はじめに
最近『達人に学ぶ SQL 徹底指南書 第 2 版』を読みました。
関係データベースや SQL の背景には、集合論や代数構造といった数学が深く関わっていることを知り、学生時代の勉強が役に立っていたことに感動しました。
ここでは、数学的な視点で関係データベースを整理してみます。
1. 関係とは集合である
関係(テーブル)は、列の定義域の直積の部分集合として定義されます。
関係: $R$ , 属性(列): $A_i$ , その定義域: $D_i$
$$R \subseteq D_1 \times D_2 \times D_3 \times \cdots \times D_n$$
つまり、関係は、列の定義域の直積の部分集合です。
ex.
属性 $a_1$, $a_2$, $a_3$ の定義域を
$$
d_1 = \{1\}, d_2 = \{'\mathrm{m}', '\mathrm{f}'\}, d_3 = \{'\mathrm{r}', '\mathrm{g}', '\mathrm{b}'\}
$$
とすると、直積は
| $a_1$ | $a_2$ | $a_3$ |
|---|---|---|
| 1 | m | r |
| 1 | m | g |
| 1 | m | b |
| 1 | f | r |
| 1 | f | g |
| 1 | f | b |
関係(テーブル)は、この直積の部分集合となります。
2. 関係と代数構造
代数構造のうち、次の 3 つについて考えます。
- 群 : 加法・減法について閉じている
- 環 : 加法・減法・乗法について閉じている
- 体 : 加法・減法・乗法・除法について閉じている
関係(テーブル)は、
- 足す(
UNION) - 引く(
EXCEPT) - 掛ける(
CROSS JOIN) - 割る
といった操作をしても、結果はまたテーブルになる ため、群であり、環であり、体であると言えます。
2.1 加法(UNION)
A テーブル
| id | name |
|---|---|
| 1 | 太郎 |
| 2 | 花子 |
| 3 | 次郎 |
B テーブル
| id | name |
|---|---|
| 1 | 太郎 |
| 2 | 花子 |
| 4 | 三郎 |
SELECT name FROM A
UNION
SELECT name FROM B;
結果
| name |
|---|
| 太郎 |
| 花子 |
| 次郎 |
| 三郎 |
重複を許す場合は UNION ALL を使うと高速です。
重複削除のための暗黙のソートが行われないためです。
2.2 減法(EXCEPT)
SELECT name FROM A
EXCEPT
SELECT name FROM B;
結果
| name |
|---|
| 次郎 |
2.3 乗法(CROSS JOIN)
SELECT
A.name AS a_name,
B.name AS b_name
FROM
A CROSS JOIN B;
結果
| a_name | b_name |
|---|---|
| 太郎 | 太郎 |
| 太郎 | 花子 |
| 太郎 | 三郎 |
| 花子 | 太郎 |
| 花子 | 花子 |
| 花子 | 三郎 |
| 次郎 | 太郎 |
| 次郎 | 花子 |
| 次郎 | 三郎 |
2.4 除法
演算子は定義されていませんが、次の 3 通りで表現できます。
-
NOT EXISTSを入れ子にする -
HAVING句を使う - 減法で表現する
ex. EmployeeSkill テーブルから、RequiredSkill テーブルの技術すべてに精通した社員を探す
RequiredSkill テーブル
| skill |
|---|
| Oracle |
| UNIX |
| Java |
EmployeeSkill テーブル
| emp_id | skill |
|---|---|
| 1 | Oracle |
| 1 | UNIX |
| 1 | Java |
| 1 | C# |
| 2 | Oracle |
| 2 | UNIX |
| 2 | Java |
| 3 | UNIX |
| 3 | Oracle |
| 3 | PHP |
| 3 | Perl |
| 3 | C++ |
| 4 | Perl |
| 5 | Oracle |
結果
| emp_id |
|---|
| 1 |
| 2 |
2.4.1 NOT EXISTS を入れ子にする
SELECT emp_id
FROM EmployeeSkill ES1
WHERE NOT EXISTS (
SELECT skill
FROM RequiredSkill RS
WHERE NOT EXISTS (
SELECT 1
FROM EmployeeSkill ES2
WHERE ES2.emp_id = ES1.emp_id
AND ES2.skill = RS.skill
)
);
2.4.2 HAVING 句を使う
SELECT emp_id
FROM EmployeeSkill
WHERE skill IN (SELECT skill FROM RequiredSkill)
GROUP BY emp_id
HAVING
COUNT(DISTINCT skill) = (
SELECT COUNT(*) FROM RequiredSkill
);
ちなみに、パフォーマンスを考慮するのであれば、IN を EXISTS や INNER JOIN に置き換えるとよいです。
IN を EXISTS で置き換える
SELECT emp_id
FROM EmployeeSkill ES
WHERE EXISTS (
SELECT 1
FROM RequiredSkill RS
WHERE RS.skill = ES.skill
)
GROUP BY emp_id
HAVING
COUNT(DISTINCT ES.skill) = (
SELECT COUNT(*) FROM RequiredSkill
);
メリット
- 結合キーでインデックスを使える可能性がある
- 全表検索の必要がない(1 行でも条件を満たす行が存在したらそこで検索を打ち切るため)
IN を INNER JOIN で置き換える
SELECT ES.emp_id
FROM
EmployeeSkill ES
INNER JOIN RequiredSkill RS
ON ES.skill = RS.skill
GROUP BY ES.emp_id
HAVING
COUNT(DISTINCT ES.skill) = (
SELECT COUNT(*) FROM RequiredSkill
);
メリット
- 結合キーでインデックスを使える可能性がある
- 中間ビューが作られない(サブクエリがなくなるため)
2.4.3 減法で表現する
SELECT DISTINCT emp_id
FROM EmployeeSkill ES
WHERE NOT EXISTS (
SELECT skill
FROM RequiredSkill
EXCEPT
SELECT skill
FROM EmployeeSkill ES2
WHERE ES2.emp_id = ES.emp_id
);
3. 結合と集合演算
結合を使って集合演算を表現することができます。
ex. A テーブルと B テーブルの集合演算
A テーブル(再掲)
| id | name |
|---|---|
| 1 | 太郎 |
| 2 | 花子 |
| 3 | 次郎 |
B テーブル(再掲)
| id | name |
|---|---|
| 1 | 太郎 |
| 2 | 花子 |
| 4 | 三郎 |
3.1 交差結合(CROSS JOIN)
直積(再掲)
SELECT
A.name AS a_name,
B.name AS b_name
FROM
A CROSS JOIN B;
結果
| a_name | b_name |
|---|---|
| 太郎 | 太郎 |
| 太郎 | 花子 |
| 太郎 | 三郎 |
| 花子 | 太郎 |
| 花子 | 花子 |
| 花子 | 三郎 |
| 次郎 | 太郎 |
| 次郎 | 花子 |
| 次郎 | 三郎 |
3.2 内部結合(INNER JOIN)
論理積(INTERSECT)
SELECT
A.name AS a_name,
B.name AS b_name
FROM
A INNER JOIN B
ON A.id = B.id;
結果
| a_name | b_name |
|---|---|
| 太郎 | 太郎 |
| 花子 | 花子 |
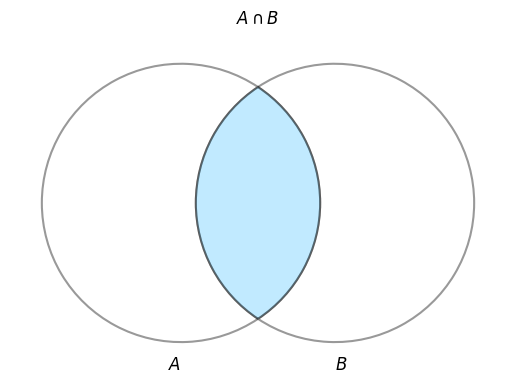
3.3.1 完全外部結合(FULL OUTER JOIN)
論理和(UNION)
SELECT
A.name AS a_name,
B.name AS b_name
FROM
A FULL OUTER JOIN B
ON A.id = B.id;
結果
| a_name | b_name |
|---|---|
| 太郎 | 太郎 |
| 花子 | 花子 |
| 次郎 | |
| 三郎 |
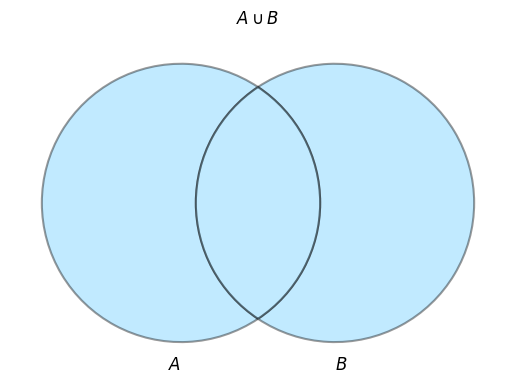
排他的論理和
SELECT
COALESCE(A.name, B.name) AS name
FROM
A FULL OUTER JOIN B
ON A.id = B.id
WHERE
A.name IS NULL
OR B.name IS NULL;
結果
| name |
|---|
| 次郎 |
| 三郎 |
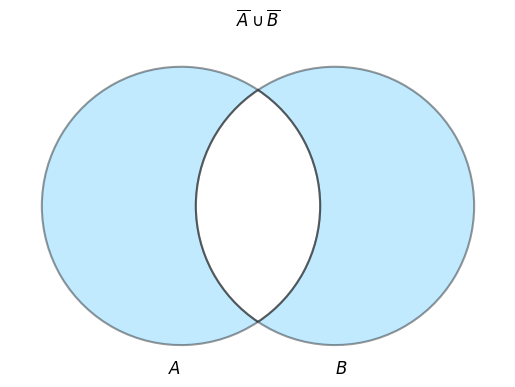
3.3.2 左外部結合(LEFT OUTER JOIN)
A - B
SELECT
A.name AS a_name
FROM
A LEFT OUTER JOIN B
ON A.id = B.id
WHERE
B.name IS NULL;
結果
| a_name |
|---|
| 次郎 |
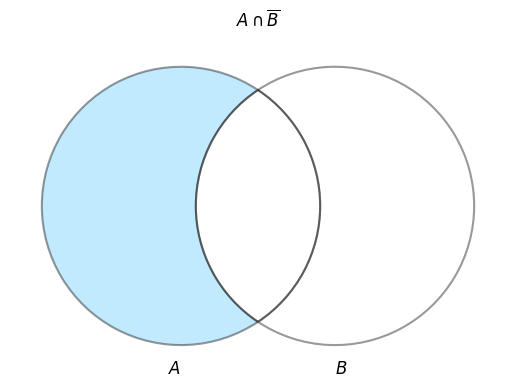
3.3.3 右外部結合(RIGHT OUTER JOIN)
B - A
SELECT
B.name AS B_name
FROM
A RIGHT OUTER JOIN B
ON A.id = B.id
WHERE
A.name IS NULL;
結果
| b_name |
|---|
| 三郎 |
おわりに
Theory is Practical.
関係データベースは 数学的に厳密だからこそ、実務でも強力 だということがわかりました。
余談
添付したベン図は matplotlib-venn を使って描きました 🎨