はじめに
機械学習コミュニティ LAIME に所属している kami です。
先日、Kaggle の BirdCLEF2021 (鳥コンペ) にLAIMEのメンバーとチームで出場し優勝しました。
この記事では、優勝解法についての詳細や、私達がどのようにこのコンテストに取り組んだかを紹介しようかと思います。
英語での解法説明はKaggleのディスカッションにまとめてあります。
コードはGithubにあげてあります。
コンペ概要や他の上位解法についてはチームメイトがスライドを作ってくれました。
BirdCLEF2021まとめ を御覧ください。
この記事で書くこと
- 鳥コンペの概要
- 優勝解法の詳細
- コンペにどう取り組んだか
鳥コンペについて
簡単な説明
BirdCLEF2021は、録音から鳥の鳴き声を識別するコンテストです。
簡単にコントストについてまとめると以下のような形です。
- 鳴き声から397種類の鳥を判断
- そもそも鳥が鳴いていないことがある(nocall)
- 397+1種類のマルチラベル分類
データと評価について
学習用データの多くは、 https://www.xeno-canto.org にユーザーによってアップロードされた397種類の鳥の鳴き声の録音とメタデータで構成されています。データセットの特殊性から以下のような難しさがあります。
- ラベルが不完全なため、短く分割したフレーム単位ではprimaryとsecondaryのどちらが鳴いているか不明
- 付与されているラベル自体が間違っている場合も考えられる.
- 鳥が鳴いているか否かという尺度が不明瞭
このコンテストの参加者は、5秒間のフレームの中で、397種類の鳥のうち、どの鳥が鳴いていて、どの鳥が鳴いていないかを正確に予測する必要があります。
【Kaggle挑戦記】鳥コンペ2(BirdCLEF 2021)銅メダル振り返り【#8】の図がわかりやすかったのでこちらも確認してみてください。
評価は行ごとの F1 スコアの平均で計算されます。
F1 スコアの定義は以下の通りです。
\text{F1} = \frac{2}{\text{recall}^{-1} + \text{precision}^{-1}} = \frac{\text{tp}}{\text{tp}+1/2(\text{fp}+\text{fn})}
コンテストの終了時までは、テストデータの35%を用いて計算されたスコア(public score)のみが表示され、残りの65%のスコア(private score)は隠されていました。最終的な順位は private score で確定します。
私達の解法
概要
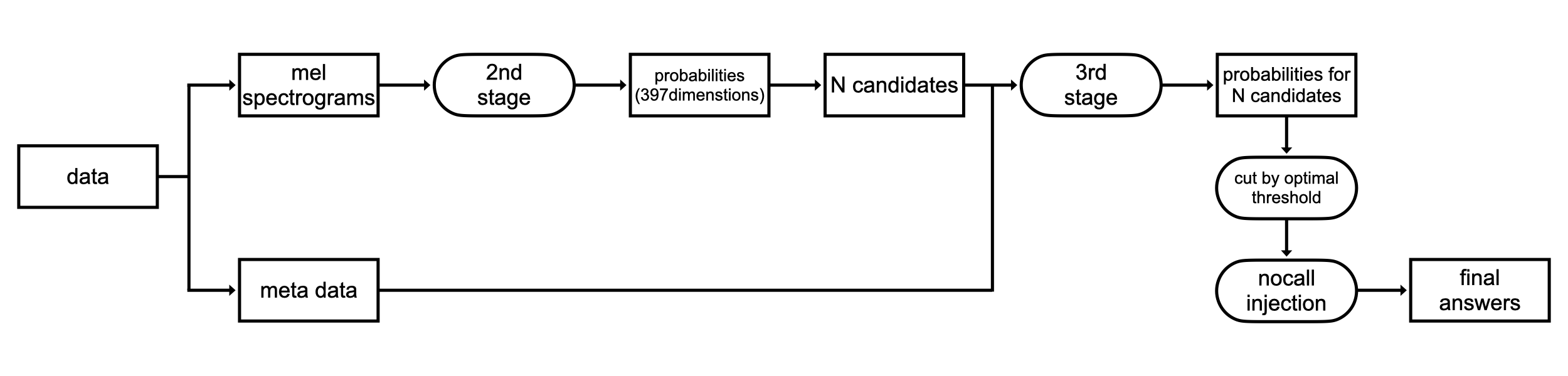
大きくわけて3つの段階があります。前処理と後処理を入れると5つです。
- 前処理:事前に音源をメルスペクトログラムに変換しておきます
- 第1ステージ:外部データのメルスペクトログラムから鳥が鳴いているかどうかの2値分類をCNNで行います
- 第2ステージ:メルスペクトログラムから397+1のマルチラベル分類をCNNで行います
- 第3ステージ:第2ステージの結果から可能性のある鳥を一定数抽出し、メタデータと合わせてテーブルデータに変換、LightGBMで学習します
- 後処理:nocall と判断する閾値を最適化。また鳥と nocall を混ぜてスコア向上させる nocall injection を行います
推論時のパイプラインは以下の通りです。第1ステージでの結果は学習時のみに使われます。
データセット・前処理
学習データ
- train_short_audio:ラベルはオーディオ単位でしか与えられていません。また、音源についてのメタ情報として、録音された緯度経度、日付などの情報が含まれています。オーディオ内で主に出現する鳥のラベル(primary label) はすべてのオーディオに対して与えられているものの、オーディオ内に出現し得る他の鳥についてのラベル (secondary label) は欠損している可能性があります。また、ユーザーによってアップロードされたデータのため、そもそもラベル自体が間違っている可能性もあります。
- train_soundscapes:10分のファイルとして5秒ごとにアノテーションがなされています。 これはtest 用のオーディオと同様の形式で20files与えられています。それぞれのファイルは2つの地域で録音されたものであり、録音時の位置や日付がわかる様になっています。
テストデータ
-
test_soundscapes:32 kHzでサンプリングされた10分のオーディオからなるファイルが合計80あります。それぞれのファイルは、train_soundscapesで録音された2つの地域を含む、4つの地域で録音されたものであり、録音時の位置や日付がわかるようになっています。参加者はこのオーディオデータに対して、5秒毎に区切ったフレーム内でどんな鳥が鳴いたのかを予測します。
コンテストはこのデータに対するモデルの予測精度で評価されます。
外部データ
BirdCLEF2021で提供されたデータ以外を用いることでさらなる精度向上が図れるため追加で2つの外部データを用いました。
- freefield1010:元々公開されていた10秒ごとのオーディオデータ7690本についているアノテーションではなく、Bird Audio Detection challengeで改めて与えられたアノテーションを用いました。鳥の鳴き声がないデータは5755本、鳥の鳴き声があるデータは1935本に分けられ、10秒のオーディオごとにラベルが与えられます。
- BirdCLEF2020のvalidation data:合計で2時間分のオーディオデータがありましたが、5秒毎に分割して鳥の鳴き声が出現しないフレームのみを用いました。
前処理
すべてのデータセットはそれぞれ5,7,10秒のセグメントに分割され、テストデータを除いてメルスペクトログラムに変換されました。
これは元々の音源に対して data augmentation ができないという欠点がありますが、学習時にメルスペクトログラムに変換するコストが削減できるという点で優れており、高速な学習が実現できます。
フーリエ変換・スペクトログラム・メルスペクトログラムについてはメルスペクトログラムを理解するを御覧ください。
参考として、スペクトログラムの例を載せておきます。BirdCLEF2021: Processing audio dataからの画像です。1枚目は音源そのままを可視化した時、2枚めはフーリエ変換を施してスペクトログラムに変換した時です。
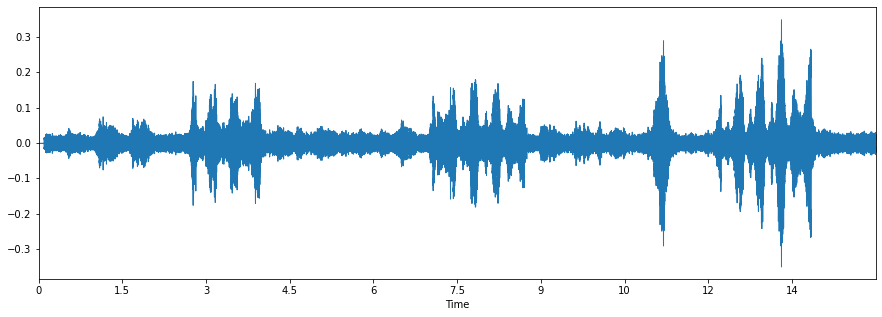
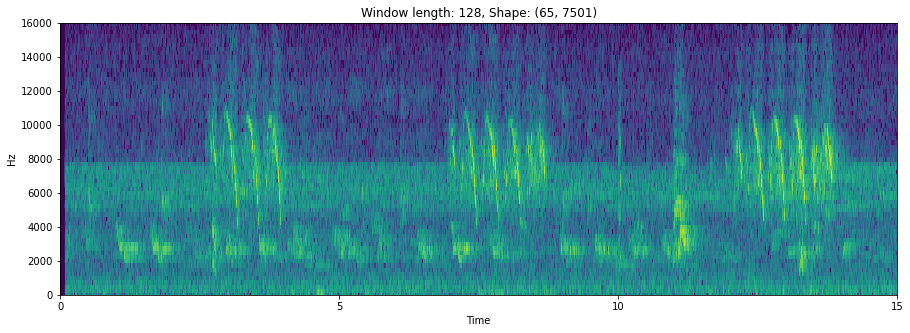
このように、予め画像として変換しておくことで、通常のCNNを用いることができます。
各データは、各ステージで以下のように使用されます。
第1ステージ
外部データのメルスペクトログラムから鳥が鳴いているかどうかの2値分類をCNNで行います。
ここではCNNベースのモデルの一種である Resnext50 をbackboneとしてnocall detectorを作成します。 Nocall detectorは以下の2つの用途で使用されます。
- 第2ステージの学習時において、鳥が鳴いていないと予測したフレームのラベルを小さく重み付けする
- 第3ステージの学習時において、学習時のラベル作成に使用する
Birdclef2021で与えられたデータの内容が十分でなかったため、nocall detectorの作成には freefield1010 を使用しました。音源は10秒ごとに与えられていましたが、音声開始から7秒間の音源のみを用います。これは、第2ステージや第3ステージで学習に使用するtrain_short_audioは7秒ごとに区切って使用するためです。
データセットは予め画像に変換していたため、ノイズの付加など通常の音声認識で使われるデータオーグメンテーションを使用することが難しくなりました。しかし、フリップ、画像に対する通常のオーグメンテーション(反転、正規化、Decrease Jpeg, WebP compression of an image.) を用いて汎化性能を高めました.
1つのモデルのトレーニングは P100 で1エポック90s程度かかりました。ラベルが均等になるように5つにデータ分割して交差検証を行ったところ、平均正解率は0.89857でした。
第2ステージ
変換されたメルスペクトログラムに対してCNNベースのResnest50 を用いて397+1のマルチラベル分類をCNNで行います。
データについて
学習データは、7秒ごとに区切られたtrain_short_audioを用います。長いaudioの場合は、最初から10フレーム目までのみを用います。また、いくつかのモデルについては、freefield1010, BirdCLEF2020 の validation dataも用います。これらのデータは、nocallのデータのみを用いて、ターゲットの397次元はすべて0とします。
ここでもデータセットを予め画像に変換していたので、データオーグメンテーションとして mixup を行います。これにより汎化性能を高めるとともに、複数の鳥が同時に鳴くことがあるということをさらに良く認識できるようになります。
ラベルについて
第1ステージで作成したnocall detectorを用いて本ステージの学習に使用するデータに対してラベルの修正を行います。具体的には各フレームに対して第1ステージの出力値(0に近いほど鳥は鳴いておらず、1に近いほど何らかの鳥が鳴いている可能性が高い)を掛け、鳥が鳴いていないクリップの重みが小さくなるように設定します。さらに、secondary labelsがあるデータセットについては、nocall detector の予測値の0.6倍の値をターゲットとして使用することにします。これは secondary labels の鳥の出現頻度は primary label の鳥よりも低いと考えられるため、オーディオ全体を通して出現しない可能性があるためです。
その他
ラベルスムージングを行い、ターゲットの値は最大で0.995、 最低で0.0025になるように調整されます。
音源を録音する機材特有のノイズにオーバーフィットするのを避けるため、一部のモデルでは、データを録音したauthorごとに分割して、training data と validation data に共通して現れないようにクロスバリデーションを行います。
10個のResnest50について学習しました。
それぞれのモデルについて、3分探索によって閾値を決定し、train_soundscapesで検証時のF1スコアが最適となるモデルを最終提出で利用しました。P100やV100のGPUを用いて学習を行いました。Resnest50については、P100では1エポック当たり6〜7分で学習ができます。コンテストでの最終提出には含めていませんが、第2ステージではResnest26dのほうが性能がよく、学習時間もP100では1エポック当たり4-5分と短くて済みます。
このステージでは train_soundscapesに対して予測し、row-wise F1 score が最も高かいepoch時のモデルを使用します。 予測の方法としては、397次元の各鳥に対する予測確率に対して閾値を設定し、閾値以上の確率値がある鳥を予測し、一つもない場合は nocallとしました。閾値の設定方法としては、3分探索を用いますが、これの詳細については後処理の部分で述べます。
もともとラベルがweakなデータセットであるため、第1ステージのラベル修正だけでは不十分です。第2ステージではまだ以下のような課題があります。
- そのフレームでどの鳥が鳴いているか不明なこと (primary or secondary labels)
- そのフレームで鳥が鳴いているかどうか確率的にしか不明なこと
ノイズをある程度軽減させつつ、どの鳥が鳴いているかを高い精度で割り出す仕組みが必要であったため、第2ステージの予測結果を選別するために第3ステージを用います。
- 第3ステージ:第2ステージの結果から可能性のある鳥を一定数抽出し、メタデータと合わせてテーブルデータに変換、LightGBMで学習します
- 後処理:nocall と判断する閾値を最適化。また鳥と nocall を混ぜてスコア向上させる nocall injection を行います
第3ステージ
このステージでは第2ステージの結果を踏まえて各セグメントにおいて鳴いている可能性の高い上位n種の鳥を抽出し、鳴き声以外の情報(日付,緯度,経度,前後のセグメントで鳥が鳴いているか)などの情報も合わせた上で 損失をbinary logistic lossとしてLightGBMで学習させ、2値分類を行います。出力は0に近いほど対象のセグメントにおいて対象の鳥種が鳴いている可能性が低く、1に近いほど高いというものです。
また、メタデータを用いて新たな特徴量を複数生成しました。
第2ステージでのノイズの多いラベルという問題を解決するため、以下の「正解を含む集合」 と 「候補の集合」 との積集合が正解となる問題を作った。これにより、画像特徴量を用いた第2ステージのモデルの特性を活かしつつ高い精度で正解となるラベルが自動で付けられるタスクへ変換させた.
- 正解を含む集合: 鳴いていると判断したフレームなら primary label & secondary labels。鳴いていないと判断したフレームなら
- 候補となる集合: メルスペクトログラムから第2ステージのモデルで予測した各鳥の鳴く確率の上位n件(n=5を採用)
候補と正解どちらにも共通することは稀であるという条件を生かして、この手法で高い精度で自動アノテーションができるようになった
このような数秒間隔に分割されたフレームごとのテーブルデータに変換することで,クリップ内の時系列情報や季節性,地域性など様々な情報を加味した予測が可能となります。
学習時には train_short_audioの検証用データに対する第2ステージの推論結果と、メタデータを用いました。候補抽出時には、第2ステージでの397種類の鳥に対する推論結果から予測確率が高かった上位5件を選びました。
推論時は 精度向上のため10のモデルの単純平均を用いました。テーブルデータの学習も含めておよそ15分で提出が完了します.
特徴量
作成した特徴量は以下の通りです。
- “year”: オーディオが録音された年
- “month”: オーディオが録音された月
- “sum_prob”: フレームに対する397次元の確率値の合計
- “mean_prob”: フレームに対する397次元の確率値の平均
- “max_prob”: フレームに対する397次元の確率値の最大値
- “prev_prob” ~ “prev6_prob”: 前n個のフレームでの、候補の鳥の確率値
- “prob”: 対象となるフレームでの候補の鳥に対する確率値
- “next_prob” ~ “next6_prob”: 後n個のフレームでの、候補の鳥の確率値
- “rank”: 対象となる鳥が、そのフレームで397個中何番目に大きい確率値を持つか
- “latitude”, “longitude”:録音された時の緯度経度
- “bird_id”: 397種類の鳥のうちどれか
- “seconds”: 何秒目のフレームか
- “num_appear”: train_short_audio でその鳥がprimary label となったファイル数
- “site_num_appear”: その地域で train_short_audio に含まれる鳥が何回出現したか
- “site_appear_ratio”:site_num_appear/num_appear
- “prob_diff”: 3つ分のフレームに対する確率値の平均と、prob の差
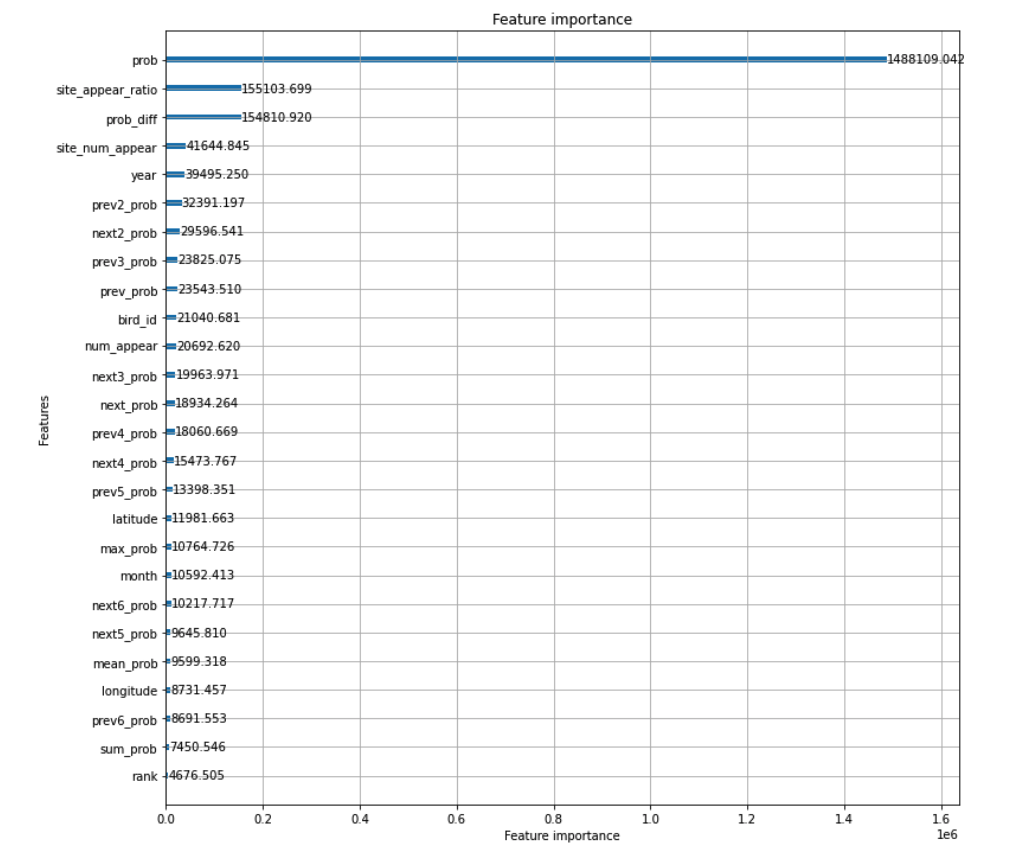
以下はLightGBMから得られた特徴量の重要度です。
後処理
第3ステージの二値分類の終了後、三分探索により最適な閾値を決定し、その後nocallと鳥のラベルを混ぜることで曖昧さを残しつつスコアを向上させるnocall injectionを行います。
閾値最適化:第3ステージでの2値分類の予測確率に対して閾値を設定します。閾値以上の確率値を持つ候補は最終出力に入れ、そのフレームに対してどれも入らなければnocallとします。
スコアが閾値に対して凸関数になることを仮定し、3分探索によって最もスコアが高くなる閾値にします。1回のスコア計算ごとに最適な閾値が存在する範囲が2/3倍になっていくので、数十回程度のスコア計算を行えば、ほぼ最適な閾値を決定することが可能になります。この閾値は、train_soundscapesを用いて最適なものを計算し、同じ値をtest_soundscapesの推論時に使います。
nocall injection.: 閾値の決定をしたあとは、nocallにならなかったフレームに対して、nocallを追加で付与するかを決定します。具体的には、閾値の設定により最終出力に含めることに決めた鳥について、その予測確率の合計値が低い行についてnocall を付加します。これにより以下の2つのメリットがあります。
- 第3ステージでの予測確率が高くなかったものを曖昧なまま予測できる
- row-wise micro average F1 score の性質上、nocall と鳥のラベルを混ぜたほうがスコアが上がることがある
実装としては、これも凸性を仮定して3分探索を行います。
閾値を最適化した時の検証スコアは0.833286、nocall injectionは0.837063
最終提出のスコアは、public test set で 0.7620、 private test set で 0.6932 を達成しました。
議論・その他
優勝という結果になりましたが、まだ精度向上の余地があると思います。
例えば、第2ステージについては、時間的な問題でResnest26d などの別の高精度なモデルを組み込むことができませんでした。 また、モデルもResnest50のみを用いており、別のモデルをアンサンブルに用いることができていないため、改善の余地があります。
他のチームにくらべて、マルチラベル学習での性能がそこまで高くなかったのではないかと考えています。
また、第3ステージについては、学習と推論時で使用する第2ステージのモデルが異なっています。つまり、train_short_audioの確率値の推論に用いたモデルは一つだけであり、train_soundscapesの確率値の推論に用いたモデルは10個です。これらが一致していないことにより、第3ステージの学習データと推論データに違いが生じる可能性があるため、これらを統一することでさらなる精度向上の可能性があります。
候補抽出時も、それぞれのセグメントに対して予測確率が高かった上位5件を抽出するというのは、それぞれのセグメントにおいて鳥の出現しやすさが異なる点が考慮されていません。鳥が多く出現しそうなセグメントでは多くの鳥を候補にあげ、そうではないセグメントは少なめに候補抽出をするといった工夫が可能です。
特徴量エンジニアリングについても改善の余地があります。例えば、鳥同士の相互作用(共起)などもあるので、一緒に鳴きやすい鳥や、共生している鳥などの関連する情報を特徴量として新たに加えることなどが考えらます。
コンペにどう取り組んだか
今回は3週間という短い参加期間でした。コンペ全体を通してどのように取り組んできたのかを一つのケースとして紹介します。
はじめから優勝を目指して参加していたわけではなく、当初は金メダル獲得による Kaggle Competition Master への昇格を狙って参加していました。
チームでの取り組み
今回はチームでの取り組みがある程度うまくいったのが大きかったです。
使用したツールは以下のものです。
- Gather town:アバターを使ったミーティングツール。おすすめ
- Slack
- Github
基本的には、
- アイデアをすぐにシェア
- 疑問点をすぐに相談
- チームメンバーの作業時間の確保
という形です。可能な限りGatherにログインして作業するというのを3週間続けました。
作業は、最初はそれぞれでやっていましたが、後半は一つのパイプラインをみんなで改善していました。Githubのmasterを最新コードとして、改善したらプルリクエストを送るのを繰り返す形です。
今考えると、これは GatherやSlackなどで高頻度にコミュニケーションが取れる状況だったからこそ、うまくいったのかなと思います。
その他、金メダルを目指した取り組み
- 過疎っているコンペを狙う:なるべく競合が少ないコンテストに参加してゴールドを狙うことにしました。
- 毎日限界までサブミット:BirdCLEF 2021 は一日の提出上限が2サブまででした。他のコンペを見ても、上位陣はほぼ毎日限界近くまでサブミットしていたようです。私達も毎日2回サブミットする(くらい実験する)ことを目標にしていました。
コンペ後半になるにつれて金メダル圏内に入れるスコアが上がっていくので、スコアを目標にするのはあまり良くないかもしれません。
私達も最初は金メダル圏内を目指していましたが、賞金圏内を目指すくらいの勢いがないとだめかもしれないと途中で思いました(実際には Public ではゴールド圏内にも入れていなかったのですが)。