はじめに
先日,chatGPTで決算短信分析をする記事を公開しました.
https://qiita.com/kaizinZ/items/3bc0b4e771690f57d923
この記事と本記事を照らし合わせながら読むと良いと思います.
claude2はchatGPT4の約3倍の最大100,000トークン(約75,000語)のテキストを処理できるみたいです.
無料でpdfなどのファイルを複数読み込めるようですね.
最新の情報がいつか聞いてみたところ,ほぼリアルタイムの情報を扱えるようです.
ChatGPTでの課題
ChatGPTで決算短信分析をした際に課題となったのが以下の3点です.
- Browse with Bingでは,情報源が複数存在することによる情報の不一致が起き分析できない
- pdfをアップロードしても決算短信の特徴的なフォーマットが構造的に捉えられない
- Advanced Data Analysis, plugin共に文字化けが原因で正常にpdfを読み込めない
Claude2でこれらの課題が解決できるのか試してみます.
pdfをアップロードせずに分析
Claude2ではほとんどリアルタイムの情報を扱えるようなので,pdfをアップロードしなくても少し前の決算短信の分析ができるのか試します.
ChatGPTと比較するために,日本電信電話(NTT)の決算を,同じプロンプトを用いて分析させてみます.
あなたは熟練の経済アナリストです.
日本電信電話 (9432)の最新の決算(2023年6月期)について,以下の手順で分析してください.
・web上で日本電信電話の最新の決算短信についての情報を取得
・取得した情報から今後の株価に影響を与える要素を抽出
・抽出した要素を, 株価上昇つながる要素と株価下降につながる要素に分けて分析
・総合的に株価にどのような影響を及ぼす可能性があるかを分析
不明な点があっても適当な内容を創作せずに,不明であると述べてください
情報に矛盾がある場合はもう一度調べ直して正確な情報を提示してください
回答はマークダウン形式で記述してください
回答

答えてもらえませんでした.しかし,以下のように少し粘るだけで回答を得ることができました.

事業内容にまで踏み込んだ分析をしていることがわかりますが,株式分割や再生可能エネルギー事業者の子会社化についての記述はないですね.
それらについて聞いてみたら回答を得ることができました.

ChatGPTと比較して,データソースの提示はないものの分析してもらうことができました.
pdfをアップロードして分析
ChatGPTでは,Advanced Data Analysis, plugin共に文字化けが原因で正常にpdfを読み込めない問題が発生しました.
Claude2ではpdfを直接アップロードするだけで分析できているようです.
あなたは熟練の経済アナリストです.
添付したpdfファイルは日本電信電話 (9432)の最新の決算(2023年6月期)における決算短信です.
pdfを以下の手順で分析してください.
・添付したpdfを全て読み込む
・pdfから今後の株価に影響を与える要素を抽出
・抽出した要素を, 株価上昇つながる要素と株価下降につながる要素に分けて分析
・総合的に株価にどのような影響を及ぼす可能性があるかを分析
不明な点があっても適当な内容を創作せずに,不明であると述べてください
情報に矛盾がある場合はもう一度調べ直して正確な情報を提示してください
回答はマークダウン形式で記述してください
回答

正常に読み込めていますね,同一ファイルでもここまで結果に差があるとClaude2の方が決算分析に適していると言えそうです.
ですが,配当予想の記述が間違っていますね.突き詰めていくと正しく回答できるようです.


配当予想を事前に知っていなければこのような質問を投げかけることもできません.
予め知っている必要がないように,回答の全ての要素のファクトチェックをお願いしてみるがいいですね.
ちなみに,pdfの10ページ目をChatGPTに読み込ませたとき,文字化けで読み込めないという事象が起きました.
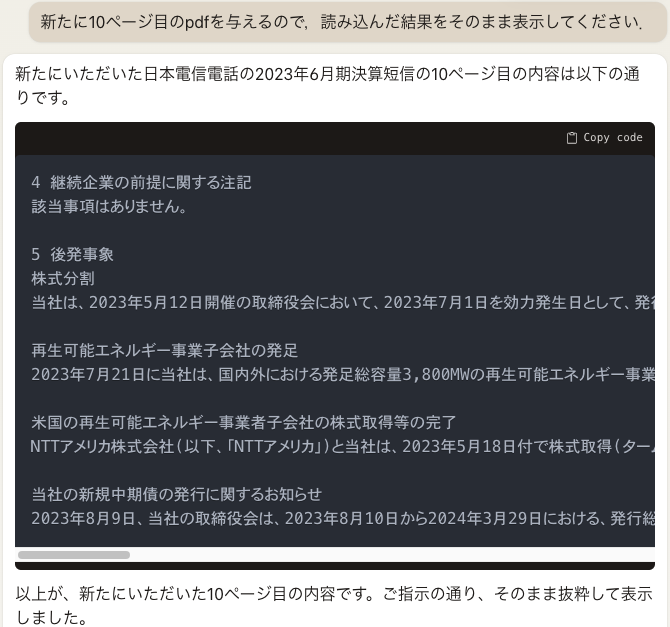
Claude2に10ページ目の読み込みを依頼すると何故か2ページ目を読み込みました.
そこで,10ページ目のみを別ファイルとして与えたとき,Claude2は内容を表示することができました.
まとめ
ChatGPTで起きた3つの問題(web上のデータから分析不可,pdfの構造的な読み込み不可,pdfの読み込みで文字化け)をClaude2では解決できるようです.
特に,pdfの読み込みで文字化けが起きなかったことが衝撃ですね.つまり,文字化けはChatGPTの読み込み方法に問題があるということです.
ChatGPTはpdfを読み込む際にコードを示してくれます.PythonのコードではPyPDF2を使用しています.Claude2にどのようにpdfを読み込んだかを質問すると,同じようにPyPDF2を使用しているそうです.
手元で実際にやってみましたが,Claude2が勧める方法では文字化けが発生しました.そのことを伝えるとpyocrを勧めてきました.内部的にはこちらの方法でやっているのかもしれませんね.
OCRで処理することは前回記事のネクストアクションとして考えていました.
次はOCRで事前に処理した結果を与える,ChatGPTにOCRでテキスト化してから分析させることを試してみたいと思います.