モチベーション
業務で電気回路図の画像から回路素子を抽出したいというタスクを課されたのですが、これがNon-Deepのテンプレートマッチングや特徴量マッチングではかなり難しいタスクだということに気づきました。
例えば下のような入力画像から、テンプレート画像の回路素子を見つけたいというものです。
| 入力画像 | テンプレート画像 |
|---|---|
 |
 |
このタスクでは、non-deepのテンプレートマッチングでは大きさの変化や解像度の変化への対応が難しく、特徴量マッチングではもともとの画像の特徴量がとても少ないためうまくいかず...
Deepで物体検出をしようにも、回路素子の形は一意に決まっているため、解像度を変化させるくらいしかデータセットの作成方法がなく、不可能です。
なんとかPretrainedのモデルを用いた、学習をしないDeepベースの手法がないかと探した結果、次の論文を見つけたので、実装してみました。
論文紹介
リンク
論文pdf
http://www.apsipa.org/proceedings/2017/CONTENTS/papers2017/14DecThursday/TA-02/TA-02.5.pdf
実装したもの
https://github.com/kamata1729/robustTemplateMatching
Abstract
- CNNの特徴量ベースで、ロバストかつ効率的なテンプレートマッチングの手法を提案
- オリジナリティとしては、scale-adaptiveな特徴量抽出の手法をとっていること
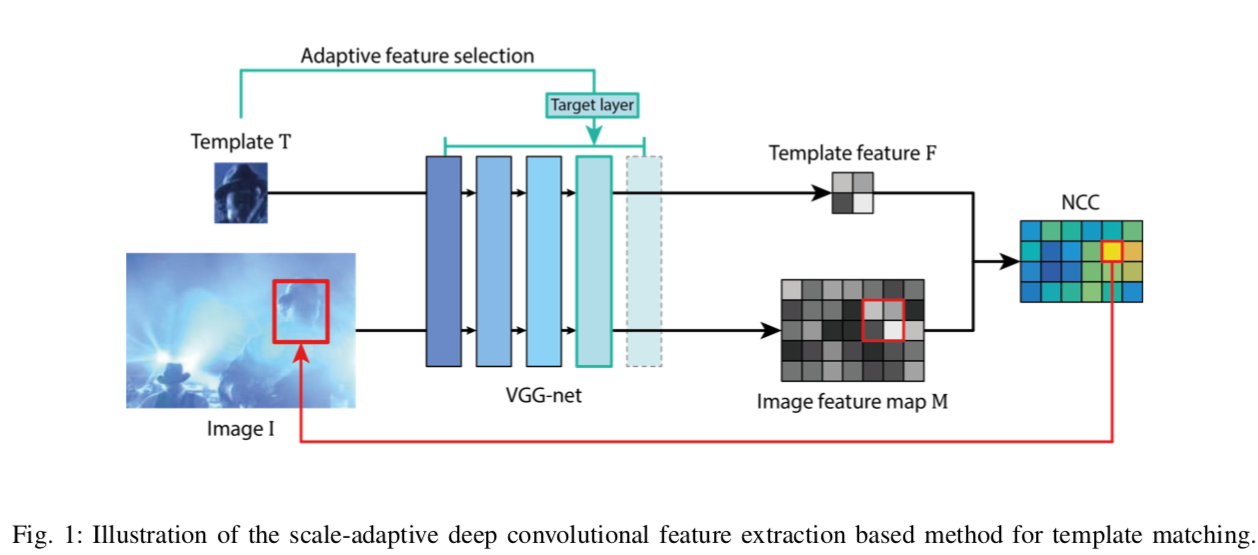
- テンプレート画像と入力画像をそれぞれCNNに入れ、それぞれ途中の層の特徴量を抽出する
- その特徴量を、NCC(normalized cross-correlation)を用いてもっとも似ている場所を検出する
- この手法で、それまでのstate-of-the-art以上の精度を出すことができ、さらに計算コストも大幅に下げることが可能
1. Introduction
-
これまでの手法
-
従来のNon deepのテンプレートマッチング手法では、ロバスト性に欠ける
-
また、CNNベースのこれまでの手法は、計算コストがとても大きい
-
-
この論文での提案手法
- スケール性を保った特徴量マップを学習済みのVGGからもってくる
- NCC (normarized cross-correlation) を使い、templateとimageの特徴量マップ間の距離を計算し、マッチングする
2. Proposed Method
まず、テンプレートマッチングを、入力画像 $I \in \mathcal{R}^{m \times n \times 3}$から、もっともてっmプレート画像 $T \in \mathcal{R}^{w \times h \times 3}$ に近い場所を取り出す問題として定義する。
(ここで、$(m, n)$は入力画像 $I$の縦横の大きさ、$(w, h)$はテンプレート$T$の大きさとする)
A. Scale Adaptive Deep Convolutional Feature Extraction
特徴量抽出には、VGG-Netを使用 (VGGの種類には言及されていないが、おそらくこの論文ではVGG13を採用している。理由は後で記載)
ほかのCNNベースの手法と異なり、scale-adaptivenessを獲得するため、画像を(224, 224)などの決まったサイズにリサイズせず、画像の大きさも考慮にいれる。
次に、VGGのどの層から特徴量マップを取得するかを決める。
そのためにまず、VGGの$l$番目の層の、receptive field(受容野) を求める。
- ここでreceptive fieldとは、一つの特徴量が考慮に入れることができる入力画像の範囲のことを表していると考えられる
- 以下では、「$l$層目」と言った場合には、上からconvolution層とpooling層を数えた時の$l$番目の層とし、ReLUやBatch normは1層と数えない。
$l$層目のreceptive fieldの大きさ$rf^l \times rf^l$は以下のように求めることができる。
\begin{equation}
rf^l = \begin{cases}
rf^{l-1} + (f^l -1)\prod_{i=1}^{l-1} s^i &(l > 1) \\
3 &(l=1)
\end{cases}
\end{equation}
ここで、$f^l$は$l$層目のフィルターサイズを表し、$s^i$は$i$層目のストライドを表す。
receptive field の意味
$rf^l$は、元の画像のうち、$l$層目の特徴量が考慮に入れている入力画像の大きさになっている。
$l=1$のときの3は、VGGの最初のConv層のフィルターサイズである。
以下の図を見るとわかりやすい。
ストライドが1の場合は、一層目の特徴量が考慮できるinput imageの大きさは3, 二層目の場合は7となり、上式の関係を満たしている。
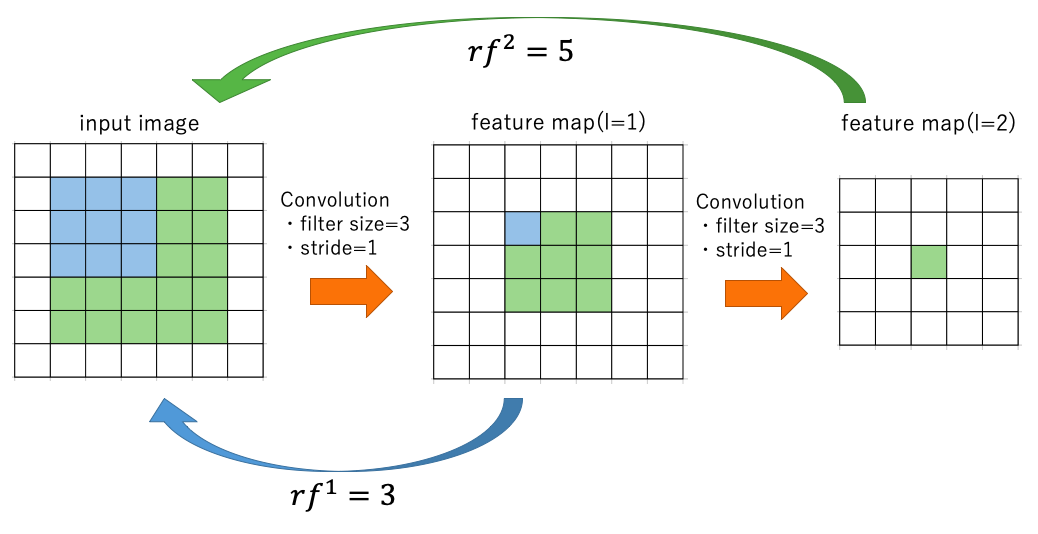
一層目のConvolutionのストライドが2の場合も、下の図のように考えれば、$f^1=3,~f^2=3,~s^1=2,~s^2=1$であり、
\begin{align}
rf^1& = 3\\
rf^2&=7\\
&=rf^1+(f^2-1)*s^1
\end{align}
となり上式を満たすことがわかる。
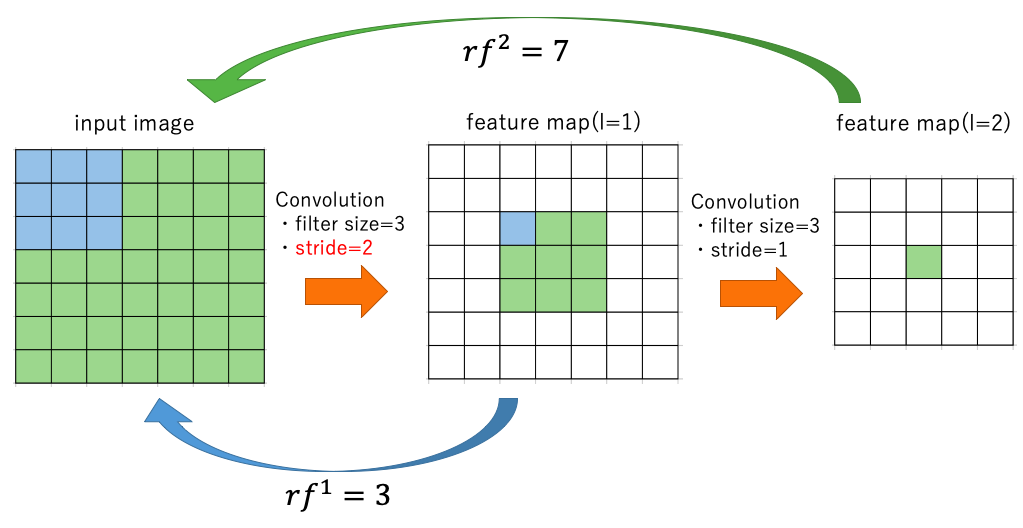
pooling層に関しても同様に考えることができる。
上記のように、$rf^l$は考慮している画像の大きさであるから、もし$rf^l$がテンプレートがテンプレート画像の大きさ$min(w. h)$よりも大きければ、テンプレート画像の大きさより広い範囲の特徴量を考えてしまっているため、今回の問題に対しては意味のない特徴量を出していることになる。
よって、特徴量を得る層のインデックス$l^*$は、以下の式で求めることとする。
\begin{equation}
l^* = max(l-k, 1) ~~s.t.~~ rf^l\le min(w,h)
\end{equation}
ここで、$k$は非負整数であるが、今回の実験では$k=3$に設定している。
なぜk=3に設定しているのか
$l$層目と$l-3$層目の間に必ずpooling層が挟まれるから
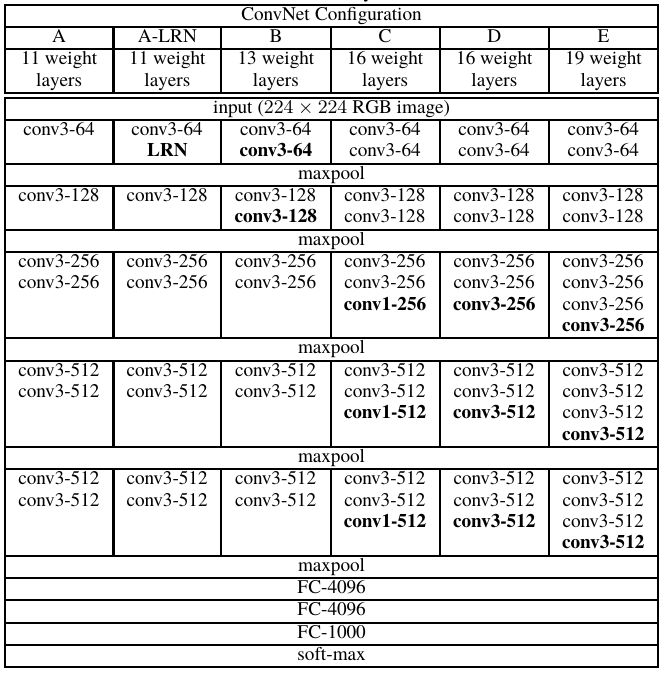
ここから、VGGの種類が特定できる。
下の図はVGGの各種類のアーキテクチャであるが、3層ごとにpoolingが挟まれるのはBのVGG13であるから、おそらくこの論文でも使っているのはVGG13だと思われる。
B. NCC-based Similarity Measure
上記の方法で、入力画像画像 $I$から取り出した特徴量マップを$M$, テンプレート画像$T$から取り出した特徴量マップを$F$とする。
$F$のサイズを$(channel, h_f, w_f)$とし、 $\tilde{M} = M_{i:i+h_f-1, j:j+w_f-1}$とする。
$M$から$F$にもっとも似た場所を取り出すために、NCCを以下のように計算する。
\begin{equation}
NCC_{i,j} = \frac{<F, \tilde{M}>}{|F||\tilde{M}|}
\end{equation}
ここで、$<\cdot , \cdot>$はフロベニウス内積、$|\cdot|$はフロベニウスノルムを示している(はず)
そして、
\begin{equation}
i*, j* = argmax_{i,j} ~NCC_{i,j}
\end{equation}
として$(i*, j*)$を計算する。
(今回の実装ではこのNCCの計算がボトルネックになっていたのでcythonで高速化を図りました)
C. Location Refinement
特徴量マップの空間で、もっとも似ている場所$(i*, j*)$を見つけることができたので、これをback-projectionによって、入力画像の空間のバウンディングボックス $((x_1^0 , y_1^0 ), (x_2^0 , y_2^0 ))$ に変換する。
back-projectionって何?
ここも論文に書いていないので推測です。(わかる方教えてください)
back-projectionを検索してもそれっぽいものはヒットしませんでした。
単純に考えて、特徴量マップの空間も入力画像の空間情報を保持しているので、単純に$(i*, j*)$の入力画像の大きさに対応した場所を取ってくればいいような気がします。
ただ、バウンディングボックスとして取ってくるというふうに書いているのでどうしたらいいものか
とりあえず、論文自体テンプレート画像の大きさも使っていこうという趣旨なので、実装は対応する場所を中心としたテンプレート画像と同じ大きさのバウンデングボックスを取ることにしました。
上のようにして取得したバウンデングボックス$((x_1^0 , y_1^0 ), (x_2^0 , y_2^0 ))$を、NCCの値を用いて以下のように修正する。(これも$rf^i$の式の意味を考えれば理解できますね)
\begin{align}
x_1 &= \frac{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v} ~\cdot(x_1^0 + v~\cdot \prod_{i=1}^{l*-1}s^i)}{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v}}\\
x_2 &= \frac{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v} ~\cdot(x_2^0 + v~\cdot \prod_{i=1}^{l*-1}s^i)}{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v}}\\
y_1 &= \frac{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v} ~\cdot(y_1^0 + u~\cdot \prod_{i=1}^{l*-1}s^i)}{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v}}\\
y_2 &= \frac{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v} ~\cdot(y_2^0 + u~\cdot \prod_{i=1}^{l*-1}s^i)}{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v}}
\end{align}
これにより、物体領域 $((x_1 , y_1), (x_2 , y_2))$ を得る。
3. Experiments
Fig 2
- 既存手法よりも良い精度がでる
- 既存手法よりも実行時間が早い
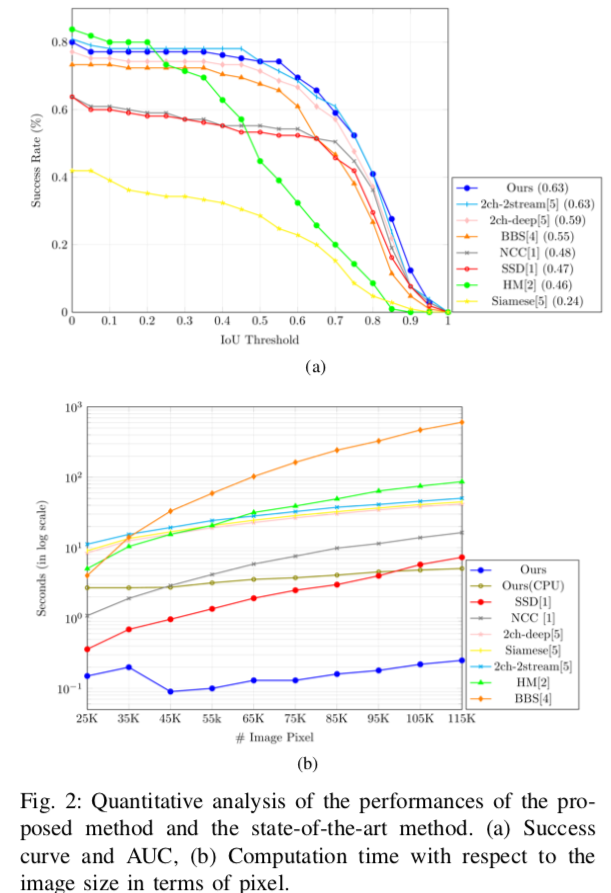
Fig 3
- $min(w, h)=40$のテンプレート画像について、特徴量を取得するlayerを変化させたときのAUC
$k=3$のときの$l*$はpool2で、このときがもっとも精度が良い - kを変化させたときのAUC.
$k=3$のときがもっとも良い
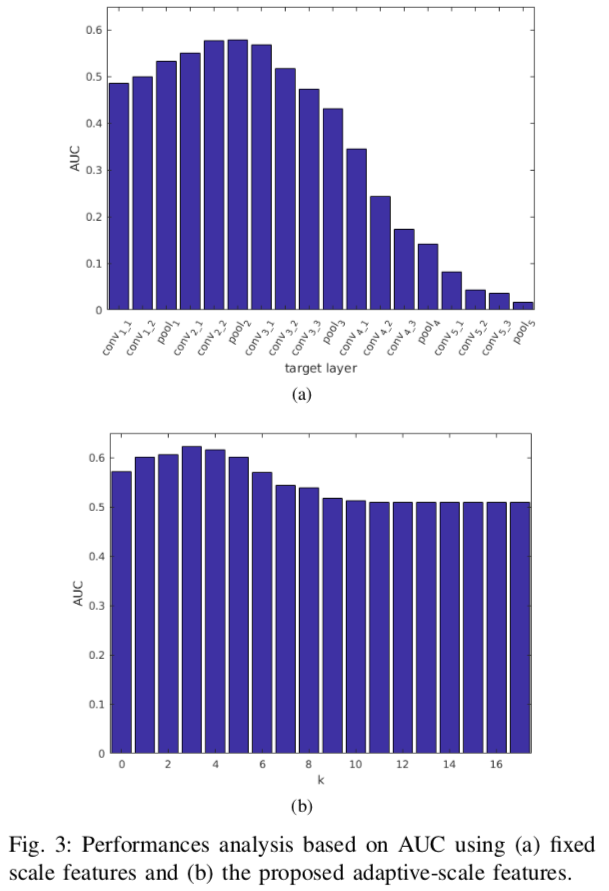
Fig 4
さまざまな状況でのテンプレートマッチングの結果

実装の結果
だいぶいい感じに検出できてます!
https://github.com/kamata1729/robustTemplateMatching
| sample image | template image | result image |
|---|---|---|
|
|
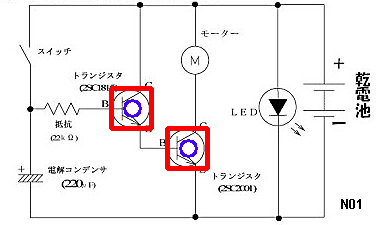 |
 |
 |
 |