はじめに
このシステムで作成した動画をYoutube等で配信する場合は著作物の扱いに十分注意してください。ネット上の画像を無断で加工し配信することは、著作権、肖像権の侵害にあたります。
ご利用においてなにか問題が発生した場合、責任を負いかねます。ご利用は自由ですが、自己責任でお願いします。
制作物
以下のようなまとめ動画を4分程度で作成してくれます。
先述の通り、ライセンスを無視してネット上の画像を無断で加工し配信することは、著作権、肖像権の侵害にあたります。リンクの動画は知りませんが、このシステムで作成した動画をYoutube等でアップロードする場合は著作物の扱いには十分注意した上で、自己責任でお願いいたします。
github
こだわりポイント
- ふんいきオブジェクト指向(しっかりと勉強したわけじゃないので...)
- オプションを多くして、拡張性を高く。
自己紹介
神奈川在住の大学三年生。エンジニア系のインターンに受かることを目標に2022年9月からJavascriptの勉強を開始。10月にwebアプリの基本を抑えたのでwebアプリ制作を制作。その後はインターン全落ちして萎えていたが、冬にpythonスクレイピングを勉強し、それで友人の起業の手伝いをして小遣いを稼ぐ。
制作の経緯
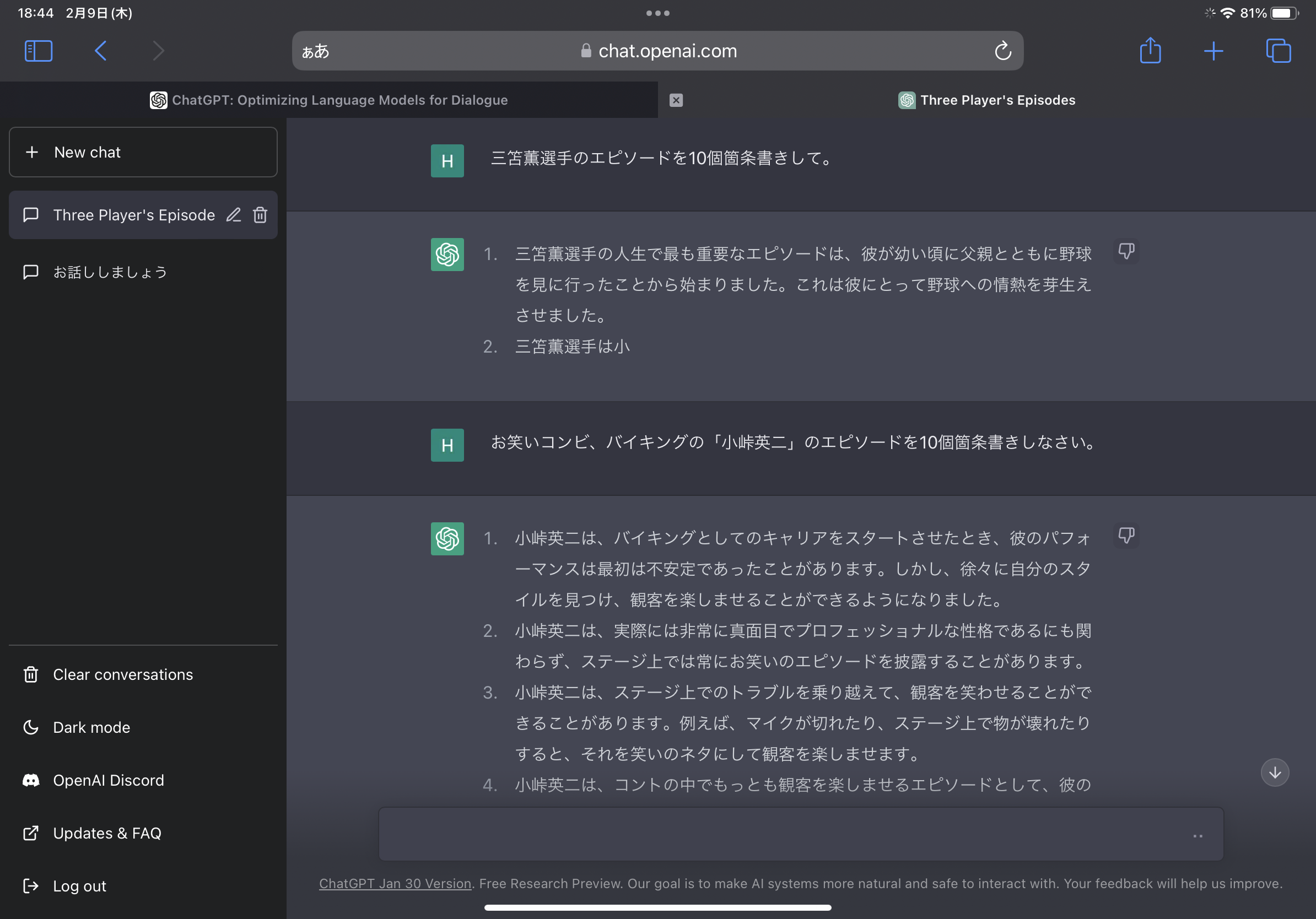
スクレイピングとchatgptを使ったら、将来いろんなことが自動でできるようになるやろうなぁ。その練習や
ちなみにchatgptの現状はこんな感じ。まだギリ大丈夫そうだね。
制作準備
たとえば三笘選手の動画を作る場合に必要な作業を下に並べる
機能分解
| 工程 | script | 機能 |
|---|---|---|
| 0 | 動画を作成する有名人をネットの情報をもとに選択する | |
| 1 | download_wiki.py | 三苫選手のエピソード、逸話をWikipediaから集める |
| 2 | arrange_text.py | 上で取得した文章を適切に要約、加工し小さいピースに分ける |
| 3 | download_image.py | ネットから三苫選手の写真を取得する |
| 4 | cut_image.py | 不適切な写真を排除し、残りを適切な大きさに加工する |
| 5 | make_tile.py | 写真と文章を組み合わせて一つのタイルを作成する |
| 6 | make_video.py | 複数のタイルを組み合わせて動画を作成する |
使う技術、ライブラリ
スクレイピング
Wikipediaの情報収集にはBeautifulSoup、google画像検索の画像収集にはSeleniumを使用。Scrapyを使っても良かったが、わざわざ使うまでもないのと、Seleniumのミドルウェアの使い方がよくわからなかったので却下。
文章要約
pysummarizationを使用。chatgptを使いたかったが、APIがまだ本物じゃないのと、僕が使った範囲ではそんなに精度も高くなかったので却下。上手い質問の仕方が見つかり次第乗り換えたいけどなぁ。
画像編集
OpenCVを使用。ついでにretinafaceを用いて、お試しで人物を中心に画像を切り抜く仕組みを採用。そのせいでかなり重くなったが、まとめ動画としてのクオリティーがあがった。簡単ですごいのね君。たまに混ざる別人を避ける仕組みも作れそうだったが、別人が混じる確率がそんなに高いわけでもないし、重くなること必至なので却下。
動画編集
画像を動画化にOpenCV、音声追加にPymovieを使用。環境構築をてきとーにしたら、fourcc関係でかなり手こずった。最初から仮想環境を整えてしっかりやればよかった。
コード
コードは自分なりに見やすいのを心がけました。main.pyを実行すれば動画が作成されます。
main.py
各ファイルのclassを呼び出し実行する。
import shutil,os,cv2
import numpy as np
from requests.exceptions import HTTPError
from script.download_wiki import downloadWiki
from script.arrange_text import arrangeText
from script.download_image import downloadImage
from script.cut_image import cutImage
from script.make_tile import makeTile
from script.make_video import makeVideo
def delete_files(dir_names):
"""
指定したdir内のファイルを削除する関数
imageにはblank画像が必要なので削除した場合は追加する
"""
for target_dir in dir_names.keys():
if dir_names[target_dir]:
shutil.rmtree(target_dir)
os.mkdir(target_dir)
if target_dir=="images":
#ブランク画像
height = 720
width_tile = 360
width_movie = 1280
blank_tile = np.zeros((height, width_tile, 3))
blank_movie = np.zeros((height, width_movie, 3))
cv2.imwrite('./images/blank_tile.jpg',blank_tile)
cv2.imwrite('./images/blank_movie.jpg',blank_movie)
# delete_files({
# "arranged_wikiList":True,
# "hashtagList":True,
# "images":True,
# "movies":True,
# "squares":True,
# "tiles":True,
# "wikiList":True,
# "wikis":True,
# })
def main(persons,arranged = False,least_num=8):
"""
各ファイルのclassを呼び出し実行する。
"""
for person in persons:
try:
image_num = downloadWiki(person)(least_num)
if arranged:
image_num = arrangeText(person)()
except (ValueError,HTTPError,FileNotFoundError) as E:
print(E)
print(f"人物:{person}--Wikipediaにアクセスできないか、または情報が不十分です--")
continue
try:
downloadImage(person)(image_num)
cutImage(person)()
makeTile(person)()
except (FileNotFoundError,IndexError) as E:
print(E)
print(f"人物:{person}--textが十分でない可能性があります--")
makeVideo(person)()
persons = []
main(persons)
詳細なscript
download_wiki.py
ある有名人のエピソード、逸話をWikipediaから集めファイルに保存
Wikipediaにはエピソードなどその人の情報が綺麗にまとまっているため、スクレイピングは簡単でした。
コード
import requests,re,json
from bs4 import BeautifulSoup
class downloadWiki():
def __init__(self,name):
self.name = name
self.url = "https://ja.wikipedia.org/wiki/"+name
self.soup = None
self.wiki = ""
self.wikiList = []
self.hashtagList = []
self.image_num = 0
def __call__(self,least_num=8) -> int:
"""
エピソードや説明をファイルに保存
エピソード数に合わせて、必要になる写真の枚数を返す
"""
self.get_soup()
self.main()
if self.image_num >= least_num:
self.save_wiki_and_hashtag()
return self.image_num
def get_soup(self):
"""
Wikipediaにアクセスし、HTPLをSopuオブジェクトに変換
"""
r = requests.get(self.url)
# HTTPerror 処理
r.raise_for_status()
self.soup = BeautifulSoup(r.text,"html.parser")
def main(self):
"""
HTML解析
エピソードのあるElementを抽出し、そのTagによって
適切な関数にElementを渡す
"""
# 動画文章抽出
for subNode in self.soup.select("a.vector-toc-link"):
subtitle = subNode.get_text().strip()
check = False
keywords = ["エピソード","プレースタイル","人物","評価"]
for keyword in keywords:
if keyword in subtitle:
check=True
if check:
id = subNode.get("href")
h2_3 = self.soup.select_one(id).parent
# ダサ処理
ul = h2_3.next_sibling.next_sibling
#ul-li形式で書かれている場合
if str(ul).startswith("<ul>"):
self.getEpisode_from_ul(ul)
#pの羅列で書いている場合
else:
self.getEpisode_from_p(ul)
def getEpisode_from_ul(self,ul):
"""
ul Tagの要素からtextを抜き出す
textを update_wiki に渡す
"""
for li in ul.children:
text = li.get_text()
self.update_wiki(text)
def getEpisode_from_p(self,ul):
"""
ul Tagでない要素(pの羅列など)からtextを抜き出す
textを update_wiki に渡す
"""
tag=ul.next_sibling
#hタグまでのp要素を取得
while not str(tag).startswith("<h"):
if str(tag).startswith("<p>"):
text = tag.get_text()
self.update_wiki(text)
tag = tag.next_sibling
def update_wiki(self,text):
"""
textを適切に加工し wikiLIst wikiに保存する
"""
# 引用マーク削除
text = re.sub(r"\[\d*?\]","",text)
# 改行削除
text = re.sub("\n","",text)
# 空じゃないなら
if text:
self.wiki+=text
# textが長すぎる場合前半後半に分割する
if len(text) > 13*10: # 一行13文字 * 10列
for text_ in self.split_text(text):
self.wikiList.append(text_)
self.image_num+=1
else:
self.wikiList.append(text)
self.image_num+=1
def split_text(self,text):
"""
長すぎるエピソードを 。 で区切って分割して返す
"""
chunk = ""
# かぎかっこ内のフラッグ
flag = False
textList = []
for word in text:
if word == "。":
if not flag:
textList.append(chunk)
chunk = ""
else:
chunk+=word
else:
if word == "「":
flag = True
if word == "」":
flag = False
chunk+=word
return textList
def save_wiki_and_hashtag(self):
"""
取得した、エピソード(一つのパラグラフ化したもの)、エピソードのリストを保存する
"""
with open("./wikis/"+self.name+".txt","w") as f:
f.write(self.wiki)
with open("./wikiList/"+self.name+".json","w") as f:
json.dump(self.wikiList,f,ensure_ascii=False)
arrange_text.py
download_wiki.pyで取得した文章を適切に要約、加工し小さいピースに分ける
Wikipediaの情報をただ乗っけるだけだと流石に味気ないなと思い導入。しかし要約==枝葉を取ることになり、動画の面白さが半減したので、最終的には使わなくなった。改善の余地あり。面白さを残しつつまとめるのはChatGPTとかにも難しい部分だとは思うが、上手い質問を見つけ次第、APIを用いて改善したい。
参考記事
コード
import json
from pysummarization.nlpbase.auto_abstractor import AutoAbstractor
from pysummarization.tokenizabledoc.mecab_tokenizer import MeCabTokenizer
from pysummarization.abstractabledoc.top_n_rank_abstractor import TopNRankAbstractor
class arrangeText():
def __init__(self,name,mode="auto"):
self.name = name
self.wikis = ""
self.mode = mode
self.arrange ={"manual":self.manual_arrange,"auto":self.auto_arrange}
self.arranged_wikiList = []
self.image_num = 0
def __call__(self)->int:
"""
Wikipediaで収集した情報を要約して、小さな塊に分けて保存数
その数に合わせて、必要になる写真の枚数を返す
"""
self.open_wikis()
self.arrange[self.mode]()
self.update_json()
return self.image_num
def open_wikis(self):
"""
Wikipediaで収集した情報が保存されたファイルを開き、その内容をwikisに保存する
"""
f = open("./wikis/"+self.name+".txt","r+")
self.wikis= f.read()
# 参考記事 https://resanaplaza.com/2022/05/19/%E3%80%90%E5%AE%9F%E8%B7%B5%E3%80%91python%EF%BC%8Bpysummarization%E3%81%A7%E6%96%87%E6%9B%B8%E8%A6%81%E7%B4%84%EF%BC%88%E3%83%86%E3%82%AD%E3%82%B9%E3%83%88%E3%83%9E%E3%82%A4%E3%83%8B%E3%83%B3/
def auto_arrange(self):
"""
pysummarizationを用いて要約 arraged_wikiListに保存
"""
if self.wikis.count("。")<10:
raise ValueError
# 自動要約のオブジェクトを生成
auto_abstractor = AutoAbstractor()
# トークナイザー(単語分割)にMeCabを指定
auto_abstractor.tokenizable_doc = MeCabTokenizer()
# 文書の区切り文字を指定
auto_abstractor.delimiter_list = ["。"]
# キュメントの抽象化、フィルタリングを行うオブジェクトを生成
abstractable_doc = TopNRankAbstractor()
# 文書の要約を実行
result_dict = auto_abstractor.summarize(self.wikis, abstractable_doc)
for text in result_dict["summarize_result"]:
self.arranged_wikiList.append(text)
self.image_num+=1
def update_json(self):
"""
要約して得た arranged_wikiListをファイルに保存する
"""
f = open("./arranged_wikiList/"+self.name+".json","w")
json.dump(self.arranged_wikiList,f,ensure_ascii=False)
def manual_arrange(self):
"""
お試しで追加した機能、完全自動化したかったので却下
"""
pass
# for i,dict_ in enumerate(self.jsons):
# text = self.input_word(dict_,"text")
# # wikiのエピソードを使うかどうかで場合分け
# if not text:
# continue
# arrange_json={}
# arrange_json["text"] = text
# arrange_json["title"] = self.input_word(dict_,"title")
# self.arranged_wikiList.append(arrange_json)
# def input_word(self,dict_,word):
# # word is text or title
# option = "(変更がない場合はEnterを入力、無視の場合は n と入力)"
# while True:
# if word == "text":
# print("\n---wiki---\n")
# print(dict_["wiki"])
# print("\n---wiki---\n")
# # text 入力の場合のみ option 表示
# str_ = input(word+"を入力してください"+(option if word == "text" else "")+"\n")
# if str_ == "n":
# return None
# if not str_:
# if word =="text":
# str_ = dict_["wiki"]
# else:
# continue
# print("\n\n\n")
# print("\n---"+word+"---\n")
# print(str_)
# print("\n---"+word+"---\n")
# if input("こちらでよろしいですか?{y/n}")=="y":
# return str_
download_image.py
Google画像検索からある有名人の写真を必要枚数だけ取得する
使ってみたかったSeleniumを無理やり使ってみた。やれることは意外と普通。けどすごい楽しい。
エピソードに合わせて写真を選ぶことも考慮して設計したが、最終的には利用しなかった。
また拡張子もてきとーに扱っている。必要になれば変更を加えてほしい。
参考記事
コード
import urllib.request
import os
import time
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.keys import Keys
class downloadImage():
def __init__(self,name):
self.name = name
self.i = 1
self.options = ChromeOptions()
def __call__(self,image_num):
"""
指定された枚数+予備の枚数をgoogle写真検索からdownloadする
"""
spare = 10
self.download_image(image_num + spare)
def download_image(self,image_num=20,keyword=""):
"""
google画像検索から写真を保存する
keyword が指定されている場合はそれも含めて検索する
必要な画像数が多い場合は、適宜スクロールを行いHTMLを更新する
"""
self.options.headless = True
driver = Chrome(options=self.options)
driver.get("https://www.google.com/imghp?hl=ja_JP")
driver.maximize_window()
input_element = driver.find_element_by_name("q")
input_element.send_keys(self.name+" "+keyword if keyword else self.name)
input_element.send_keys(Keys.RETURN)
assert "Google" in driver.title
#参考記事 https://qiita.com/Cartelet/items/2f54965850c201f4fb96
if image_num > 30:
for t in range(5):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(1.5)
try:driver.find_element_by_class_name("mye4qd").click() #「検索結果をもっと表示」ってボタンを押してる
except:pass
if image_num > 150:
for t in range(5):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(1.5)
# driver.save_screenshot("search_results.png")
dirpath = "./images/"+self.name
if not os.path.exists(dirpath):
os.mkdir(dirpath)
for imgNode in driver.find_elements_by_css_selector("div.bRMDJf > img"):
if self.i > image_num:
driver.quit()
return
url = imgNode.get_attribute("src")
if url:
r = urllib.request.urlopen(url)
# 画像ファイル種類を判別して保存できればいいなぁ
with open (dirpath+"/"+self.name+str(self.i)+".jpg","wb") as f:
f.write(r.read())
self.i+=1
cut_image.py
download_image.pyで取得した画像のうち、複数人写ってる場合は無視し、残りを顔を中心に切り出す。
顔認識にはRetinafaceを利用、簡単に利用できて結構高性能。これ使えるで!!
参考記事
コード
from retinaface import RetinaFace
import cv2,os,glob
import matplotlib.pyplot as plt
class cutImage():
def __init__(self,name):
self.name = name
self.square_num = 1
def __call__(self):
"""
画像をファイルを読み込み、適切なものを選択する
その後正方形に変換して保存する
"""
files = glob.glob("./images/"+self.name+"/*")
for img_path in files:
cut_img = self.arrange_to_square(img_path)
if not cut_img is None:
self.save_square(cut_img)
# 参考記事 https://self-development.info/%E3%80%90python%E3%80%91retinaface%EF%BC%88retina-face%EF%BC%89%E3%81%AB%E3%82%88%E3%82%8B%E9%A1%94%E8%AA%8D%E8%AD%98/#:~:text=%E3%81%A6%E3%81%84%E3%81%8D%E3%81%BE%E3%81%99%E3%80%82-,RetinaFace%EF%BC%88retina%2Dface%EF%BC%89%E3%81%A8%E3%81%AF%EF%BC%9F,%E8%AA%8D%E8%AD%98%E3%83%A9%E3%82%A4%E3%83%96%E3%83%A9%E3%83%AA%E3%81%A8%E3%81%84%E3%81%86%E3%81%93%E3%81%A8%E3%81%A7%E3%81%99%E3%80%82
def arrange_to_square(self,img_path):
"""
顔を左右の中心にして360*360に切り出す
顔が複数検知された場合はその写真を無視する
"""
img= cv2.imread(img_path)
resp = RetinaFace.detect_faces(img_path, threshold = 0.95)
# 顔が複数なら
if len(resp) !=1:
return None
# 顔が「左右」の中心にくるように画像を切り取る
facial_area = resp["face_1"]["facial_area"]
face_xcenter = (facial_area[0]+facial_area[2])/2
face_ycenter = (facial_area[1]+facial_area[3])/2
img_height,img_length,_ = img.shape
xcenter_to_side = min(face_xcenter,img_length - face_xcenter)
# 顔が左右の中心になるように画像を切り取ったとき、その画像が縦長か、横長か判定する
portrait = img_height > xcenter_to_side*2
# 縦長なら
if portrait:
# 横幅を正方形の長さとして、画像を切り出す
face_in_upper_side = face_ycenter < img_height/2
starty = 0 if face_in_upper_side else img_height - 2*xcenter_to_side
endy = 2*xcenter_to_side if face_in_upper_side else img_height
cut_img = img[int(starty):int(endy),int(face_xcenter-xcenter_to_side) : int(face_xcenter+xcenter_to_side)]
pass
else:
# 縦幅を正方形の長さとして、画像を切り出す
cut_img = img[:,int(face_xcenter-img_height/2) : int(face_xcenter+img_height/2)]
# 画像サイズを360*360に変えて出力する
return cv2.resize(cut_img,(360,360))
def save_square(self,tile):
"""
得られた正方形の写真を保存する
"""
dirpath = "./squares/"+self.name
if not os.path.exists(dirpath):
os.mkdir(dirpath)
tile_path = dirpath + "/" + self.name +str(self.square_num) + ".jpg"
cv2.imwrite(tile_path,tile)
self.square_num+=1
make_tile.py
写真と文章を組み合わせて一つのタイルを作成する
tileごとにタイトルがある場合は実装はしてない。各自アレンジしてください!
参考記事
コード
import cv2,json,os,glob
import numpy as np
from PIL import Image, ImageDraw, ImageFont
class makeTile():
def __init__(self,name,arranged = False,title = False):
self.name = name
self.title = title
self.blank_tile = cv2.imread('./images/blank_tile.jpg')
self.font_path = "./07やさしさゴシック.ttf"
self.wikiList = None
self.tile_num = 1
self.arranged = arranged
def __call__(self):
"""
エピソードと写真を取得し、それらを組み合わせてtileを作成する。
"""
self.open_wikiList()
files = glob.glob("./squares/"+self.name+"/*")
for i,img_path in enumerate(files):
#title によって場合分けを今後追加したい
tile = self.make_tile(img_path,self.title)
try:
text = self.wikiList[i-1]
except IndexError:
raise IndexError("textが不十分です")
lineList = self.convert_to_lineList(text)
y_start = 0 if self.title else 360
final_tile = self.put_text(tile, lineList, y_start, fontFace=self.font_path, fontScale=25, color=(255,255,255))
if final_tile is None:
return
self.save_tile(final_tile)
def open_wikiList(self):
"""
保存したwikiListをロードする
arrangedしたものを使うかによってロードするファイルを変える
"""
if self.arranged:
f = open("./arranged_wikiList/"+self.name+".json","r")
else:
f = open("./wikiList/"+self.name+".json","r")
self.wikiList= json.load(f)
def make_tile(self,img_path,title):
"""
正方形の写真を縦長の黒い画像と合成してtileの下地を作る
"""
img = cv2.imread(img_path)
if img is None:
return None
if title:
return None
else:
if not img.shape[0] == img.shape[1] == 360:
raise ValueError("写真の大きさが不適切です")
tile = self.blank_tile
# 画像の合成
tile[0:img.shape[0], 0:img.shape[1]] = img
return tile
# 参考記事 https://qiita.com/mo256man/items/82da5138eeacc420499d
def put_text(self,tile, lineList, y_start, fontFace, fontScale, color):
"""
文章リスト、フォントのファイルパス、大きさ、色を取得して適切な場所に配置する
"""
img_height,img_length,_ = tile.shape
imgPIL = Image.fromarray(tile)
draw = ImageDraw.Draw(imgPIL)
line = len(lineList)
# lineが多い時はmarginを小さく
margin = 1.5 if line<=8 else 1.3
# lineがかなり多い時はfontsizeを小さく
if line >10:
fontScale = 20
fontPIL = ImageFont.truetype(font = fontFace, size = fontScale)
for i,text in enumerate(lineList):
w, h = draw.textsize(text, font = fontPIL)
if i == 0:
y_center = (y_start+img_height)/2
textbox_height = h*margin*line
line_start = y_center - textbox_height/2
draw.text(xy = ((img_length-w)/2,line_start+h*margin*i), text = text, fill = color, font = fontPIL)
return np.array(imgPIL, dtype = np.uint8)
def convert_to_lineList(self,text,max_word_num = 13):
"""
文章を10文字ずつに切り分けてリストに変換する
"""
line = len(text)//max_word_num
# mecab を用いて、切り方の工夫しても良い
lineList = [text[i*max_word_num:((i+1)*max_word_num if i!=line else len(text))] for i in range(0,line+1)]
return lineList
def save_tile(self,tile):
"""
作ったtileをファイルに保存する
"""
dirpath = "./tiles/"+self.name
if not os.path.exists(dirpath):
os.mkdir(dirpath)
tile_path = dirpath + "/" + self.name +str(self.tile_num) + ".jpg"
cv2.imwrite(tile_path,tile)
self.tile_num+=1
make_video.py
複数のタイルを組み合わせて動画を作成する
opencvだけでやりきりたかったが、音声の合成にはpymovieが必須でした。残念...
あと環境構築怠ったせいで本当に痛い目みました。みなさんは気をつけましょう。
コード
import cv2,glob
import numpy as np
import moviepy.editor as mp
from PIL import Image, ImageDraw, ImageFont
class makeVideo():
def __init__(self,name,fps = 30,required_time = 15):
self.name = name
self.tiles = []
self.video = None
self.font_path = "./07やさしさゴシック.ttf"
self.fps = fps
self.required_time = required_time
self.blank_movie = cv2.imread("./images/blank_movie.jpg")
self.blank_tile = cv2.imread("./images/blank_tile.jpg")
self.title_tile = None
def __call__(self):
self.open_tiles()
self.add_title_tile()
self.set_video()
self.add_frame()
self.video.release()
self.add_song()
def open_tiles(self):
"""
作成したtileをロードする
最後残像が残らないためにblank tileを追加する
"""
files = glob.glob("./tiles/"+self.name+"/*")
for tile_path in files:
self.tiles.append(cv2.imread(tile_path))
self.tiles.append(self.blank_tile)
def set_video(self):
"""
videoWriterの初期設定を行う
"""
self.video = cv2.VideoWriter('./movies/'+self.name+'.mp4',
cv2.VideoWriter_fourcc(*"mp4v"),
self.fps, (1280, 720))
# 参考記事 https://qiita.com/mo256man/items/82da5138eeacc420499d
def add_title_tile(self):
"""
title(三笘薫 エピソード など)と書かれたtileを作成しtitle_tileに保存数
"""
fontFace = self.font_path
fontScale = 100
color=(255,255,255)
title = self.name+" エピソード"
camera_height,camera_length,_ = self.blank_movie.shape
imgPIL = Image.fromarray(self.blank_movie)
draw = ImageDraw.Draw(imgPIL)
fontPIL = ImageFont.truetype(font = fontFace, size = fontScale)
w, h = draw.textsize(title, font = fontPIL)
draw.text(xy = ((camera_length-w)/2,(camera_height-h)/2), text = title, fill = color, font = fontPIL)
self.title_tile = np.array(imgPIL, dtype = np.uint8)
def add_frame(self):
"""
作成したtitle_tile、tileを映像化する。
tileが並んだ長い壁を、カメラが動きながら写すイメージ
"""
# 最初の数秒はtitleを見せる
first_second = 2
for _ in range(first_second*self.fps):
self.video.write(self.title_tile)
start_line = 1280
tile_length = 360
camera_length = 1280
# それぞれのtileの右端の位置
tiles_pos = [start_line + tile_length * i for i in range(len(self.tiles))]
# blankでないtileの右端を得る
last_tile_left = tiles_pos[-1]
# カメラが1frameごとに進むスピード
camera_speed = int(camera_length/(self.fps*self.required_time))
# カメラの左端の位置
camera_left = 0
# そのあと動き出す
while camera_left <= last_tile_left:
frame = self.blank_movie
# titleについて
if camera_left <= camera_length:
frame[0:self.title_tile.shape[0],0:camera_length - camera_left] = self.title_tile[:,camera_left:camera_length]
# tileについて
for tile,tile_pos in zip(self.tiles,tiles_pos):
# カメラの画角にtileがある場合は
if camera_left <= tile_pos + tile_length and tile_pos <= camera_left + camera_length :
# 画面上のtileの位置
left_pos = tile_pos-camera_left
right_pos = left_pos + tile_length
# tileの表示範囲
tile_start = 0
tile_end = tile_length
# tileが見切れている場合
if left_pos <= 0:
tile_start = - left_pos
left_pos = 0
if right_pos >= camera_length:
tile_end = camera_length - left_pos
right_pos = camera_length
# tileを画面の指定位置に描画
frame[0:tile.shape[0],left_pos:right_pos] = tile[:,tile_start:tile_end]
self.video.write(frame)
camera_left += camera_speed
def add_song(self,bgm_num=1):
"""
完成した動画に音声を追加して保存する。
コーディックの関係で一度出力してから再度読み込み音声を合成する。
権利関係等でめんどくさい実装になった。
"""
video_path ='./movies/'+self.name+'.mp4'
chumk_path = "./movies/aaa.mp4"
clip = mp.VideoFileClip(video_path).subclip()
clip.write_videofile(chumk_path)
# mp4 H.264に変換
new_clip = mp.VideoFileClip(chumk_path).subclip()
duration = new_clip.duration
last_second = 5
audio_clip = mp.AudioFileClip("./songs/bgm1.mp3").subclip(0,duration+last_second)
new_clip.set_audio(audio_clip).write_videofile(video_path)
おわりに
制作をおえて
一週間弱で制作できたので自分の成長を感じる。ふんいきオブジェクト指向だったけど、すごい開発が楽になって感動した。もうちょっと勉強したいな。
今後やりたいこと
- 収集先を2ch、Yahoo Newsなど多様化
- ChatGPTを用いたいい感じの要約
など。
それでは!