はじめに
馬鹿パラしてますか?
馬鹿パラには「パラメータ並列」と「サンプル並列」がありますが、その二種類を同時に扱うための簡易スケジューラを書きました。ソースはここに置いておきます。
https://github.com/kaityo256/tp_scheduler
これは、MPI_Comm_splitのシンプルかつそれなりに実践的なサンプルになっているので、興味のある人は見てみると面白いかもしれません。
馬鹿パラとは
並列計算において、タスク間に依存関係がなく、独立に実行できるような計算を自明並列(Trivial Parallel)もしくは馬鹿パラ(Embarrassingly parallel)と呼びます。馬鹿パラは計算機屋さんに文字通り馬鹿にされることが多いのですが、並列効率が非常に高く、1000プロセス走らせれば計算が1000倍早くなるために非常に有用です。
馬鹿パラは大きく分けて二種類に分かれます。一つは「パラメータ並列」です。ほとんどの数値計算において、何かパラメータを一点とればおしまい、ということはありません。例えば温度依存性を知りたければ、多数の温度点において計算を実行することになります。そして、異なる温度の計算は独立に計算することができます。もう一つは「サンプル並列」です。数値計算で得られた結果がどのくらい信用できる値なのかを表すために、なんらかの方法でエラーバーをつけたくなります。しかし、数値計算でエラーバーをつける、というのは意外に面倒です。
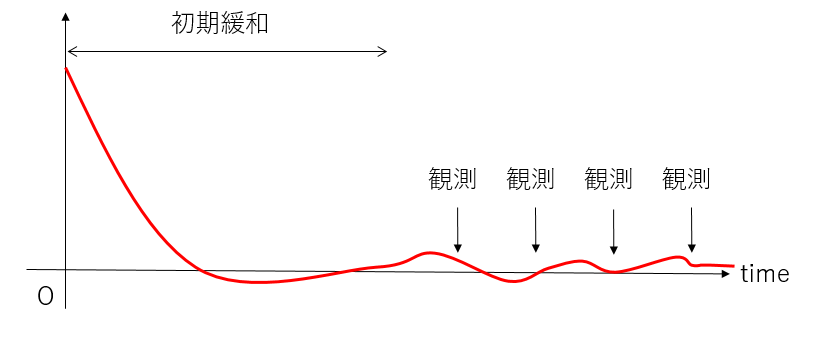
例えば、一つの計算を長時間行って、一定時間間隔で測定した結果を使ってエラーバーを評価する場合、測定間隔が短いと相関が残ってしまい、誤差を過小評価します。かといって測定間隔を長くすると計算がしんどくなります。
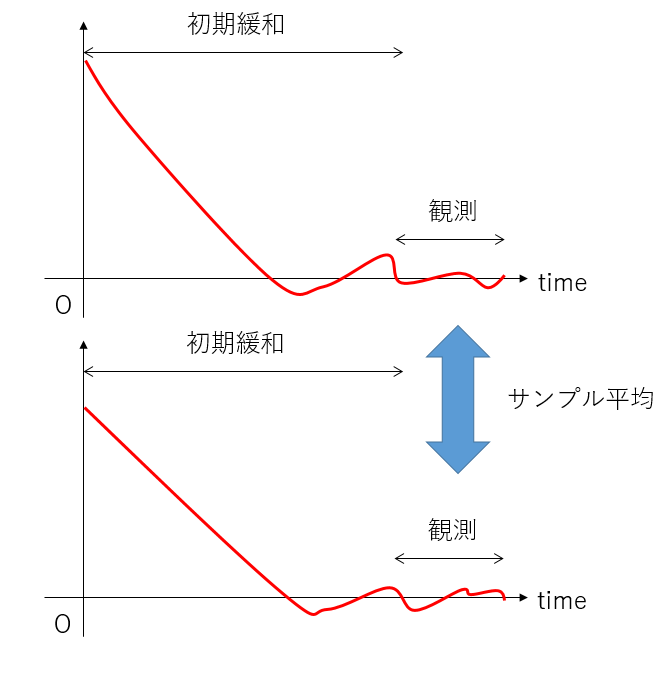
相関をちゃんと調べて誤差を評価する方法もありますが、同じパラメータ、異なる種(シード)で計算した結果を独立だと思って誤差を評価するのが簡単です。厳密にはこれも相関が残ったりすることがあるのですが、とりあえず同じランの違う時刻を使うよりはマシな気がします。
数値計算においては、複数のパラメータ、複数のサンプルを計算することが非常に多いため、それらに対して馬鹿パラが適用できるととても有用です。一般に、ノードをまたぐ並列化は分散メモリ並列となり、通信にはMPIを使う必要があります。パラメタ並列のみ、サンプル並列のみを実装するのは簡単ですが、それらを同時に扱うのは意外に面倒です。というわけで、MPI_Comm_splitを使ってプロセスを複数のグループに分け、グループ内はサンプル並列、グループ間はパラメタ並列をさせてみることにしましょう。
インタフェースとシリアル計算
まずは馬鹿パラするためのインタフェースを決めましょう。並列化されていないシミュレータを、簡単に並列化できる形が望ましいですね。とりあえずパラメータはParamsという構造体で受け取り、観測値はstd::vector<double>で返すことにしましょう。インタフェースはこんな感じです。
std::vector<double> run(Params &p);
このシミュレータをコールバックのような形でスケジューラに渡して計算してもらうことにしましょう。まずは並列化した場合と等価な計算をするシリアルコードを書きましょう。余談ですが、並列プログラムを書く時には、それと全く等価な動作をエミュレートするシリアルコードを書いておくとデバッグに役立ちます。
パラメータセットはstd::vector<Params> &pvという形で用意しましょう。各パラメタについて、num_samples回だけサンプリングし、返してきた物理量の平均と、平均の標準偏差を表示するスケジューラを用意します。例えばイジングモデルのモンテカルロ計算をするising2dというシミュレータを作ったとして、インタフェースはこんな感じになるでしょう。
tps::run(pv, ising2d, num_samples);
これで、ising2dに、pvの要素pv[i]を次々と渡しながら計算をします。パラメータは適当でいいですが、特別なフィールドとしてparameterとseedを用意しましょう。parameterは、観測した物理量と一緒に出力するのに使います。今回は温度を主要なパラメータとします。seedは、同じパラメータで異なる計算をするために、スケジューラがseedを変えならnum_samples回だけシミュレータを呼び出します。
観測値は磁化とビンダー比の二つにしましょう。各温度でthermalization_loopだけ緩和させ、observation_loop回だけ観測した平均値をnum_samples回測定するコードはこんな感じになるでしょう(リポジトリにising2dとしてサンプルコードを載せています)。
# include "../tps.hpp"
# include "ising_mc.hpp"
# include <cmath>
# include <iostream>
# include <vector>
const int num_samples = 4; // Number of Samplings at each temperatures
const int size = 32; // System Size
const int thermalization_loop = 10000; // Number of Loops for Thermalization
const int observation_loop = 1000; // Number of Loops for Observation
int main(void) {
// Tempeartures to be simulated
std::vector<double> temperatures = {1.80, 1.85, 1.90, 1.95, 2.00, 2.05, 2.10, 2.15, 2.20, 2.25, 2.30, 2.35, 2.40, 2.45, 2.50, 2.55, 2.60, 2.65, 2.70, 2.75};
std::vector<Params> pv;
for (size_t i = 0; i < temperatures.size(); i++) {
Params p;
p.thermalization_loop = thermalization_loop;
p.observation_loop = observation_loop;
p.size = size;
p.parameter = temperatures[i];
pv.push_back(p);
}
tps::run(pv, ising2d, num_samples);
}
温度のリストからパラメータのリストを作り、それをスケジューラであるtps::runに渡します。スケジューラは各パラメタでシミュレータをnum_samples回実行し、誤差を推定して結果を出力します。こんな出力になります。
1.8 0.916729 +- 0.000162625 1.0008 +- 6.80208e-06
1.85 0.899607 +- 0.000775186 1.00115 +- 3.99873e-05
1.9 0.881281 +- 0.00126314 1.00154 +- 4.23411e-05
1.95 0.858958 +- 0.00101423 1.00235 +- 5.00265e-05
2 0.832781 +- 0.00105317 1.00336 +- 0.000168824
2.05 0.798061 +- 0.00233313 1.00635 +- 0.000758599
2.1 0.757557 +- 0.0027614 1.00979 +- 0.000796631
2.15 0.706439 +- 0.00127406 1.01758 +- 0.00112574
2.2 0.647971 +- 0.0071567 1.02783 +- 0.00468055
2.25 0.529098 +- 0.0186113 1.10248 +- 0.0246109
2.3 0.391529 +- 0.0220254 1.26122 +- 0.0479313
2.35 0.211812 +- 0.017155 1.73562 +- 0.13544
2.4 0.176714 +- 0.0265132 1.78537 +- 0.145708
2.45 0.111087 +- 0.0214369 2.07215 +- 0.188882
2.5 0.0680596 +- 0.0029158 2.62147 +- 0.170694
2.55 0.0430204 +- 0.00333944 2.63963 +- 0.124959
2.6 0.0408879 +- 0.00434679 2.73116 +- 0.0959289
2.65 0.0271151 +- 0.000921447 2.8661 +- 0.182916
2.7 0.0242522 +- 0.00190593 2.84275 +- 0.0778209
2.75 0.0203971 +- 0.00105153 3.15288 +- 0.202477
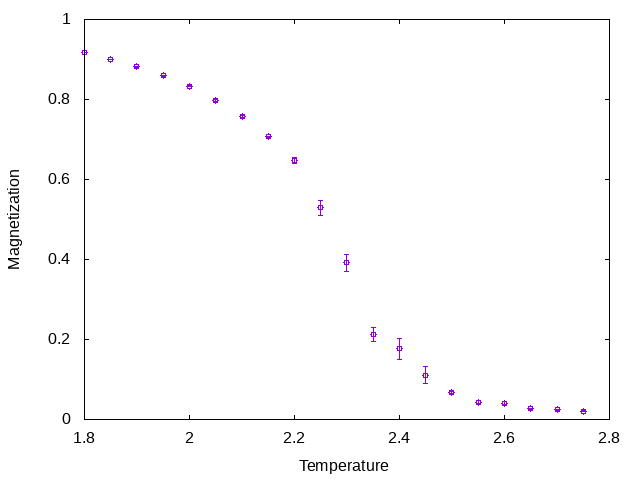
シミュレータは二つの観測を返していますが、スケジューラが誤差の推定値も含めて返しています。グラフ化するとこんな感じです。
まずは磁化(Order Parameter)。
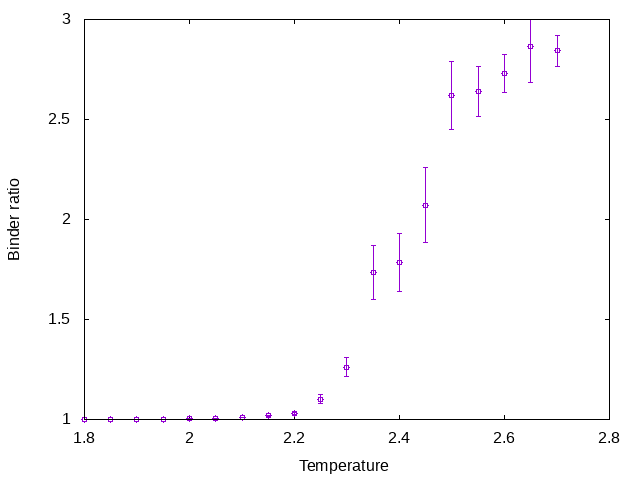
ビンダー比。
これを並列化しましょう。
MPI_Comm_split
MPIを使ったことがある人なら、多くの関数がMPI_COMM_WORLDという定数を引数に取ることを知っているでしょう。これはコミュニケータと呼ばれるプロセスグループで、MPI_COMM_WORLDはMPIにデフォルトで定義されている「プロセス全部」を表すコミュニケータです。MPIではプロセスを任意のグループに分けることができます。そのグループ分けに使うのがMPI_Comm_splitです。MPI_Comm_splitは、colorとkeyを引数に取ります。colorがグループを決めます。同じ色が同じグループです。keyはグループ内のランクを決めるのに使います。
パラメタ並列をする際は全く通信が必要ありませんが、サンプル平均をする際には集団通信をするので、なるべくプロセスが近くにまとまっていて欲しいところです。そこで、近いプロセスをまとめて同じグループにします。今回はサンプル数num_samplesのサイズのグループを作るので、単純にランクをnum_samplesで割ればグループの色になります。
int csize = num_samples;
int color = rank / csize;
例えば8プロセスで、4サンプルとることを考えると、こんな感じに2色に分けます。
0 1 2 3 | 4 5 6 7
ランク0から3までが同じグループで、4から7までが同じグループになります。このような分割は、番号の近いランクのプロセスが物理的に近いところにいる、すなわち「by slot」でならんでいることを前提にしています。イメージとしてはこんな感じです。
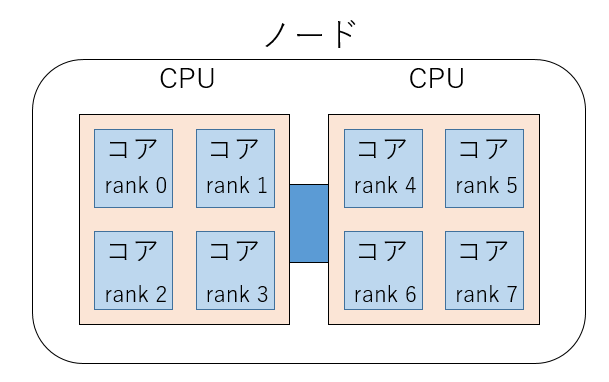
この場合は、4コアのCPUが2ソケットのマシンで、同じ色のグループが同じソケットに載るイメージです。MPIにおけるプロセス配置方法は実装によって違うので、それぞれのマニュアルを参照してください。
keyは指定しなければよしなに決めてくれるのですが、どうなるかよくわからないのでとりあえずグローバルなrankを入れておきましょう。こんな感じになります。
int rank, procs;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &procs);
int csize = num_samples;
int color = rank / csize;
MPI_Comm my_comm;
MPI_Comm_split(MPI_COMM_WORLD, color, rank, &my_comm);
以後、MPI_COMM_WORLDの代わりにmy_commを使うと、そのグループ内で集団通信をしたり、グループ内のランクやサイズを取得することができます。
パラメタの分割
さて、プロセスをグループに分割し、グループ内でサンプル平均、グループ間でパラメタ平均をとるので、グループの数でパラメタを分割しなければなりません。例えば20プロセスあって、4サンプルとるとすると、グループあたり4プロセス、つまり5グループ(5色)できることになります。例えばパラメータが5の倍数の時には良いですが、21とか18とか半端な数の時、なるべくバランスが良いようにバラさなければなりません。
例えば、
21 = 5 + 4 + 4 + 4 + 4
18 = 4 + 4 + 4 + 3 + 3
みたいにしたいわけですね。パラメータセットはstd::vector<Params> pvで受け取ることにして、何番目のグループがどこからどこまで担当すべきかを、こんな感じに計算してみます。
int csize = num_samples;
int color = rank / csize;
int num_colors = procs / csize;
int num_data = pv.size();
int block = num_data / num_colors;
int rest = num_data % num_colors;
int s = color * block + std::min(color, rest);
int e = s + block;
if (color < rest) {
e += 1;
}
std::vector<PARAMS> my_param(pv.begin() + s, pv.begin() + e);
もっとかしこい方法もあるのでしょうが、とりあえずこれでよいことにしましょう。各プロセスグループには、分割されたパラメタリストが渡され、後はシリアル計算と同じです。
次にサンプル平均ですが、シリアルの場合はこんな感じで普通のfor文を回しています。
for (int j = 0; j < num_samples; j++) {
pv[i].seed = j;
std::vector<double> r = run_task(pv[i]);
data.push_back(r);
}
calc_stdev(pv[i].parameter, data);
ループ内でパラメタのseedを変えてシミュレータを呼び出し、結果をstd::vectorで受け取って、calc_stdevで誤差を計算しています。
並列版では、このループをMPI_Comm_splitで分割したコミュニケータ内で並列処理して、最後にMPI_Allgatherでデータを集めて処理します。
MPI_Comm_rank(my_comm, &rank);
pv[i].seed = rank;
std::vector<double> r = run(pv[i]);
std::vector<double> rbuf(r.size() * procs);
MPI_Allgather(r.data(), r.size(), MPI_DOUBLE, rbuf.data(), r.size(), MPI_DOUBLE, my_comm);
受け取ったデータを整理してcalc_stdevに渡せば後は同じです。以上を実装したtps::run_mpiの呼び方はこんな感じになるでしょう。
# include "../tps_mpi.hpp"
# include "ising_mc.hpp"
# include <cmath>
# include <iostream>
# include <mpi.h>
# include <vector>
const int num_samples = 4; // Number of Samplings at each temperatures
const int size = 32; // System Size
const int thermalization_loop = 10000; // Number of Loops for Thermalization
const int observation_loop = 1000; // Number of Loops for Observation
int main(int argc, char **argv) {
// Tempeartures to be simulated
std::vector<double> temperatures = {1.80, 1.85, 1.90, 1.95, 2.00, 2.05, 2.10, 2.15, 2.20, 2.25, 2.30, 2.35, 2.40, 2.45, 2.50, 2.55, 2.60, 2.65, 2.70, 2.75};
std::vector<Params> pv;
for (size_t i = 0; i < temperatures.size(); i++) {
Params p;
p.thermalization_loop = thermalization_loop;
p.observation_loop = observation_loop;
p.size = size;
p.parameter = temperatures[i];
pv.push_back(p);
}
MPI_Init(&argc, &argv);
tps::run_mpi(pv, ising2d, num_samples);
MPI_Finalize();
}
MPI_InitとMPI_Finalizeを呼んでいることを除けば、シリアル版と同じです。
ベンチマーク
出力結果の順序は入れ替わるので、温度でソートしましょう。シリアル版と実行時間と結果を比較します。以下は Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHzが載ったマシンでのベンチマーク結果です。物理20コア、ハイパースレッドで論理40コアです。
シリアル実行。
$ time ./serial.out > serial.dat
real 0m16.468s
user 0m16.428s
sys 0m0.001s
並列実行。
$ time mpirun -np 40 ./mpi.out | sort -nk 1 > mpi.dat
real 0m0.891s
user 0m24.240s
sys 0m0.724s
ソートした結果は、シリアル版と全く同じ結果を与えます。実行速度は18.5倍で、20コアのマシンであることを考えるとまぁまぁです。
パーコレーションの例
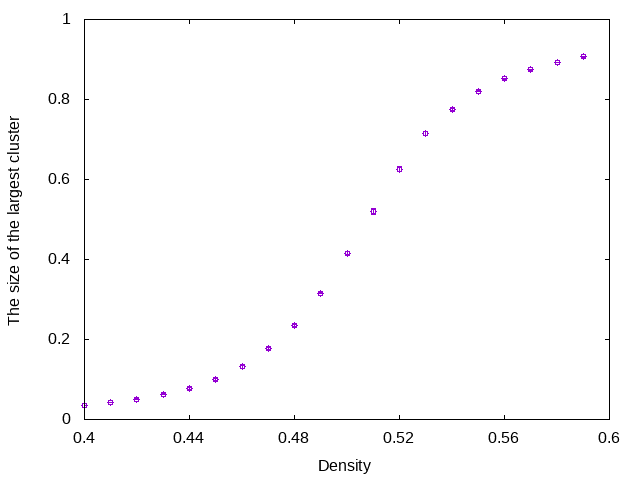
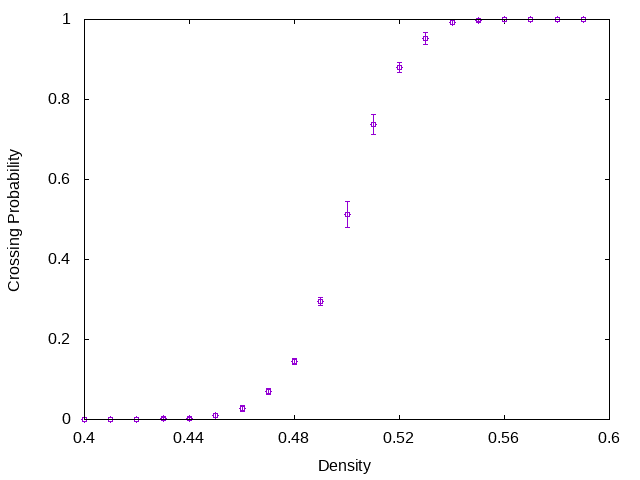
インタフェースさえ揃えれば、どんなシミュレータでも馬鹿パラできます。今度は正方格子上でのボンドパーコレーションの計算をしてみましょう(リポジトリにpercolation2dとしてサンプルコードを載せています)。パラメータはアクティブなボンドの密度で、観測量は規格化された最大クラスターサイズと、パーコレーション確率(Crossing Probability)にしましょう。パーコレーション確率は、ある辺からアクティブなボンドだけを通って対面の辺にたどりつける確率です。
まず、シリアル計算はこんな感じになります
# include "../tps.hpp"
# include "percolation2d.hpp"
# include <vector>
const int num_samples = 4;
int main() {
std::vector<double> densities = {0.40, 0.59, 0.41, 0.58, 0.42, 0.57, 0.43, 0.56, 0.44, 0.55, 0.45, 0.54, 0.46, 0.53, 0.47, 0.52, 0.48, 0.51, 0.49, 0.50};
std::vector<Params> pv;
for (size_t i = 0; i < densities.size(); i++) {
Params p;
p.parameter = densities[i];
p.size = 64;
p.seed = 1;
p.observation_loop = 100;
pv.push_back(p);
}
tps::run(pv, percolation2d, num_samples);
}
並列版のコードも同様です。
# include "../tps_mpi.hpp"
# include "percolation2d.hpp"
# include <vector>
const int num_samples = 4;
int main(int argc, char **argv) {
std::vector<double> densities = {0.40, 0.59, 0.41, 0.58, 0.42, 0.57, 0.43, 0.56, 0.44, 0.55, 0.45, 0.54, 0.46, 0.53, 0.47, 0.52, 0.48, 0.51, 0.49, 0.50};
std::vector<Params> pv;
for (size_t i = 0; i < densities.size(); i++) {
Params p;
p.parameter = densities[i];
p.size = 64;
p.seed = 1;
p.observation_loop = 100;
pv.push_back(p);
}
MPI_Init(&argc, &argv);
tps::run_mpi(pv, percolation2d, num_samples);
MPI_Finalize();
}
ここで、密度が昇順になっていないのは、ロードバランスのためです。パーコレーションは密度が高いほど計算が重くなるため、こうして適当に混ぜています。
実行結果はこんな感じです。まず、最大クラスターサイズをサイト数で規格化したもの。
パーコレーション確率(Crossing Probability)。
ベンチマーク結果はこんな感じです。
$ time ./serial.out | sort -nk1 > serial.dat
real 0m19.653s
user 0m19.605s
sys 0m0.004s
$ time mpirun -np 40 ./mpi.out | sort -nk1 > mpi.dat
real 0m1.286s
user 0m29.176s
sys 0m0.791s
結果は全く一致します。
$ diff -s serial.dat mpi.dat
Files serial.dat and mpi.dat are identical
実行速度は15倍ちょっとと、ロードインバランスのためにイジングモデルに比べてやや落ちます。
まとめ
簡単に馬鹿パラをするためのスケジューラを書いてみました。シリアルコードを持ってる人は、適当なラッパーをかぶせればすぐにパラメタ並列とサンプル並列を両方やる馬鹿パラできるようになります。パラメータ50個、サンプリングを24回とかやれば、それだけで1200並列です。一般に並列化効率も良いためにスパコンを使った時の「ありがたみ」も実感しやすく、スパコンを使うのに、まず馬鹿パラから入る、というのは良い気がします。
今回書いたスケジューラは、スケジューラといっても何もスケジューリングしません。OpenMPで言うところのstaticにあたるスケジューリングしかしていないので、気になる人はいろいろ追加実装してみると良いでしょう。また、乱数の種としてグループ内のランクを渡しているため、異なるパラメータで同じ種を使ってしまいます。それも気になる人は修正すると良いでしょう。
この記事が誰かの並列化ライフの助けになれば幸いです。