ニューラルネットワークの学習で、自宅PCだと1日で終わらない学習もあると思います。
ずっと学習させていたつもりが、途中でフリーズしていたり、落ちたりすることもあると思います。
そして最初からやり直しで、仕事が進まないことは、多くの人が経験していると思います。
そんな時に便利な、時間のかかる学習を履歴を残しつつ進める方法について調べたので、もしよかったら参考にどうぞ。
まずはライブラリをインポートします。
import pandas as pd
import seaborn as sns
import random
import tensorflow as tf
from keras.datasets import cifar10
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from tensorflow.keras.models import load_model
シードを固定します。
ハードウェアが異なると、固定しきれない場合があります。
random.seed(0)
tf.random.set_seed(0)
サンプルとしてCIFAR-10のデータを使います。
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
Y_train = np_utils.to_categorical(y_train, 10)
Y_test = np_utils.to_categorical(y_test, 10)
モデルを、それっぽく定義します。
model = Sequential()
model.add(Convolution2D(32, (3, 3), padding='same', input_shape=(32, 32, 3)))
model.add(Activation('relu'))
model.add(Convolution2D(32, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Convolution2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Convolution2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Activation('softmax'))
損失関数、最適化手法、評価関数をセットします。
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
ここまでは一般的な流れだと思います。
ModelCheckpointとCSVLogger
ここからがポイントです。
ModelCheckpointとCSVLoggerを利用します。
ModelCheckpointは、エポックごとにモデルを保存できます。
途中のフリーズでも、事件でもなんのそのです。
最高のモデルのみ保存、数エポックごとに保存など、便利なパラメータも揃っています。
CSVLoggerは、学習履歴をログとして出力できます。
公式URL:https://keras.io/ja/callbacks/
それでは、ModelCheckpointとCSVLoggerをつかって学習しましょう。
学習(1~5エポック目)
# インポート
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.callbacks import CSVLogger
# ModelCheckpointで、保存されるモデルのファイル名を「model.h5」に指定
checkpoint_callback = ModelCheckpoint(filepath='model.h5')
# CSVLoggerで、保存されるログファイル名を「training.csv」に指定
# ここで継続的にログを書き込んでいくためにappend=Trueにすること
csv_logger = CSVLogger('training.csv', append=True)
# 学習(1~5エポック目)
model.fit(X_train, Y_train,
batch_size=128,
epochs=5,
verbose=1,
validation_split=0.1,
# callbacksとしてインスタンス化したModelCheckpointとCSVLoggerを指定
callbacks=[checkpoint_callback, csv_logger],
)
出力

epoch,accuracy,loss,val_accuracy,val_loss
0,0.39604443311691284,1.650077223777771,0.5537999868392944,1.2515175342559814
1,0.5685555338859558,1.210105538368225,0.6571999788284302,0.9866605401039124
2,0.635533332824707,1.0243295431137085,0.6930000185966492,0.8739074468612671
3,0.6847333312034607,0.8934160470962524,0.7211999893188477,0.7787957191467285
4,0.711222231388092,0.8184868097305298,0.7440000176429749,0.7249084711074829
「model.h5」も、もちろん保存されています。
学習(6~8エポック目)
# 学習(6~8エポック)
model.fit(X_train, Y_train,
batch_size=128,
verbose=1,
validation_split=0.1,
# 次は8エポック目まで進めるよという意味
epochs=8,
# 前回5エポック目まで進めたよという意味
initial_epoch=5,
# 初回学習と同様にcallbacksをセット
callbacks=[checkpoint_callback, csv_logger],
)
出力

epoch,accuracy,loss,val_accuracy,val_loss
0,0.39604443311691284,1.650077223777771,0.5537999868392944,1.2515175342559814
1,0.5685555338859558,1.210105538368225,0.6571999788284302,0.9866605401039124
2,0.635533332824707,1.0243295431137085,0.6930000185966492,0.8739074468612671
3,0.6847333312034607,0.8934160470962524,0.7211999893188477,0.7787957191467285
4,0.711222231388092,0.8184868097305298,0.7440000176429749,0.7249084711074829
5,0.7365333437919617,0.7465818524360657,0.7613999843597412,0.6823656558990479
6,0.759755551815033,0.6843014359474182,0.7662000060081482,0.6644566655158997
7,0.7738666534423828,0.6426085233688354,0.7634000182151794,0.6754271388053894
model.history.historyでは、直近3エポック分しか確認できませんが、
training.csvには、計8エポック分の学習履歴が記録されています。
「model.h5」も、引き続き、エポックごとに上書き保存されています。
可視化しても、違和感ありません。
df = pd.read_csv('training_003.csv')
sns.lineplot(data=df[['loss', 'val_loss']])
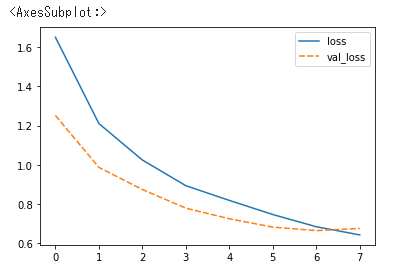
モデルをロードして、学習(9~11エポック)
モデルの保存とロードを挟んでも、もちろん学習記録を蓄積できます。
model_loaded = load_model('model.h5')
# モデルをロードして、学習(9~11エポック)
model.fit(X_train, Y_train,
batch_size=128,
verbose=1,
validation_split=0.1,
# 次は11エポック目まで進めるよという意味
epochs=11,
# 前回8エポック目まで進めたよという意味
initial_epoch=8,
# 初回学習と同様にcallbacksをセット
callbacks=[checkpoint_callback, csv_logger],
)
出力

epoch,accuracy,loss,val_accuracy,val_loss
0,0.39604443311691284,1.650077223777771,0.5537999868392944,1.2515175342559814
1,0.5685555338859558,1.210105538368225,0.6571999788284302,0.9866605401039124
2,0.635533332824707,1.0243295431137085,0.6930000185966492,0.8739074468612671
3,0.6847333312034607,0.8934160470962524,0.7211999893188477,0.7787957191467285
4,0.711222231388092,0.8184868097305298,0.7440000176429749,0.7249084711074829
5,0.7365333437919617,0.7465818524360657,0.7613999843597412,0.6823656558990479
6,0.759755551815033,0.6843014359474182,0.7662000060081482,0.6644566655158997
7,0.7738666534423828,0.6426085233688354,0.7634000182151794,0.6754271388053894
可視化
df = pd.read_csv('training_003.csv')
sns.lineplot(data=df[['loss', 'val_loss']])
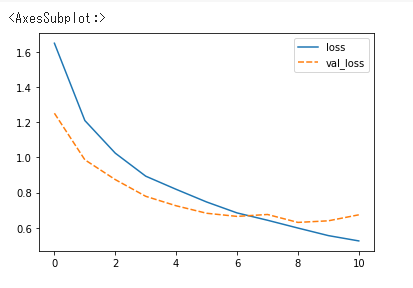
おまけ(私が制作したものの紹介)
これで、学習させながら安心してマクドでもいけそうです。
AI、機械学習は、エンジニアだけじゃなく、ビジネスサイドにも面白いよって広めていこうね。
👇私が制作したものです。もしご興味あれば見てみてください。
https://www.udemy.com/course/aiforbiz/?referralCode=67BB575DF596D8903B08