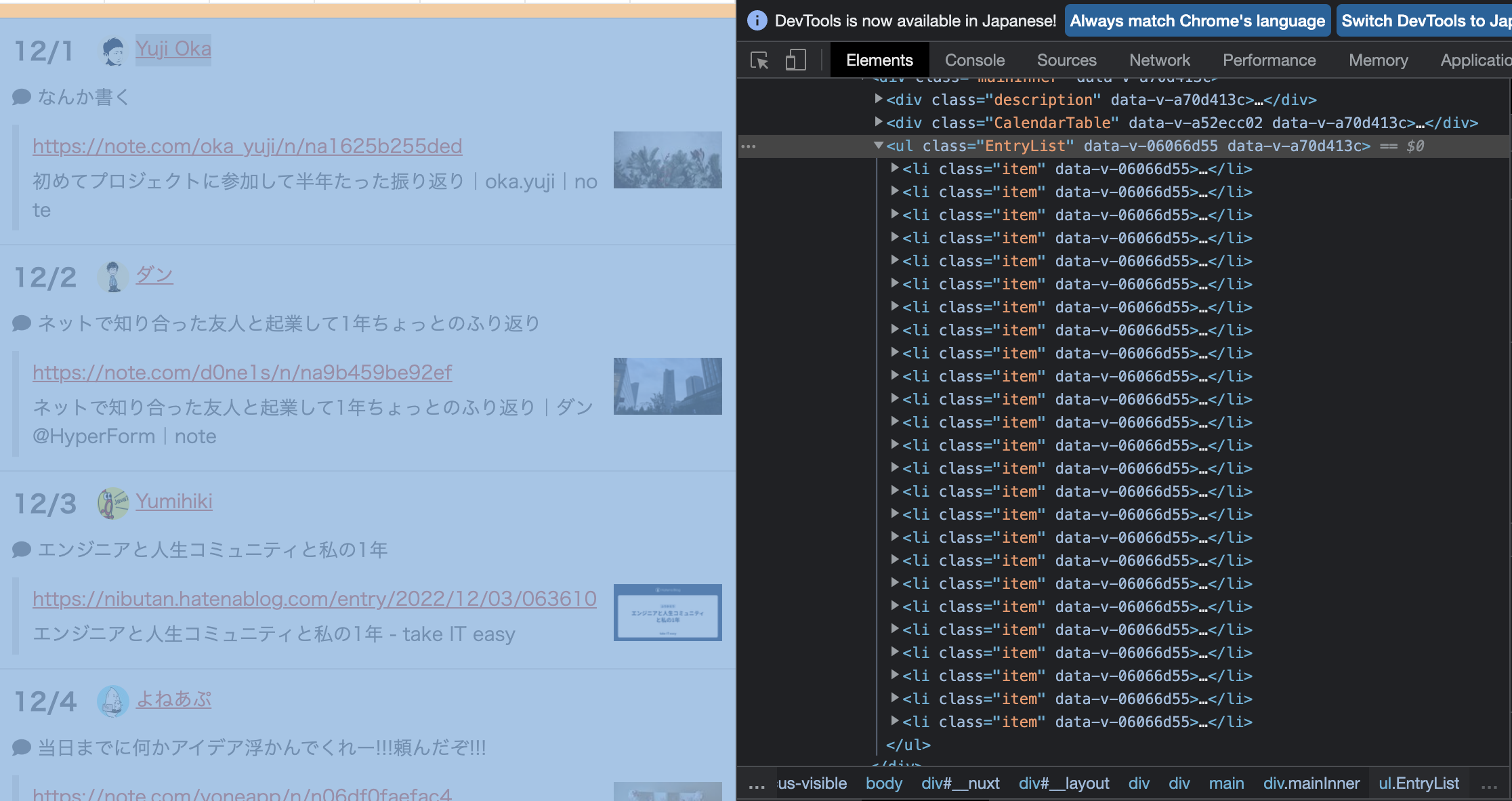
これを取得するためには、これもSwiftSoupが提供しているElements.select(_ selector: String)メソッドを使います。
これは引数にStringでセレクターを指定することで、該当のデータを取得します。
let entries = try doc.select("ul.EntryList").select("li.item")
entriesはこれもSwiftSoupが提供するElements型を返します。
ここからは、日付や投稿者名など一つ一つの投稿情報を取得していきます。
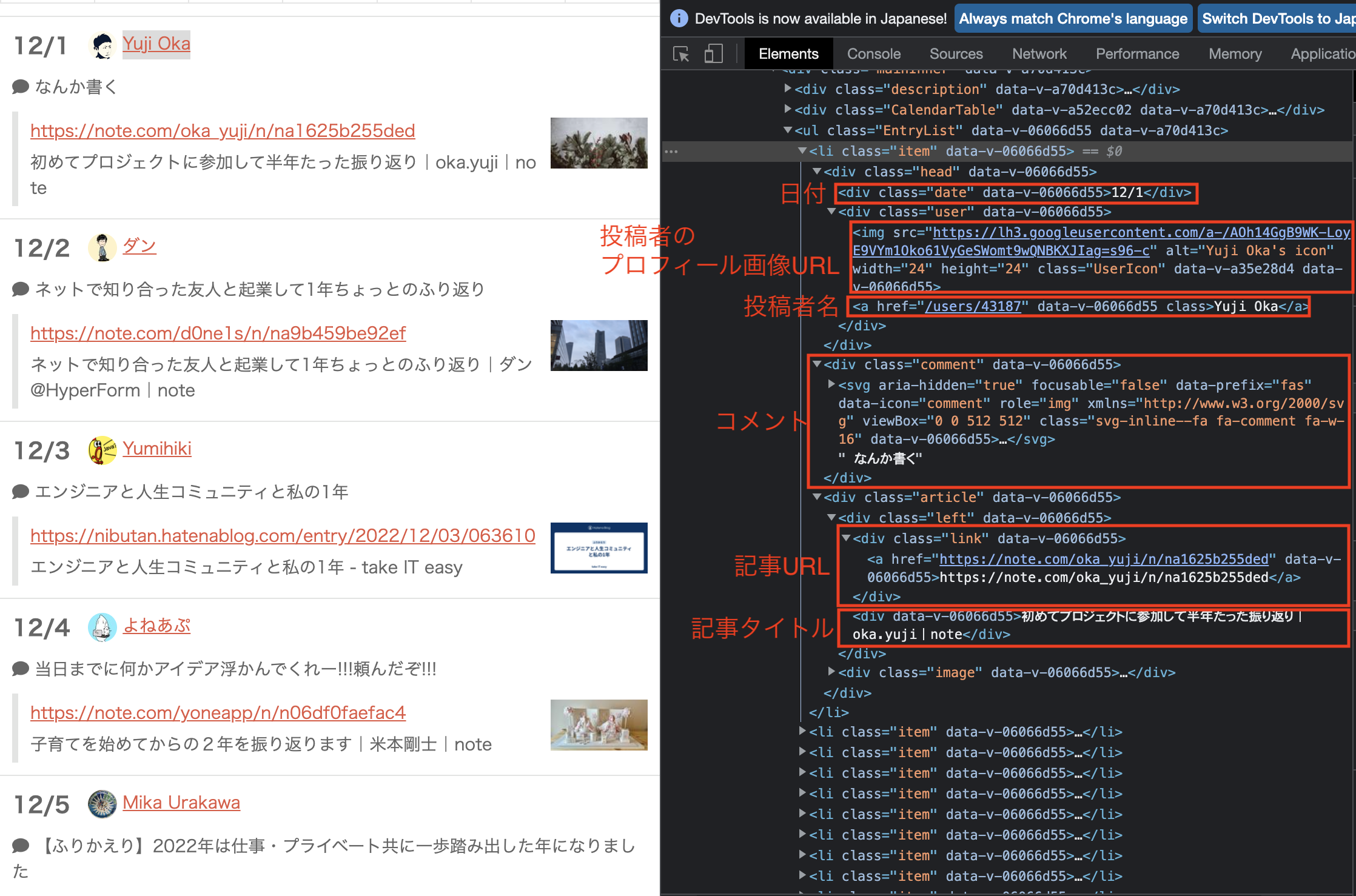
基本的には先ほど使った、Elements.select(_ selector: String)メソッドと要素のテキストを返すElement.text()メソッド、属性を指定するNode.attr(_ String key)メソッドを使いました。
entryIndexは、entriesの要素番号が入ります。(今回は0~24)
// 日付
let date = try entries[safe: entryIndex]?.select("div.date").text()
// 投稿者名
let name = try entries[safe: entryIndex]?.select("div.user").text()
// 記事URL
let url = try entries[safe: entryIndex]?.select("div.article").select("div.link").first()?.text()
// 投稿者プロフィール画像URL
let iconImage = try entries[safe: entryIndex]?.select("div.user").select("img").attr("src")
// コメント
let comment = try entries[safe: entryIndex]?.select("div.comment").text()
タイトルだけ、divタグを特定しやすいクラスが設定されておらず、取得の仕方を少し工夫しました。
構成としてはdivタグのleftクラスに2つのdivタグがあり、その2つ目が取得したいタイトルです。
// 1. divタグのleftを取得する
let leftHTMLElements = try entries[safe: entryIndex]?.select("div.left")
// 2. Stringに変換する
let leftHTMLString = try leftHTMLElements?.html() ?? ""
// 3. StringをDocument型に変換し、divタグを指定して、2つ目の要素を取得する -> それがタイトル
try SwiftSoup.parse(leftHTMLString).select("div")[safe: 1]?.text()
もっといいやり方があるかもしれないのですが、なかなかできなかった結果、こうなりました・・・(誰か教えて。。)
おわり
最初にも書いたように、HTMLの構造が変わったら役に立たないコードなのですが、
スクレイピングって大変だ・・・ということを実感できたのでいいかなと思いました。 ![]()
SwiftSoupは使いやすかったです。
ADVENTARさん、公開APIお待ちしております。