予測したいこと 笑ってはいけない2020では誰が何回シバかれるのか?
年末ですね!年末といえば、みんだ大好きガキ使 笑ってはいけないシリーズ。
番組公式ページによると、今年のテーマは「大貧民GoToラスベガス」だそうです。
https://www.ntv.co.jp/gaki/special/index.html

※上の画像は番組公式HPより
ご存じの通り、笑ったらシバかれるというルールですが、
2020年は誰が何回シバかれるのか?
これをDataRobotのAutoMLを利用して予測してみたいと思います。
ところでDataRobotって何?
公式ページ(https://www.datarobot.com/jp/)にいろいろ書いていますが、
DataRobotのYouTubeチャンネル(https://www.youtube.com/channel/UCua787KW7PkcsmpB7Z72PnQ)がメチャ具体的にイメージしやすいです。
※上の画像はDataRobotJP YouTubeチャンネルより
DataRobotJP YouTubeチャンネルを聞いているとこんな話な説明がありました。
AIを利用してデータから価値創出するには次の3STEPがある。
- データ準備
- データのモデル化 + 予測モデルの構築
- 構築したモデルを実際のビジネスに適応
難易度が高くデータサイエンティストじゃない難しいのだが、DataRobotは機械学習の自動化でAIの民主化を推進し、プロセス全体を自動化しているのだ。
そう、つまり、機械学習にそんな詳しくない私にも何とかできちゃうということである。
そして無料トライアルも可能だ。
https://www.datarobot.com/jp/trial/
DataRobotによるAutoML分析の流れの全体像
DataRobotには先ほど記載した3STEP「データ準備」「データのモデル化 + 予測モデルの構築」「構築したモデルを実際のビジネスに適応」のそれぞれの機能がありますが、
今回は「データのモデル化 + 予測モデルの構築」の機能を利用してガキ使予測してみる。
大まかな順番は以下の通りだ。
- データ分析の戦略を立てる
- 過去のデータを準備する
- 準備した過去のデータをDataRobotに取り込む
- DataRobotに予測モデルを作らせる
- ベストな予測モデルを選ぶ
- 予測モデルで結果を予測する
では早速いってみましょう!
1. データ分析の戦略を立てる
まずはデータ分析の戦略を立てます。
つまり**「何」をインプットして「シバかれる回数」をアウトプットするのか**を明確にします。
シバかれる回数に影響を与えそうな要素は、いろいろありそうです。
- 誰なのか(松本?浜田?方正?遠藤?田中?)
- 笑いの刺客(ゲスト出演者)は誰か?
- 何回目の笑ってはいけないシリーズか?
- 何年の放送か?
- タイトルは何か?
- 撮影日はいつか?
- 出演者のその年のイベントは?(結婚とか離婚とかをいじられるケースが多い)
などなど。
ただし、2020年分を予測するときにデータとしてインプットできる必要があるので、今時点で具体的に分かっているものである必要があります。
なので、インプット情報を下記とすることに決めました。
- シリーズNo(第何回か?)
- 開催年
- 番組タイトル
- 本名
- その年に結婚したか?
- その年に離婚したか?
- 笑ってはいけないのゲーム時間(最近は24時間だが、昔は15時間とかだった)
あくまでもこれは私の戦略であって、この「何をインプット情報とするか」は分析者の考え方や手に入れることができるデータ範囲によって異なります。
このプロセスはデータ分析の成否を握る重要なポイントの一つなんでじっくり検討しましょう!
2. 過去のデータを準備する
インプットする情報が決まったので、過去のデータを集めます。
具体的には2019年までのインプット情報とアウトプット情報のデータセットを作成するということです。
今回は下記のサイトから情報収集しました。
松本人志
https://ja.wikipedia.org/wiki/%E6%9D%BE%E6%9C%AC%E4%BA%BA%E5%BF%97
浜田雅功
https://ja.wikipedia.org/wiki/%E6%B5%9C%E7%94%B0%E9%9B%85%E5%8A%9F
月亭方正
https://ja.wikipedia.org/wiki/%E6%9C%88%E4%BA%AD%E6%96%B9%E6%AD%A3
遠藤章造
https://ja.wikipedia.org/wiki/%E9%81%A0%E8%97%A4%E7%AB%A0%E9%80%A0
で集めた情報をExcelにまとめます。
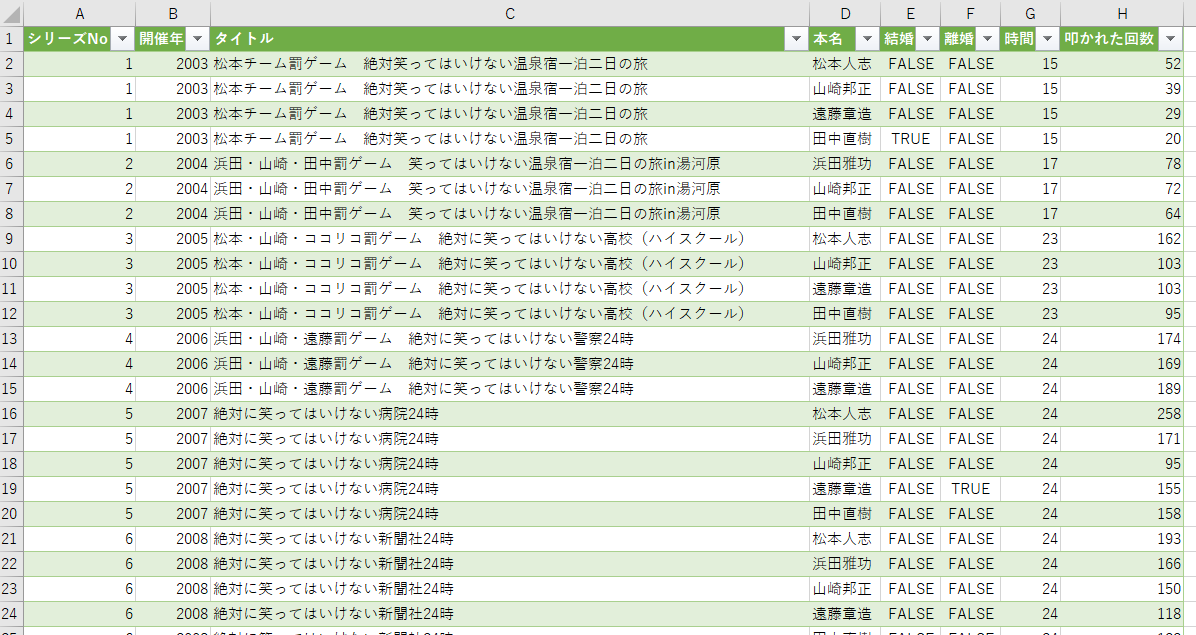
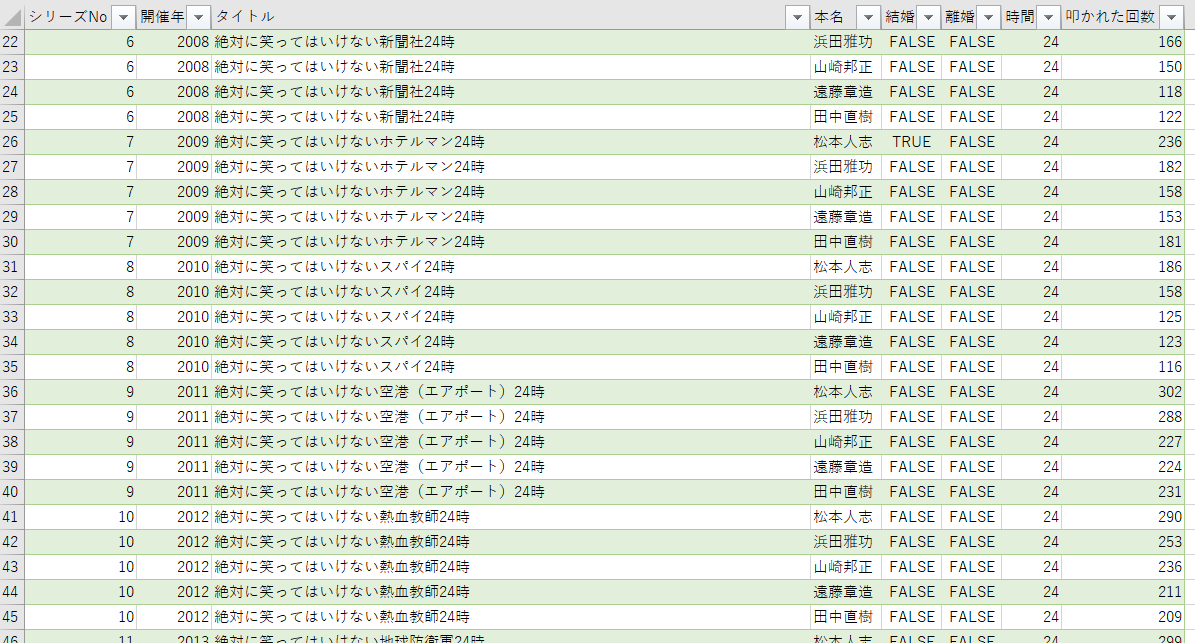
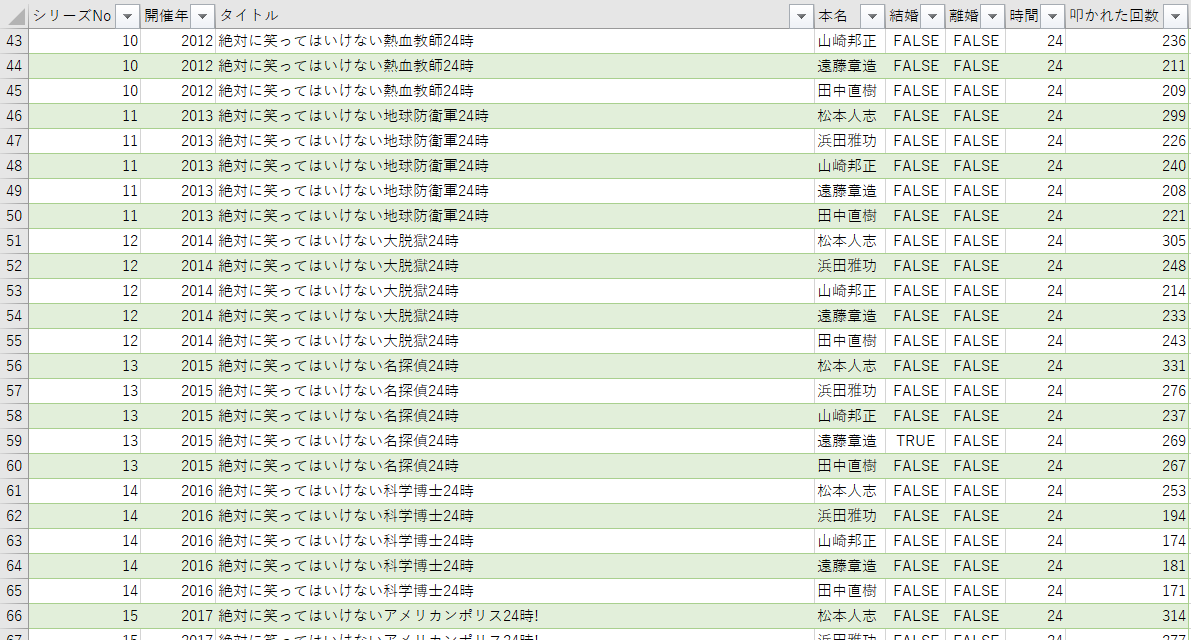
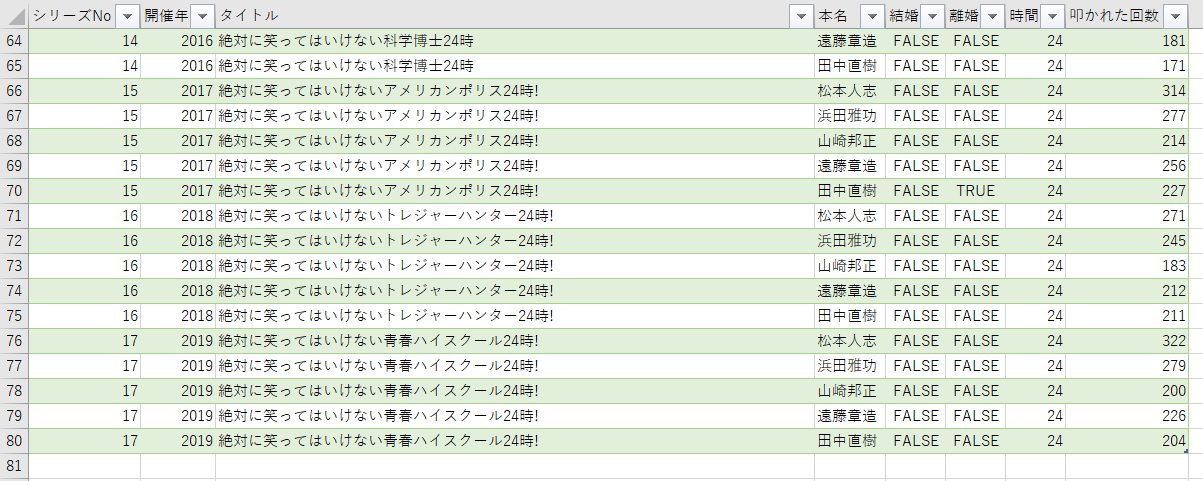
3. 準備した過去のデータをDataRobotに取り込む
準備した過去のデータをDataRobotに取り込んでいきます。
まずはDataRobotのプラットフォームにアクセスし、プロジェクトを作成します。
機械学習の開発を選び、続けるをクリックします。
作成したExcelをドラッグします。
すると自動で下記のような感じにデータが取り込まれています。
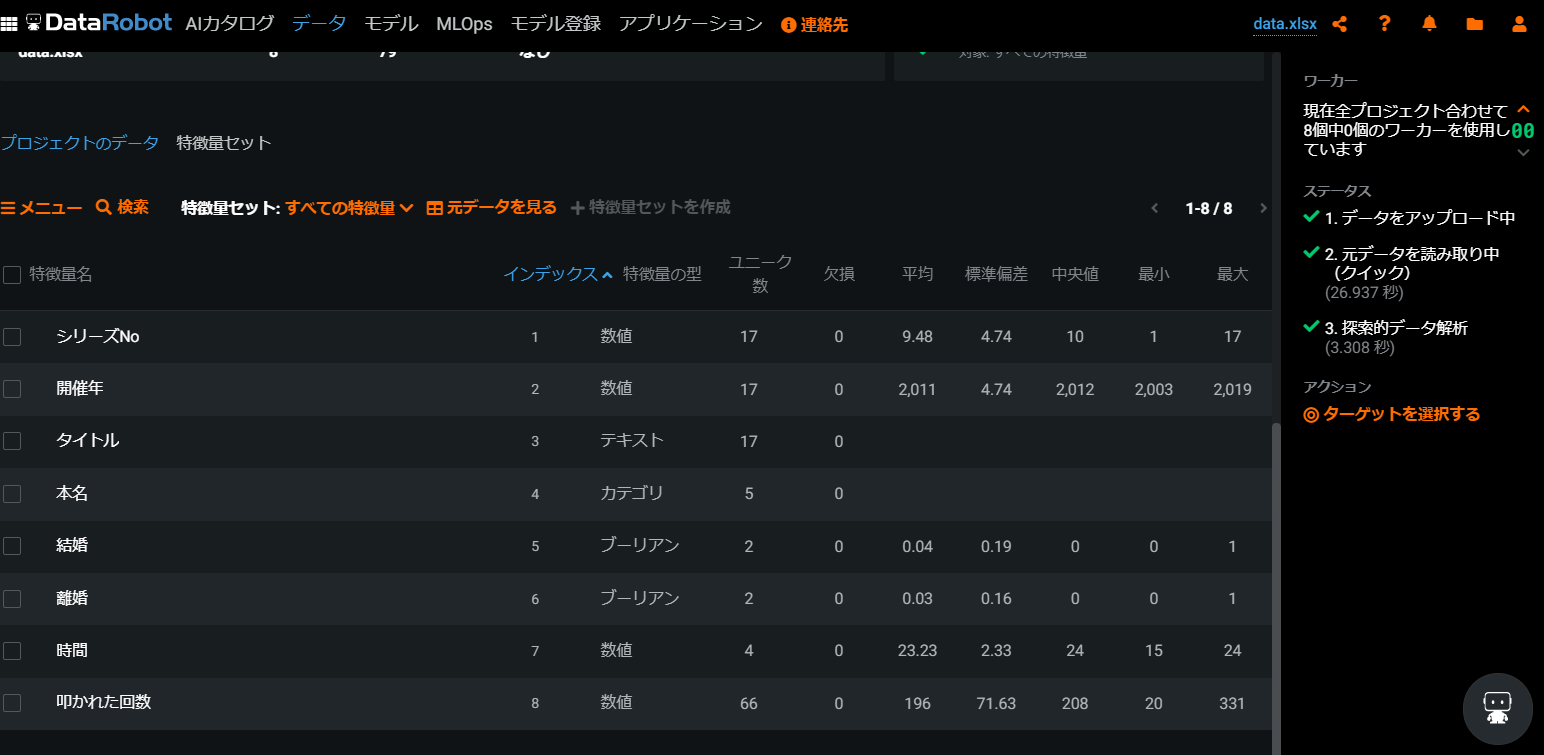
特徴量名(取り込んだデータのヘッダー名称)をクリックするとデータ状況が可視化されています。
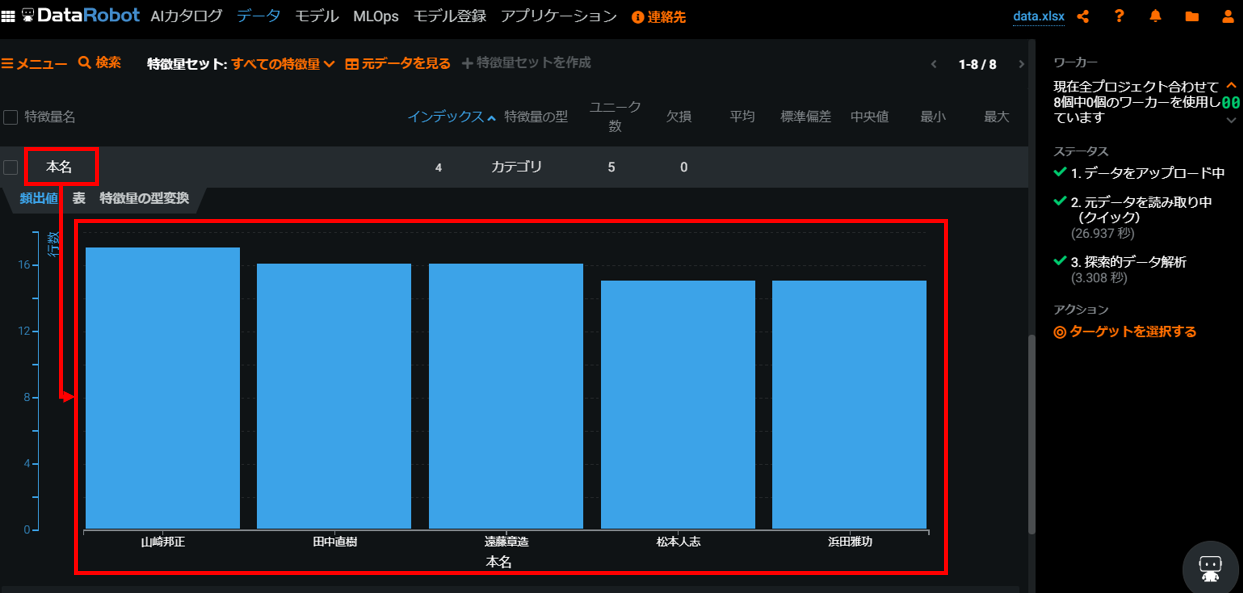
4. DataRobotに予測モデルを作らせる
次に読み込んだデータをもとに予測モデルを作っていきます。
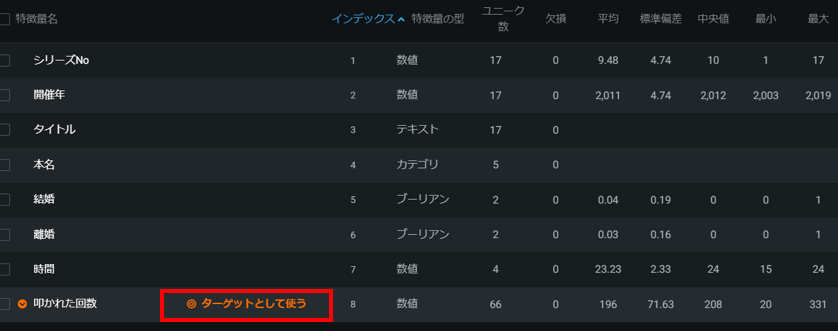
まずは「何を予測するか」を指定します。
今回は叩かれた回数を予測したいので、「叩かれた回数」にマウスオーバーして「ターゲットとして使う」クリックします。
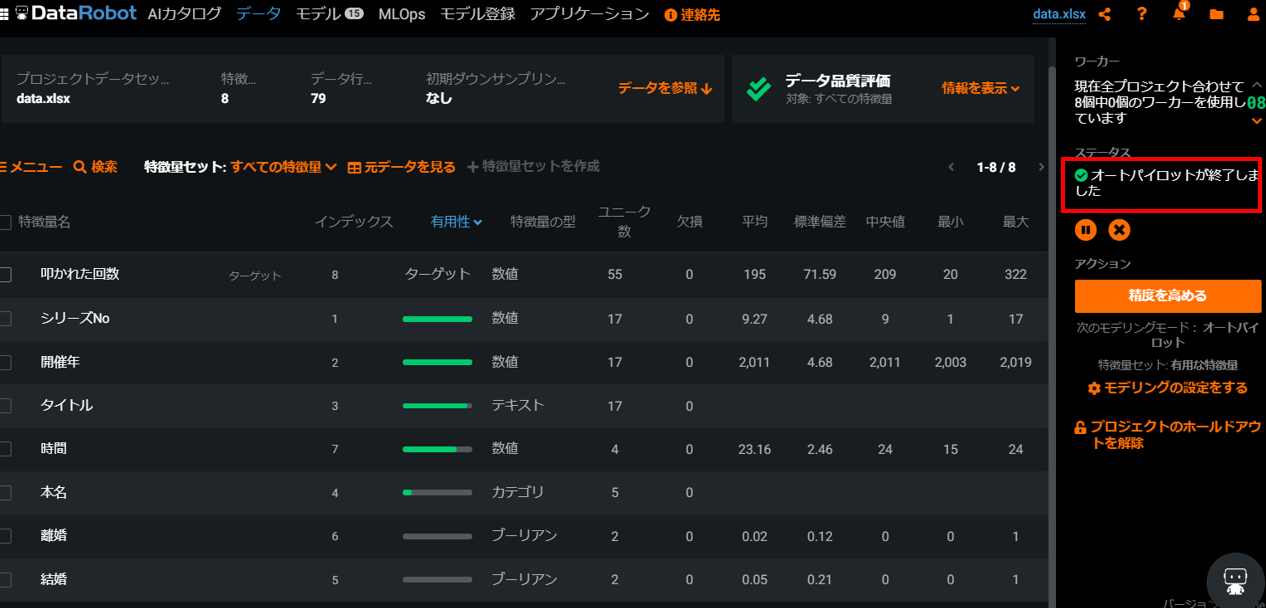
すると下記のような感じで、何を予測しますか?のところに「叩かれた回数」が表示されます。あとは「開始」ボタンをクリックすると、DataRobotが自動で予測モデルを作ってくれます。

右のカラムで「オートパイロットが終了しました」と表示されたら予測モデル構築完了です。
5. ベストな予測モデルを選ぶ
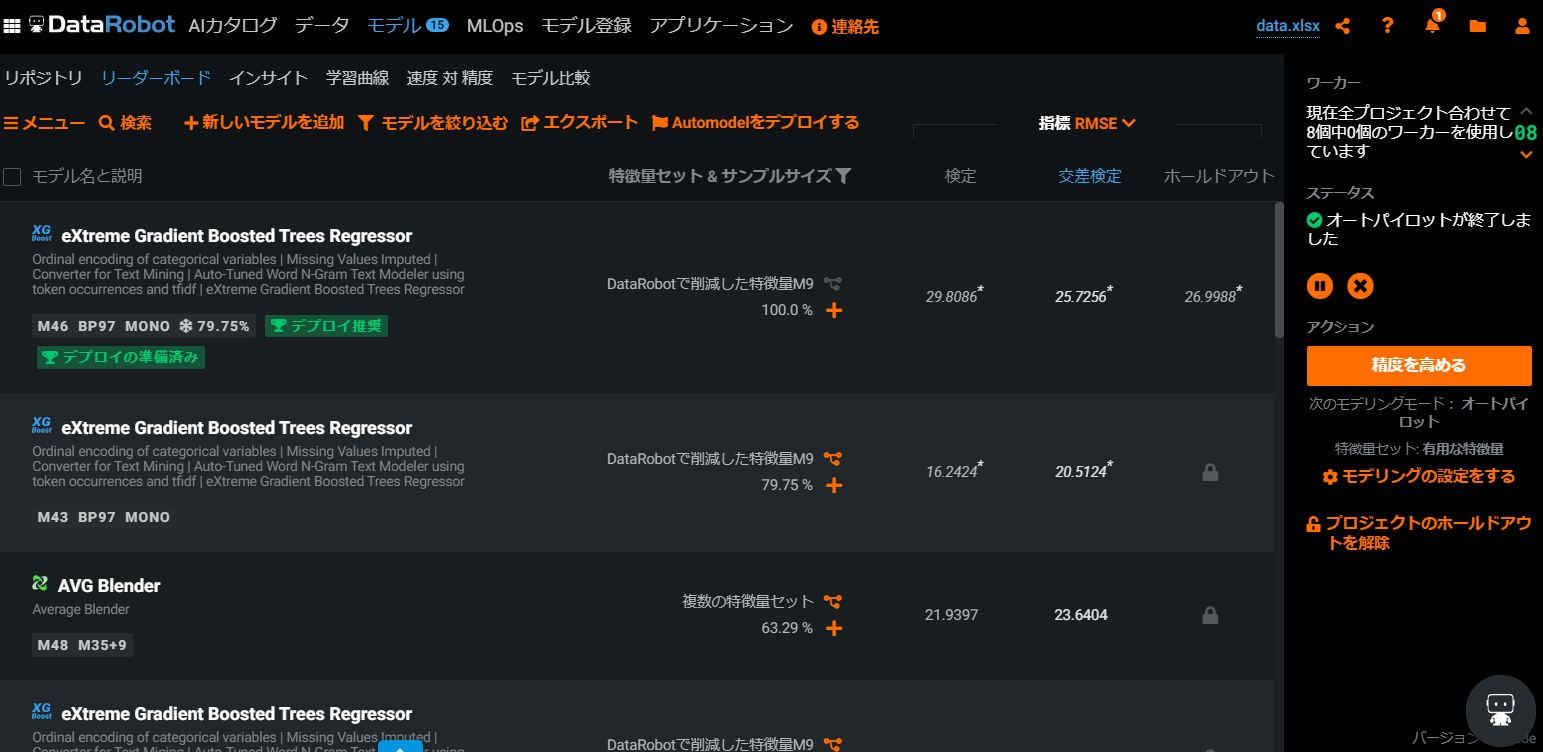
モデルをクリックすると作成された予測モデルの一覧が表示されます。
分析者本人がこの中から最適な予測モデルを選択する必要があります。
どのような基準でモデルを選べばよいのでしょうか?
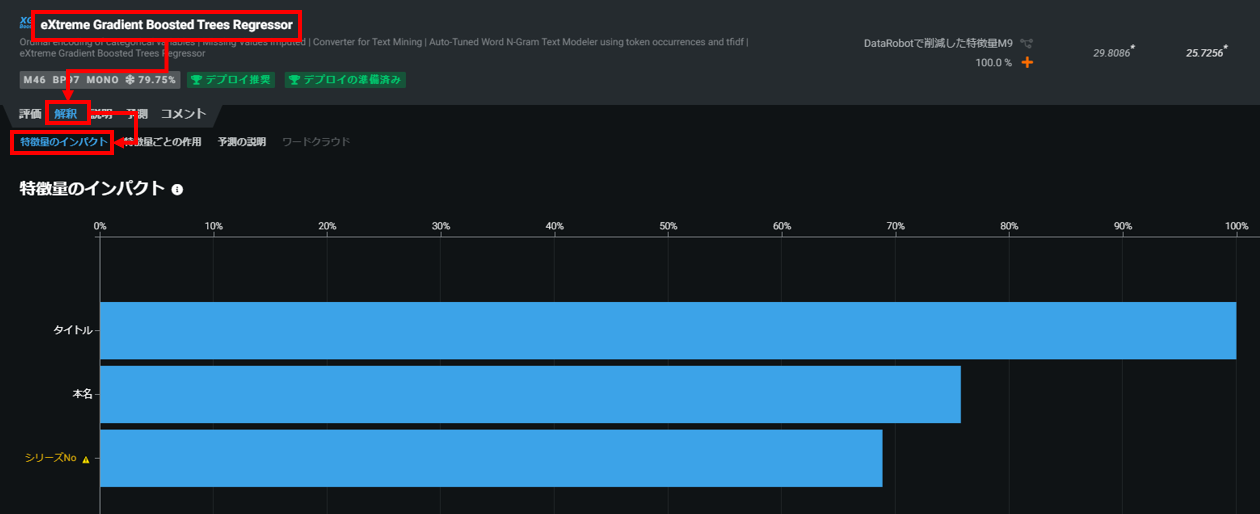
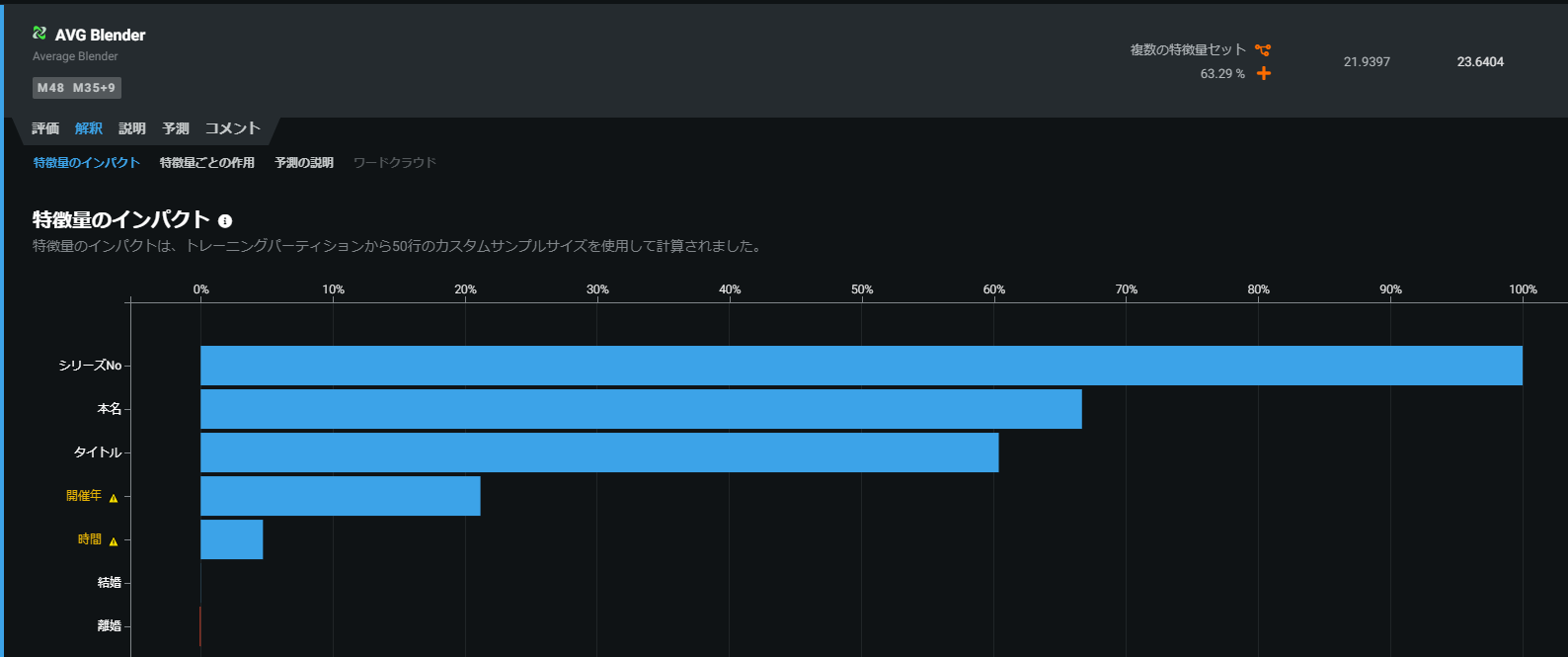
各モデルの特報量(インプット情報)のターゲット(叩かれた回数)へのインパクトを可視化することができます。
各モデル名をクリック > 解釈をクリック > 特徴量のインパクトをクリック
DataRobotがおすすめ順に並べてくれていますので、上からいくつか特徴量のインパクトを見ていきましょう。
eXtreme Gradient Boosted Trees Regressor
AVG Blender
RuleFit Regressor
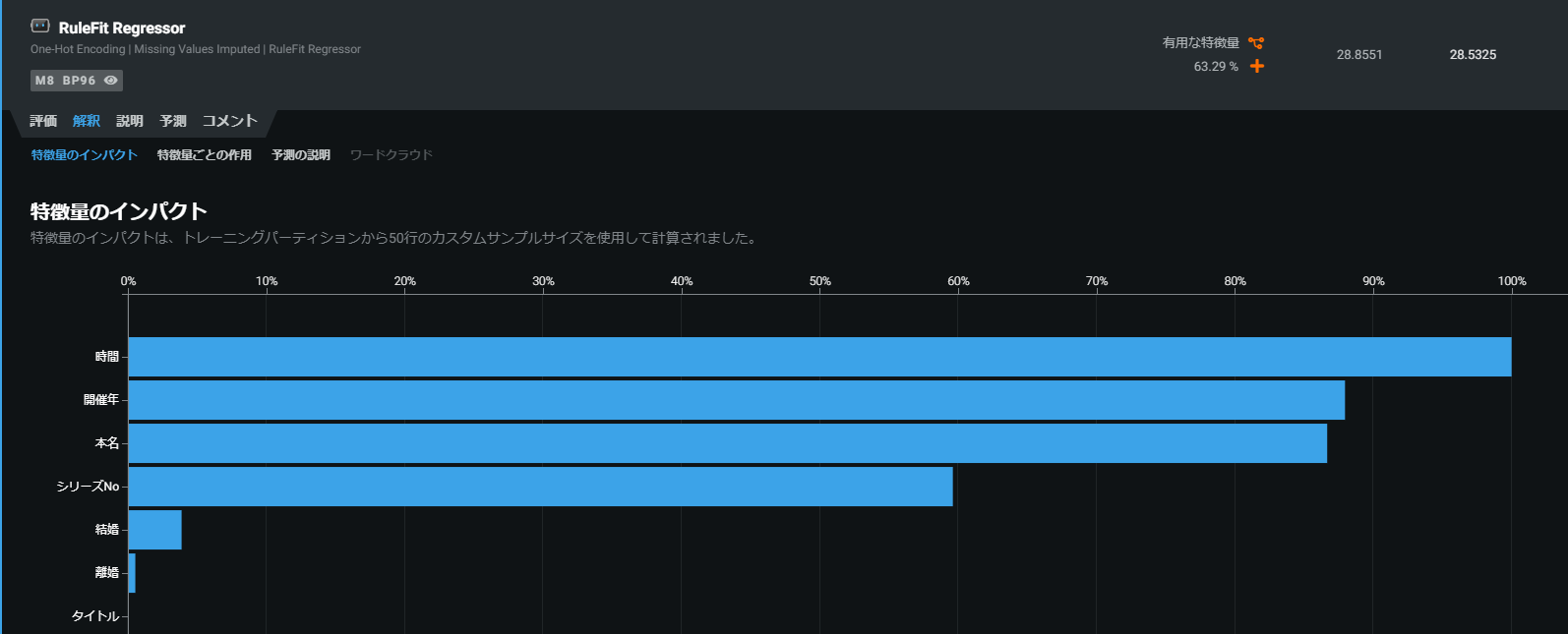
叩かれる回数はゲーム時間にもちろん影響を受けるだろうし、開催年(あるいはシリーズ回数)ごとに叩かれる回数は増えてく傾向は見て取れ、またレギュラーメンバーによって叩かれる回数は影響をうけそうなので、この傾向を色濃く表現している「RuleFit Regressor」を選択したいと思います。
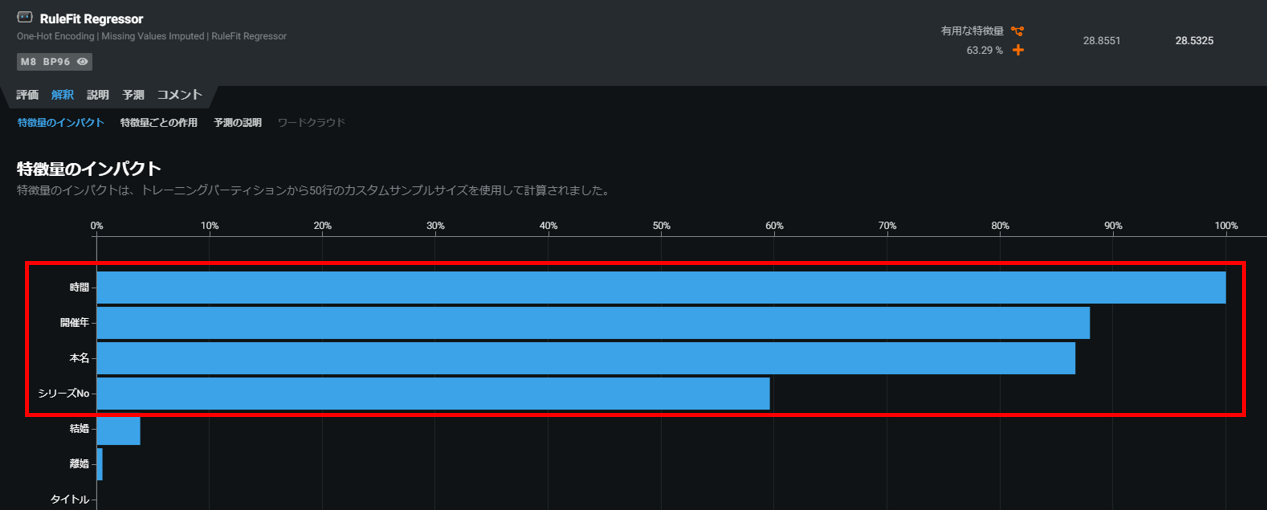
ここのプロセスの「モデルの選択」も分析者にゆだねられ、分析の成否を左右する重要なポイントです。
6/ 予測モデルで結果を予測する
最後に選択した予測モデル「RuleFit Regressor」を利用して2020年の叩かれる回数を予測させましょう。
2020年の結果を予測するためのデータをExcelで作成します。
下記のように、過去データと同じフォーマットで、予測したい「叩かれる回数」をブランクにした状態でデータを作成します。
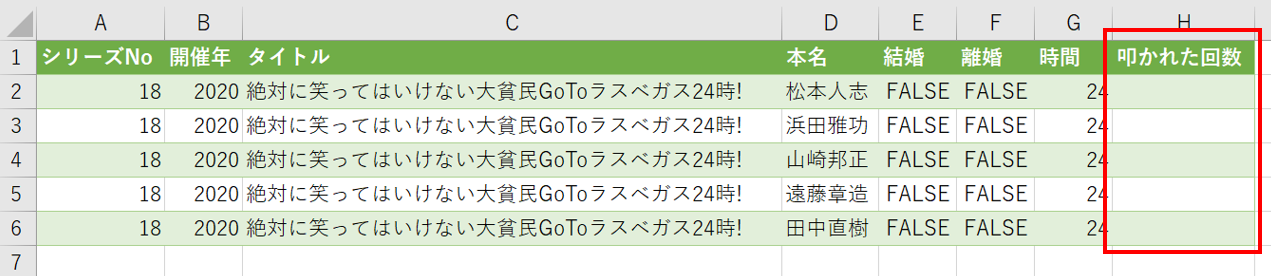
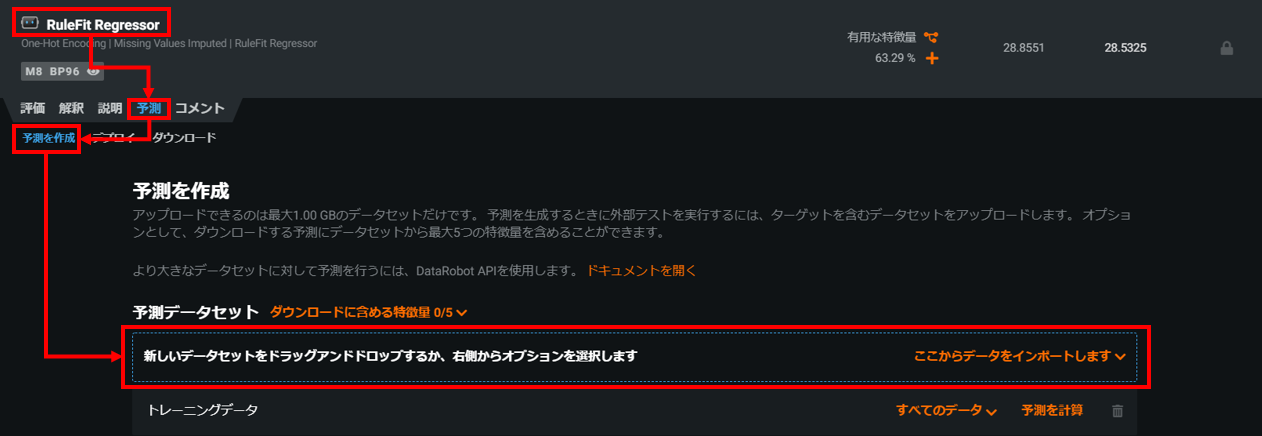
選択したモデルをクリック > 予測をクリック > 予測を作成をクリック
作成した2020年結果予測Excelをドラッグアンドドロップします。
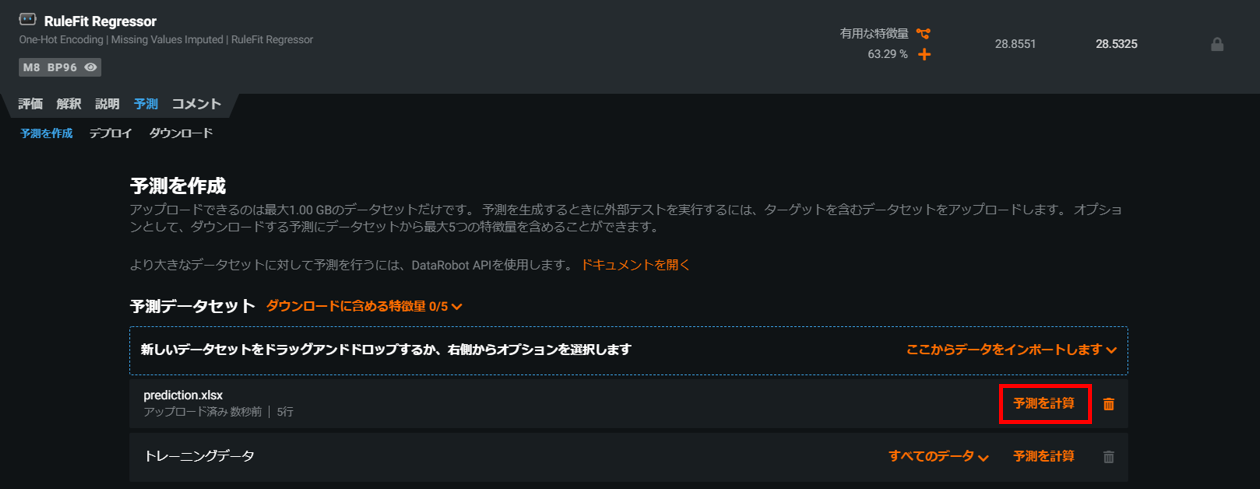
予測を計算をクリックします。
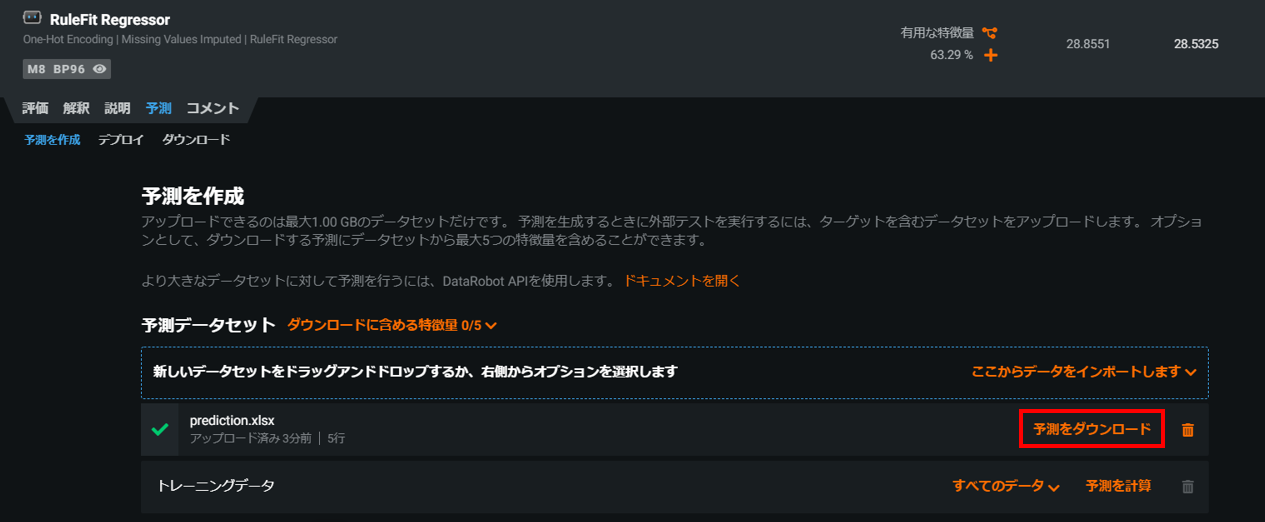
予測をダウンロードをクリックします。
ダウンロードされたExcelファイルを開いてみます。これが予測結果です。
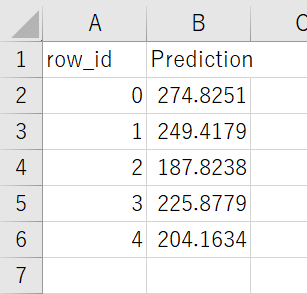
つまり「笑ってはいけない2020」誰が何回シバかれるか?の予測結果はこれだ!
| 名前 | 叩かれる回数 | 優勝 |
|---|---|---|
| 松本 人志 | 275 | ◎ |
| 浜田 雅功 | 249 | |
| 月亭 方正 | 188 | |
| 遠藤 章造 | 226 | |
| 田中 直樹 | 204 |
年明けの答え合わせ(2021/1/1追記)
年明けに答え合わせを追記予定。
////以下2021/1/1追記////
| 名前 | 叩かれる回数 | 予想 | 結果 |
|---|---|---|---|
| 松本 人志 | 275 | 249 | |
| 浜田 雅功 | 249 | 250 | |
| 月亭 方正 | 188 | 184 | |
| 遠藤 章造 | 226 | 194 | |
| 田中 直樹 | 204 | 206 |
浜田、方正、田中に関してはかなりの精度で予測できていた。
一方、松本、遠藤に関しては、予想から20-30程下回る結果だった。
今回の分析で利用した説明変数は、名前、第何回であるか、タイトル、結婚したか、離婚したかのみであった。
つまり、他の要素が松本と遠藤の結果に大きな影響を与えていたことが推測できる。
この放送に際して、浜田・方正・田中には影響が少なく、松本と遠藤には叩かれえる回数がマイナスに影響しそうな要因はなにか?これを深掘りして次回の説明変数に加えることが、分析精度を高めることに貢献できるということだと思う。
参考サイト
ガキ使 番組公式ページ
https://www.ntv.co.jp/gaki/special/index.html
DataRobot公式ページ
https://www.datarobot.com/jp/
DataRobotのYouTubeチャンネル
https://www.youtube.com/channel/UCua787KW7PkcsmpB7Z72PnQ
DataRobot無料トライアル
https://www.datarobot.com/jp/trial/
Wikipedia 笑ってはいけないシリーズ
https://ja.wikipedia.org/w/index.php?title=%E7%AC%91%E3%81%A3%E3%81%A6%E3%81%AF%E3%81%84%E3%81%91%E3%81%AA%E3%81%84%E3%82%B7%E3%83%AA%E3%83%BC%E3%82%BA
Wikipedia 松本人志
https://ja.wikipedia.org/wiki/%E6%9D%BE%E6%9C%AC%E4%BA%BA%E5%BF%97
Wikipedia 浜田雅功
https://ja.wikipedia.org/wiki/%E6%B5%9C%E7%94%B0%E9%9B%85%E5%8A%9F
Wikipedia 月亭方正
https://ja.wikipedia.org/wiki/%E6%9C%88%E4%BA%AD%E6%96%B9%E6%AD%A3
Wikipedia 田中直樹
https://ja.wikipedia.org/wiki/%E7%94%B0%E4%B8%AD%E7%9B%B4%E6%A8%B9_(%E3%81%8A%E7%AC%91%E3%81%84%E8%8A%B8%E4%BA%BA)
Wikipedia 遠藤章造
https://ja.wikipedia.org/wiki/%E9%81%A0%E8%97%A4%E7%AB%A0%E9%80%A0