この記事は何?
VSCodeで初めてのテキストマイニングに挑戦、その学習ログです。
「pythonによるテキストマイニング入門」(山内長承)が参考図書です
環境
VSCode
実践
テキストファイルを用意
・安倍総理の会見を引用
・テキスト部分をメモ帳アプリにコピー
・abe_sori_enzetsu.txtで保存
・適当なディレクトリに配置
ライブラリのインポート
# パッケージをインストール
pip install igraph
pip install pycairo
# 使用するライブラリをインポート
import re
import numpy as np
from collections import Counter
import MeCab
import itertools
from igraph import Graph, plot
ファイルの読み込み&正規化
minfreq = 0
m = MeCab.Tagger("-Ochasen")
# ファイルを読み込み、文を分割し空白を除去する関数
def readin(filename):
with open(filename, "r", encoding="utf-8") as afile:
whole_str = afile.read()
# re.sub()関数で句点を置換、文を改行文字 "\\n" で分割
sentenses = (re.sub("。", "。\n", whole_str)).splitlines()
# 空白を削除し、文が空でない場合にそれを新しいリストに追加
return [re.sub(" ", "", u) for u in sentenses if len(u)!=0]
# 先ほどの.txtファイルは以下に置いた
filename = "C:\\Users\\--ここは自分のPC参照--\\Documents\\nltk_data\\jeita\\jeita_aozora\\abe_sori_enzetsu.txt"
string = readin(filename)
# 文単位で形態素解析し、名詞だけ抽出し、基本形を文ごとのリストにする
sentense_meishi_list = [ [v.split()[2] for v in m.parse(sentense).splitlines() if (len(v.split())>=3 and v.split()[3][:2] == "名詞" )] for sentense in string]
【解説】
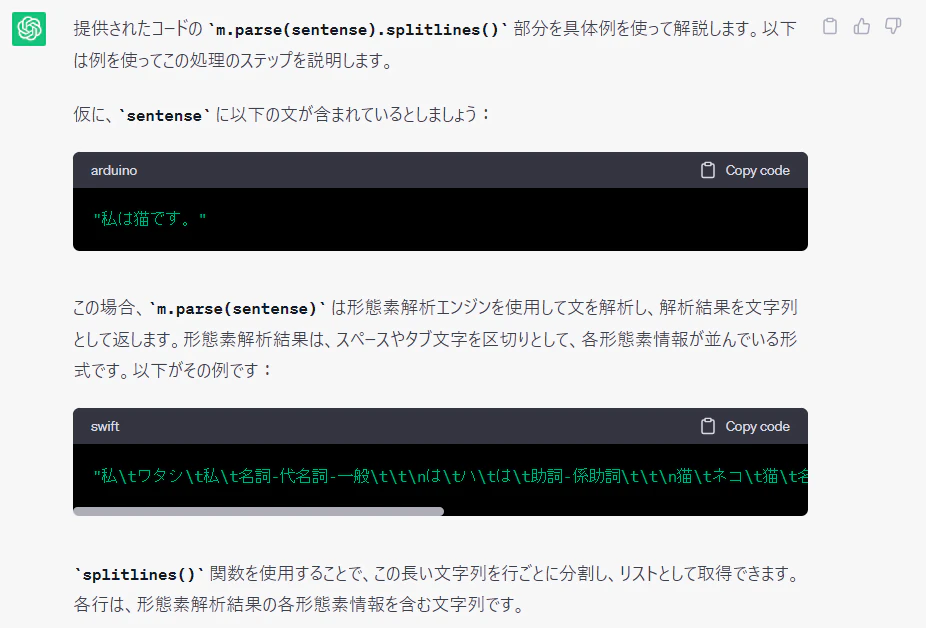
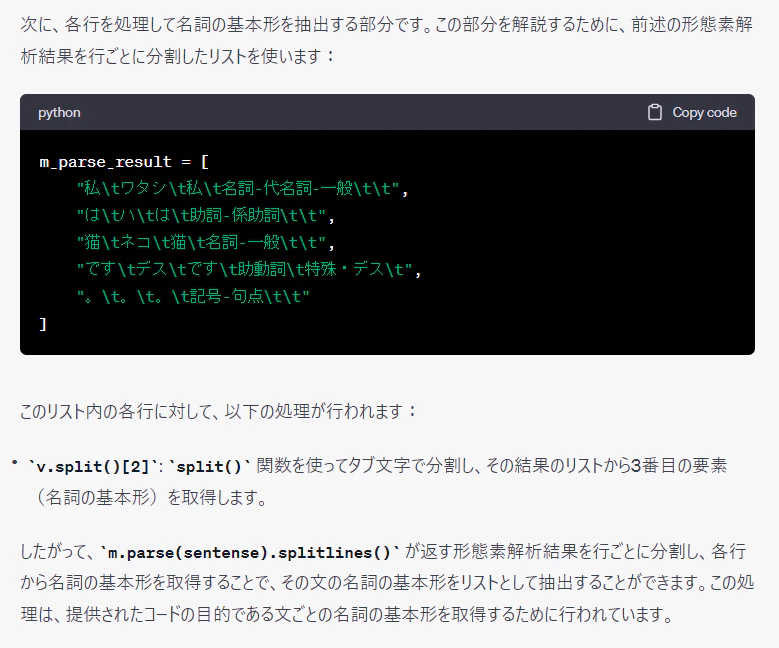
# 文ごとにペアリストを作る
doublets_list = [list(itertools.combinations(meishi_list, 2)) for meishi_list in sentense_meishi_list if len(meishi_list) >= 2]
all_doublets = []
# 文ごとのペアリストのリストをフラットなリストにする
for u in doublets_list:
all_doublets.extend(u)
# 名詞ペアの頻度を数える
dcnt = Counter(all_doublets)
# 出現頻度順にソートした共起ペアを出力(上位30ペア)
print("pair frequency", sorted(dcnt.items(), key=lambda x: x[1], reverse=True)[:30])

# 名詞ペアの頻度辞書から、頻度が4以上のエントリだけを抜き出した辞書を作成
restricted_dcnt = dict(((k, dcnt[k]) for k in dcnt.keys() if dcnt[k] >= minfreq))
charedges = restricted_dcnt.keys()
vertices = list(set( [v[0] for v in charedges] + [v[1] for v in charedges] ))
# charedgesは(["名詞","名詞"])の形なのでvertid(数字)
edges = [(vertices.index(u[0]), vertices.index(u[1])) for u in charedges]
g = Graph(vertex_attrs={"label": vertices, "name": vertices}, edges=edges, directed=False)
plot(g, vertex_size=20, bbox=(800, 800), vertex_color="white", fontname="IPAGothic")
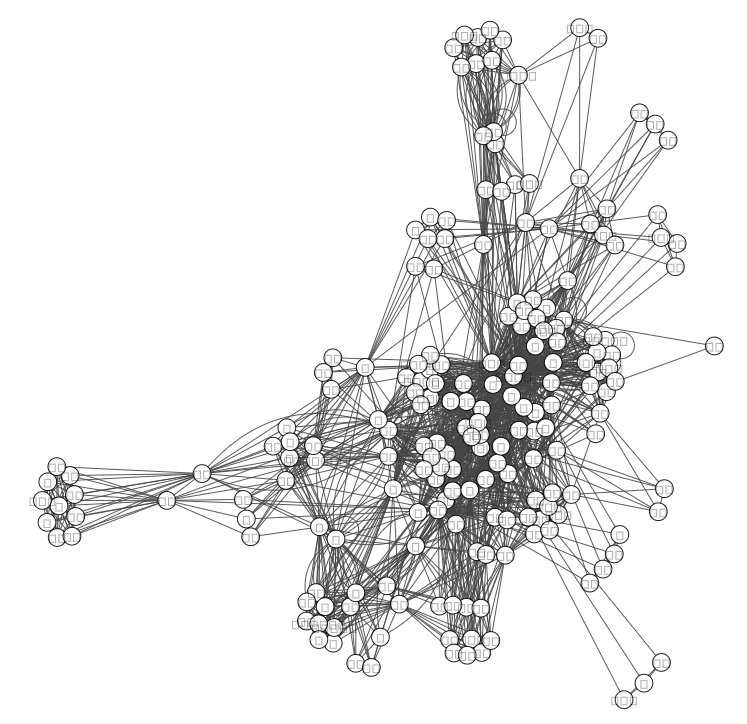
※
文字化けしたが、直し方が分からない…
いつかこの方の記事などを参考に直す