いんとろだくしょん
こんにちは、かめねこです。
この記事は、Kubernetes Advent Calendar 2019の13日目の記事です。
今回は、Kubernetesのアドベントカレンダーということですが、私はkubectl get podしかできないよわよわなので、Prometheusの話をしたいと思います。
ただ、単にPrometheusの話をしてもしょうがないので、今回はPrometheusをKubernetes上で稼働させるためにおすすめな、Prometheus Operatorをご紹介します。
Prometheus Operatorとは?
PrometheusOperatorはその名の通り、PrometheusのOperatorです。
coreos/prometheus-operator - github.com
Operatorが何なのか分からない方は安心してください。私もOperatorはわかりません。
しかし、この広大なインターネット上には多くの資料があります。そう、例えばこんなのとか。
Operator でどう変わる? これからのデータベース運用 / cndt2019_k8s_operator - Speaker Deck
サイバーエージェントの @yukirii さんの素晴らしいスライドです。めっちゃわかりやすくて大好きです。これを見ればOperatorも完全に理解できますね。
PrometheusOperatorとは?
さて、Operatorは↑のスライドを読んで頂くとして、PrometheusOperatorですよね。
PrometheusOperatorは、2016年にCoreOSによってリリースされました。Kubernetes上でPrometheusを実行するためのいくつかの機能を提供してくれます。例えば次のような。
- PrometheusやAlertManagerの作成や冗長化などを自動で行う
- Prometheusのバージョンやデータ永続化、ReplicaなどをKubernetes Likeに簡単に定義することができる
-
ServiceMonitorを使うことで、ラベルを定義するだけで簡単にPodやServiceのScrapeを追加する
他にもいくつかの機能がありますが、主に上記のような感じです。
特に、ServiceMonitorが非常に強力で、Prometheusを難しくしているScrapeConfigを簡単にしてくれます。
また、ServiceMonitorに集約させることで、煩雑になりがちなScrapeConfigを統一的かつシンプルなフォーマットにまとめてくれます。
PrometheusOperatorのArchitecture
PrometheusOperatorのArchitectureは比較的シンプルです。
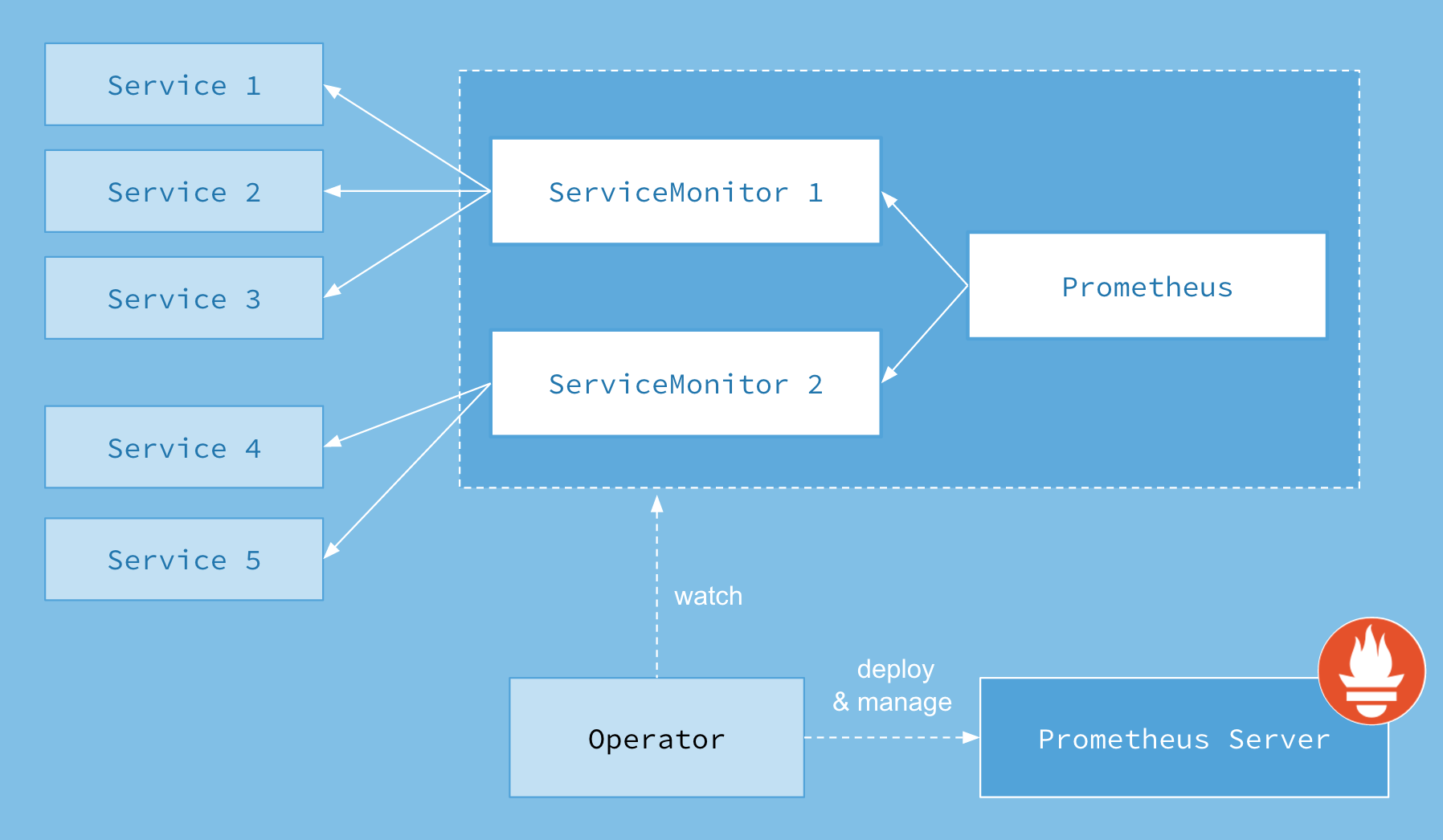
https://github.com/coreos/prometheus-operator/blob/master/Documentation/user-guides/images/architecture.png
PrometheusOperatorをデプロイすることによって、定義されたReplica数の数だけPrometheusServerが展開されます。また、併せてAlertManagerも展開されます。
更に、Operatorによって定義されたCRDのServiceMonitorが定義され、ServiceMonitorに基づいたラベルのEndpointを参照し、自動的にScrapeします。
PrometheusOperatorのCustomResource
PrometheusOperatorでは、次のCustomResourceが定義されます。
すべてを詳しくはご紹介しませんが、簡単に。
- Prometheus
- ServiceMonitor
- PodMonitor
- ALertmanager
- PrometheusRule
実は、PodMonitorは使ったことがないので詳しくはわからないのですが、それ以外の4つは概ね次のようなものです。
Prometheus
PrometheusServerを定義します。
通常、Prometheusの設定はprometheus.ymlに書きますが、これらをKubernetesのCRDとして定義します。例としては次のような感じです。
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
baseImage: quay.io/prometheus/prometheus
nodeSelector:
kubernetes.io/os: linux
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
replicas: 2
retention: 7d
resources:
requests:
memory: 400Mi
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
remoteWrite: {}
remoteRead: {}
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: v2.11.0
replicasが2となっていますが、こうすることで自動的に2つのPrometheusが展開されます。3に変えれば3つのインスタンスが展開されます。簡単ですね。
他にも、例えば、retentionやremoteWrite/RemoteReadなどはまさにPrometheusの設定そのものです。
その他、詳しくはこちらのAPIリファレンスを参照ください。
https://github.com/coreos/prometheus-operator/blob/master/Documentation/api.md#prometheusspec
ConfigReloader
さらに、PrometheusOperatorでは、単にPrometheusの展開だけではなく、設定の自動再読み込みもサポートしています。
PrometheusOperatorを展開するとわかりますが、ConfigReloaderというコンテナが、PrometheusのPodのSidecarとして展開されます。
https://github.com/coreos/prometheus-operator/tree/master/cmd/prometheus-config-reloader
これは、kind: PrometheusやadditionalScrapeConfigs(ServiceMonitorなどで定義できないScrapeConfigを追加する)などを定期的に再読み込みし、稼働中のPrometheusに適用します。
通常、Prometheusの設定はprometheus.ymlを変更し、インスタンスを再起動することで適用していました。
しかし、PrometheusがScrapeするTargets増えると、すべてのTargetsがUp状態になるまで非常に時間がかかります。また、万が一設定が誤ってしまった場合は起動できなくなります(設定をもとに戻せば起動しますが)。
特に、GitOpsなどを採用している場合は、ConfigMapは変更されたが、Prometheusのインスタンスが再起動されないために、設定が適用されないことがありますが、こういったことがなくなるのです。
ServiceMonitor
ServiceMonitorは、Kubernetes上のServiceResourceを参照して、そのResourceが持つラベルと、ServiceMonitorに設定されたラベルを比較して、マッチするものを自動的にScrapeしてくれます。
通常、PrometheusでScrapeTargetを追加する場合は、ScrapeConfigsに一つ一つ設定を書く必要がありました。特に、単に「app: hoge-appを持つPodを監視したい」というように直感的に書くことはできず、一癖必要でした。
しかし、ServiceMonitorを使うことで次のように簡単に定義することが可能になります。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: prometheus
name: prometheus
namespace: monitoring
spec:
endpoints:
- interval: 30s
port: web
selector:
matchLabels:
prometheus: k8s
これは、PrometheusOperatorによって展開されたPrometheusを監視するためのServiceMonitorです。
注目すべきはこちら
selector:
matchLabels:
prometheus: k8s
KubernetesでDeploymentを定義する可能に、matchLabelsに対象のラベルのKey/Valueを定義することで簡単にTargetを指定することができます。
ただし、1点注意が必要で、これはPodのラベルではなく、Service…更に正しく言えばEndpointsのラベルを指定する必要があります。
Service Resourceを展開することで、自動的にEndpoints Resourceが作成されますが、逆にService Resourceがなくても、Endpoints Resourceさえあれば使用できます。
また、従来PrometheusのConfigからServiceの監視を行う場合はrole: serviceとしていました。
これは、Kubernetes上のService Resourceを参照するため、バックエンドのPodがいくつあろうと、TargetはService Resourceの数だけになります。例えば、3つのPodにマッチする1つのServiceが存在する場合は、Targetは1つだけになります。
対し、ServiceMonitorでは、Endpointsを参照すするため、3つのPodにマッチするServiceの場合は、3つのTargetを監視することになります。
さらに、IstioなどのVirtualServiceを使用することで、任意の宛先のServiceを作成することができるため、例えば外部のエンドポイントをPrometheusOperatorから監視するといった際にも、ServiceMonitorを利用することができます。
ServiceMonitorについて、その他詳細は以下のAPIリファレンスを参照ください。
https://github.com/coreos/prometheus-operator/blob/master/Documentation/api.md#servicemonitorspec
Alertmanager
AlertManagerを定義します。
主に、kind: Prometheusと変わりません。Alertmanagerのマニフェストの例としては次のとおりです。
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
labels:
alertmanager: main
name: main
namespace: monitoring
spec:
baseImage: quay.io/prometheus/alertmanager
externalUrl: 'alertmanager.example.com'
nodeSelector:
kubernetes.io/os: linux
replicas: 3
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: alertmanager-main
version: v0.18.0
ここでも、Prometheusと同様に、replicasの数だけ自動的に展開します。ただし、Prometheusと大きく違うのは、Clusteringの設定も自動で行います。
AlertManagerの冗長化はPrometheusのようにただ同じものを並べればよいというわけではありません。
AlertManagerのバイナリの引数に--cluster.peerを追加し、別のAlertManagerのインスタンスのエンドポイントを指定する必要があります。
https://github.com/prometheus/alertmanager#high-availability
これは、Kubernetes上で展開する際は、PodのIPアドレスは毎回変わってしまいます。そのため、AlertManagerごとに複数のService Resourceを作成する(AlertManager-BlueとAlertManager-Greenを作るように)など、工夫が必要でした。
しかし、PrometheusOperatorではこれらを自動的に設定してくれるため、このあたりの手間が大きく軽減されます。
Alertmanagerに関して、詳しくは以下のAPIリファレンスを参照ください。
https://github.com/coreos/prometheus-operator/blob/master/Documentation/api.md#alertmanagerspec
PrometheusRule
PrometheusRuleでは、PrometheusのRuleを設定することができます。
Prometheusには、Prometheus自体の設定や、Scrapeの設定の他に、Ruleというものがあります。
ここに、PromQLを用いて設定を書くことで、定期的にそのPromQLを実行し、マッチするものが存在すればAlertManagerでAlertingするといったことが定義できます。
これを、CRDとして定義したものがPrometheusRuleです。
こちらに関しては、特段通常のyamlを書くのと変わりませんが、別途ConfigMapを書く必要がありません。
PrometheusRuleの例は次のとおりです。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: prometheus-k8s-rules
namespace: monitoring
spec:
groups:
- name: general.rules
rules:
- alert: TargetDown
annotations:
message: '{{ printf "%.4g" $value }}% of the {{ $labels.job }} targets in
{{ $labels.namespace }} namespace are down.'
expr: 100 * (count(up == 0) BY (job, namespace, service) / count(up) BY (job,
namespace, service)) > 10
for: 10m
labels:
severity: warning
- name: node-network
rules:
- alert: NodeNetworkInterfaceFlapping
annotations:
message: Network interface "{{ $labels.device }}" changing it's up status
often on node-exporter {{ $labels.namespace }}/{{ $labels.pod }}"
expr: |
changes(node_network_up{job="node-exporter",device!~"veth.+"}[2m]) > 2
for: 2m
labels:
severity: warning
https://github.com/coreos/kube-prometheus/blob/master/manifests/prometheus-rules.yaml より一部抜粋
PrometheuRuleの詳細は、以下のAPIリファレンスを参照ください。
https://github.com/coreos/prometheus-operator/blob/master/Documentation/api.md#prometheusrulespec
PrometheusOperatorを実行する
では、PrometheusOperatorを実行するにはどうしたらよいでしょうか?
0から自分でマニフェストを書いても良いのですが、なかなか大変です。実は、CoreOSがオフィシャルでマニフェストのサンプルを用意しているので、こちらを使ってみましょう。
coreos/kube-prometheusというリポジトリの下に配置されています。
これをCloneしてきて、kubectl applyするだけです。やっていきましょう。
まずは、リポジトリをClone
git clone https://github.com/coreos/kube-prometheus
cd kube-prometheus
マニフェストを展開します。
./manifestsディレクトリの中にすべてあるので、これを展開します。
また、PrometheusOperatorのマニフェストは、./manifests/setupに存在するため、-Rオプションを付けて子ディレクトリの中も参照してもらうようにします。
すると、こんな感じで長々とCreateされるはずです。なお、NamespaceはMonitoringに作成されます。
> kubectl apply -f manifests/ -R
alertmanager.monitoring.coreos.com/main created
secret/alertmanager-main created
service/alertmanager-main created
serviceaccount/alertmanager-main created
servicemonitor.monitoring.coreos.com/alertmanager created
secret/grafana-datasources created
configmap/grafana-dashboard-apiserver created
configmap/grafana-dashboard-cluster-total created
configmap/grafana-dashboard-controller-manager created
configmap/grafana-dashboard-k8s-resources-cluster created
configmap/grafana-dashboard-k8s-resources-namespace created
configmap/grafana-dashboard-k8s-resources-node created
configmap/grafana-dashboard-k8s-resources-pod created
configmap/grafana-dashboard-k8s-resources-workload created
configmap/grafana-dashboard-k8s-resources-workloads-namespace created
configmap/grafana-dashboard-kubelet created
configmap/grafana-dashboard-namespace-by-pod created
configmap/grafana-dashboard-namespace-by-workload created
configmap/grafana-dashboard-node-cluster-rsrc-use created
configmap/grafana-dashboard-node-rsrc-use created
configmap/grafana-dashboard-nodes created
configmap/grafana-dashboard-persistentvolumesusage created
configmap/grafana-dashboard-pod-total created
configmap/grafana-dashboard-pods created
configmap/grafana-dashboard-prometheus-remote-write created
configmap/grafana-dashboard-prometheus created
configmap/grafana-dashboard-proxy created
configmap/grafana-dashboard-scheduler created
configmap/grafana-dashboard-statefulset created
configmap/grafana-dashboard-workload-total created
configmap/grafana-dashboards created
deployment.apps/grafana created
service/grafana created
serviceaccount/grafana created
servicemonitor.monitoring.coreos.com/grafana created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
role.rbac.authorization.k8s.io/kube-state-metrics created
rolebinding.rbac.authorization.k8s.io/kube-state-metrics created
service/kube-state-metrics created
serviceaccount/kube-state-metrics created
servicemonitor.monitoring.coreos.com/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/node-exporter created
clusterrolebinding.rbac.authorization.k8s.io/node-exporter created
daemonset.apps/node-exporter created
service/node-exporter created
serviceaccount/node-exporter created
servicemonitor.monitoring.coreos.com/node-exporter created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
clusterrole.rbac.authorization.k8s.io/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created
clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created
clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created
configmap/adapter-config created
deployment.apps/prometheus-adapter created
rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created
service/prometheus-adapter created
deployment.apps/prometheus-adapter created
rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created
service/prometheus-adapter created
serviceaccount/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/prometheus-k8s created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created
servicemonitor.monitoring.coreos.com/prometheus-operator created
prometheus.monitoring.coreos.com/k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s-config created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
prometheusrule.monitoring.coreos.com/prometheus-k8s-rules created
service/prometheus-k8s created
serviceaccount/prometheus-k8s created
servicemonitor.monitoring.coreos.com/prometheus created
servicemonitor.monitoring.coreos.com/kube-apiserver created
servicemonitor.monitoring.coreos.com/coredns created
servicemonitor.monitoring.coreos.com/kube-controller-manager created
servicemonitor.monitoring.coreos.com/kube-scheduler created
servicemonitor.monitoring.coreos.com/kubelet created
namespace/monitoring created
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
service/prometheus-operator created
serviceaccount/prometheus-operator created
kubectl get allでリソースを見てみましょう。
> kubectl get all
NAME READY STATUS RESTARTS AGE
pod/alertmanager-main-0 2/2 Running 0 4m56s
pod/alertmanager-main-1 2/2 Running 0 4m56s
pod/alertmanager-main-2 2/2 Running 0 4m56s
pod/grafana-5db74b88f4-2rhk9 1/1 Running 0 5m32s
pod/kube-state-metrics-54f98c4687-9wbhh 3/3 Running 0 5m31s
pod/node-exporter-4f6qx 0/2 Pending 0 5m31s
pod/node-exporter-s22tr 0/2 Pending 0 5m31s
pod/node-exporter-vdrxc 0/2 Pending 0 5m31s
pod/prometheus-adapter-8667948d79-qk5t8 1/1 Running 0 5m29s
pod/prometheus-k8s-0 3/3 Running 1 4m45s
pod/prometheus-k8s-1 3/3 Running 1 4m45s
pod/prometheus-operator-548c6dc45c-44gzx 1/1 Running 0 5m24s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-main ClusterIP 10.43.124.83 <none> 9093/TCP 5m38s
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 4m56s
service/grafana ClusterIP 10.43.49.25 <none> 3000/TCP 5m33s
service/kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 5m32s
service/node-exporter ClusterIP None <none> 9100/TCP 5m31s
service/prometheus-adapter ClusterIP 10.43.231.15 <none> 443/TCP 5m30s
service/prometheus-k8s ClusterIP 10.43.3.81 <none> 9090/TCP 5m28s
service/prometheus-operated ClusterIP None <none> 9090/TCP 4m45s
service/prometheus-operator ClusterIP None <none> 8080/TCP 5m25s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/node-exporter 3 3 0 3 0 kubernetes.io/os=linux 5m31s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/grafana 1/1 1 1 5m34s
deployment.apps/kube-state-metrics 1/1 1 1 5m33s
deployment.apps/prometheus-adapter 1/1 1 1 5m31s
deployment.apps/prometheus-operator 1/1 1 1 5m26s
NAME DESIRED CURRENT READY AGE
replicaset.apps/grafana-5db74b88f4 1 1 1 5m34s
replicaset.apps/kube-state-metrics-54f98c4687 1 1 1 5m33s
replicaset.apps/prometheus-adapter-8667948d79 1 1 1 5m31s
replicaset.apps/prometheus-operator-548c6dc45c 1 1 1 5m26s
NAME READY AGE
statefulset.apps/alertmanager-main 3/3 4m57s
statefulset.apps/prometheus-k8s 2/2 4m46s
Node ExpoterがPendingになっていますが、それ以外は無事展開できているようです。
Podの中にpod/prometheus-k8s-0がありますが、これがPrometheusServer本体です。デフォルトではreplicas: 2と定義されているため、2つのPrometheusが展開されました。
また、その下にあるpod/prometheus-operatorがOperator本体です。
とりあえずPrometheusに接続してみましょう。
通常のPrometheusと同様に0.0.0.0:9090で接続できるため、以下のようにPortFowardしてブラウザから接続してみましょう。
> kubectl port-forward service/prometheus-k8s 9090:9090 --address 0.0.0.0
Forwarding from 0.0.0.0:9090 -> 9090
ブラウザからTargetsページを見ると、ちゃんと各種Targetsも接続されていました。
以上で、とりあえず動かせるようになりましたね。
試しに、PrometheusServerとAlertManagerのReplicasを変更してみましょう。
それぞれ以下のファイルを変更します。
podMonitorSelector: {}
replicas: 10 # とりあえず気分がいいので10個に
retention: 7d
resources:
nodeSelector:
kubernetes.io/os: linux
replicas: 20 # AlertManagerは大事なので20個に
securityContext:
先ほどと同様にapplyして、kubectl get podします。
> kubectl apply -f ./manifests -R
※以下略
> kubectl get pod
NAME READY STATUS RESTARTS AGE
pod/alertmanager-main-0 2/2 Running 0 16m
pod/alertmanager-main-1 2/2 Running 0 16m
pod/alertmanager-main-10 2/2 Running 0 32s
pod/alertmanager-main-11 2/2 Running 0 32s
pod/alertmanager-main-12 2/2 Running 0 32s
pod/alertmanager-main-13 2/2 Running 0 32s
pod/alertmanager-main-14 2/2 Running 0 32s
pod/alertmanager-main-15 2/2 Running 0 32s
pod/alertmanager-main-16 2/2 Running 0 32s
pod/alertmanager-main-17 2/2 Running 0 32s
pod/alertmanager-main-18 2/2 Running 0 32s
pod/alertmanager-main-19 2/2 Running 0 32s
pod/alertmanager-main-2 2/2 Running 0 10s
pod/alertmanager-main-3 2/2 Running 0 32s
pod/alertmanager-main-4 2/2 Running 0 32s
pod/alertmanager-main-5 2/2 Running 0 32s
pod/alertmanager-main-6 2/2 Running 0 32s
pod/alertmanager-main-7 2/2 Running 0 32s
pod/alertmanager-main-8 2/2 Running 0 32s
pod/alertmanager-main-9 2/2 Running 0 32s
pod/grafana-5db74b88f4-2rhk9 1/1 Running 0 16m
pod/kube-state-metrics-54f98c4687-9wbhh 3/3 Running 0 16m
pod/node-exporter-4f6qx 0/2 Pending 0 16m
pod/node-exporter-s22tr 0/2 Pending 0 16m
pod/node-exporter-vdrxc 0/2 Pending 0 16m
pod/prometheus-adapter-8667948d79-qk5t8 1/1 Running 0 16m
pod/prometheus-k8s-0 3/3 Running 1 16m
pod/prometheus-k8s-1 3/3 Running 1 16m
pod/prometheus-k8s-2 3/3 Running 0 22s
pod/prometheus-k8s-3 3/3 Running 0 22s
pod/prometheus-k8s-4 3/3 Running 0 22s
pod/prometheus-k8s-5 3/3 Running 1 22s
pod/prometheus-k8s-6 3/3 Running 1 22s
pod/prometheus-k8s-7 3/3 Running 1 22s
pod/prometheus-k8s-8 3/3 Running 0 22s
pod/prometheus-k8s-9 3/3 Running 1 21s
pod/prometheus-operator-548c6dc45c-44gzx 1/1 Running 0 16m
ワースゴイ…
とまぁ、こんな感じで簡単にPodを展開できました。
また、AlertManagerの設定を確認してみるとわかりますが、20個全てがちゃんとPeerの設定がされています。(スゴイネ
私は力尽きた
本当はServiceMonitorの書き方とかもご紹介したかったのですが、私が力尽きたので今回はココまでです。
反響があれば、ServiceMonitorの書き方とか、運用方法とかご紹介できればと思います。
(PrometheusをKubernetes上で運用するのどうなの?とか
Prometheus自体は非常に便利かつシンプルな監視プロダクトなんですが、Kubernetes上で展開するには意外と考える事が多いです。
しかし、Operatorを使うことで改善されたり、便利になることがあるため、ぜひとも触ってみてください!