この記事は何?
VSCodeで初めてのテキストマイニングに挑戦、その学習ログです。
「pythonによるテキストマイニング入門」(山内長承)が参考図書です
環境
VSCode
実践
文字の出現頻度
# Counterクラスを使用
from collections import Counter
string = "I have a dream."
cnt = Counter(string_1)
print(cnt)

文字のN-gram分析
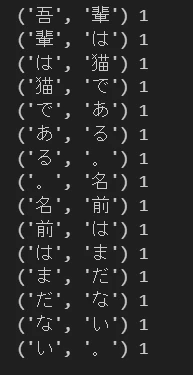
string = "吾輩は猫である。名前はまだない。"
# 「、」、スペースを区切り文字とする。
delimiter = ["「", "」", " "]
# zipでペアのタプルを作成する
doublets = list(zip(string[:-1], string[1:]))
doublets = filter((lambda x: not((x[0] in delimiter) or (x[1] in delimiter))), doublets) # 今回はない
# タプルの2番目の要素をキーにソートを行う
dic2 = Counter(doublets)
for k,v in sorted(dic2.items(), key=lambda x:x[1], reverse=True)[:50]:
print(k, v)
【補足】
string = "吾輩は猫である。名前はまだない。"
# 初めから最後-1の文字までをタプルの[0]に入れる
string[:-1]

# 初め+1から最後の文字までをタプルの[1]に入れる
string[1:]

語のN-gram分析
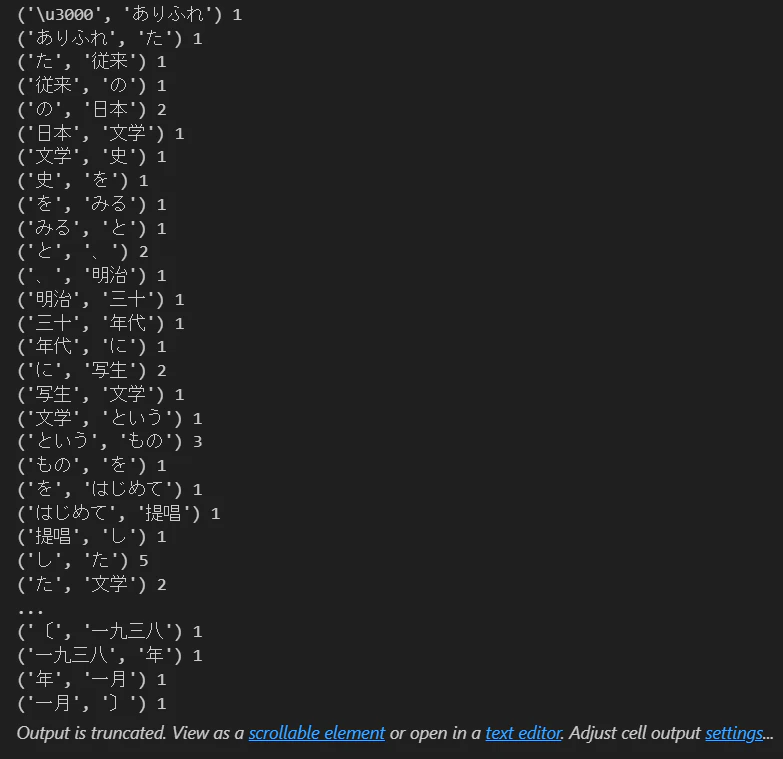
JEITAコーパス内のファイルを読み込んで実施する(HPは▶こちら)
以下からダウンロード
http://masatohagiwara.net/files/jeita_aozora.tar.bz2
ファイルはドキュメントの特定のファイル下に移動させる
# ディレクトリを強制
import os
os.chdir("c:/Users/--ここは自分のPC参照--/Documents/nltk_data/jeita/jeita_aozora")
pwd

# ディレクトリを指定
corpus_dir = "\\Users\\shota.kikko.bg\\Documents\\nltk_data\\jeita\\jeita_aozora"
# jeitaコーパスデータの読み込み
jeita = ChasenCorpusReader(corpus_dir, "1000.chasen")
delimiter = ["「", "」", " ", "『", "』"]
string = jeita.words()
doublets = list(zip(string[:-1], string[1:]))
doublets = filter((lambda x: not((x[0] in delimiter) or (x[1] in delimiter))), doublets)
dic2 = Counter(doublets)
for u,v in dic2.items():
print(u,v)
(最初の\u3000は何だろう…)