はじめに
これは合成数列の和 Advent Calendar 2018の14日目の記事です。以下のルールに従ったコードを好きな言語で書け、というお題です。
【ルール】
- 入力として正の整数 N を与えたら 4 から始まる 合成数 の数列の 1 番目から N 番目までの合計を出力してください
- N は最大で 100 とします
おそらく他の人は変○的なプログラミング技法を駆使してくるのでしょうが、私はx86アセンブリで素直に書いてみようと思います。ただ、入力と出力も全部アセンブリで書くのはしんどいので、入力はハードコーディング、出力はprintfを使わせてください。
回答
まず、答えはこんな感じです。
.section .rodata
.FMT:
.string "%d\n"
# %esiに入れられた数字を表示する
myprint:
push %rax
push %rcx
push %rdx
push %rdi
mov $.FMT, %edi
mov $0, %eax
call printf
pop %rdi
pop %rdx
pop %rcx
pop %rax
ret
/* %eaxに入れられた数字が合成数か判定 */
/* 合成数なら1、それ以外なら0を返す */
is_composit:
push %rbx
push %rcx
push %rdx
cmp $4,%eax /* 4未満なら合成数でない */
jl is_composit_end
mov %eax, %ebx
/* メインループ */
shrl %eax /* 入力を2で割る */
mov %eax, %ecx
mov %ebx, %eax
is_composit_loop:
mov %ebx, %eax
cltd
idivl %ecx
cmp $0, %edx
jne is_composit_next
mov $1, %eax /* 合成数だったので1を返す */
pop %rdx
pop %rcx
pop %rbx
ret
is_composit_next:
sub $1, %ecx
cmp $1, %ecx
jne is_composit_loop
/* 合成数ではなかったので0を返す */
is_composit_end:
mov $0, %eax
pop %rdx
pop %rcx
pop %rbx
ret
/* %eaxに入った数(N)だけ合成数を合計する*/
composit_sum:
mov %eax, %ebx
mov $2, %ecx /* ループカウンタ */
mov $0, %edx /* 見つけた合成数の数 */
mov $0, %edi /* 見つけた合成数の和 */
composit_sum_loop:
mov %ecx, %eax
call is_composit
test %eax, %eax
jz composit_sum_continue
/* 合成数を見つけたので部分和を表示 */
inc %edx
add %ecx, %edi
mov %edi, %esi
call myprint
composit_sum_continue:
inc %ecx
cmp %ebx,%edx
jl composit_sum_loop
ret
.globl main
main:
/* ここでNを指定する */
mov $100, %eax
call composit_sum
ret
実行するとこんな感じです。これはN=100の場合です。
$ gcc x86.s
$ ./a.out
4
10
18
(snip)
6794
6926
7059
最後の答えだけを出せばいいのだと思いますが、デバッグを兼ねて部分和も表示しています。
アセンブリの調べ方
さて、もうこれでお題への回答はおしまいなのですが、ついでにアセンブリについてつらつら書いてみようかな、と思います。「アセンブリ」というと「難しい」という印象を持つ人が多いかと思います。しかし、少し「とっつきにくい」のは事実ですが、難しくはありません。っていうか、アセンブリというのは文字通り低級言語であり、低級言語とは「できることが少ない」言語であり、「できることが少ない」ために「覚えることも少ない」からです。以下、「レジスタとかcallでジャンプするとか、そういうのはぼんやり知ってるけど、アセンブリを生で書いたことはない」人向けに、どうやって上記のアセンブリを書いたか説明します。
printfの使い方
まず、全部アセンブリで組むのはしんどいのでprintfを使うと書きました。このAdCを読んでいる人はどうか知りませんが、普通の人はアセンブリからprintfの呼び出し方を知らないと思います。私も覚えていません。でも、そういう場合は適当にC言語で書いてアセンブリを出力すればいいんです。
# include <stdio.h>
void func(int a){
printf("%d\n",a);
}
$ gcc -S -O1 printf.c
普通にアセンブリすると最適化されていないコードが出てきて見づらく、最適化しすぎても分かりづらいので、-O1あたりが読みやすいです。
func:
.LFB11:
subq $8, %rsp
movl %edi, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
addq $8, %rsp
ret
これを見ると、
-
%eaxに0を入れて -
%ediにフォーマット文字列のアドレスを入れて -
%esiに数字を入れて -
printfをcallすれば良い
ことがわかりますね。フォーマット文字列の定義はこんな感じです。
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "%d\n"
ラベル書いて、直後に.stringで定義すれば良いことがわかります。
以上の理解を確認するため、最低限のアセンブリで上記を実行できることを確認してみましょう。
.section .rodata
.FMT:
.string "%d\n"
.globl main
main:
mov $12345, %esi
mov $.FMT, %edi
mov $0, %eax
call printf
ret
数字「12345」を表示することを意図したコードです1。
コンパイル、実行してみます。
$ gcc myprint.s
$ ./a.out
12345
無事に表示されました。しかし、実はここで、printfを使う以外にもズルをしています。gccではなく、アセンブラasとリンカldでビルド、実行してみましょう。
$ as myprint.s -o myprint.o
$ ld myprint.o -o a.out
ld: 警告: エントリシンボル _start が見つかりません。デフォルトとして 0000000000400078 を使用します
myprint.o: 関数 `main' 内:
(.rodata+0x14): `printf' に対する定義されていない参照です
いろいろ怒られました。まず「_startがない」というのは、「スタートアップルーチンが見つからないよ」という意味です。また、printfも見つかりません。これはライブラリなので、ちゃんとその場所をリンカに教えてあげなければリンクできません。このあたりの事情はtanakamuraさんの実践的低レベルプログラミングのリンカの項目を参照してください。要するにいろいろ面倒な処理をgccというコンパイルドライバにまかせて隠蔽しており、そういう意味で今回の回答を「フルアセンブリで組んだ」というのは語弊があるのですが、そのあたりは大目に見てもらうことにしましょう。
条件分岐
さて、合成数の判定に移りましょう。合成数の判定方法として、もっとも単純に「2から自分の半分までの数のうち、一つでも自分を割り切るものがあれば合成数」ということにします。Cで書くとこんな感じです。
int is_composit(int a) {
if (a < 4) return 0;
for (int i = 2; i <= a / 2; i++) {
if (a % i == 0)return 1;
}
return 0;
}
最初に「入力が4未満なら0を返す」という項目があります。まずこの分岐処理を見てみましょう。こんなコードを書きます。
void func1();
void func2();
void func(int a){
if (a<4) func1();
else func2();
}
入力が4未満ならfunc1を、そうでなければfunc2を返す関数です。ここで、「入力が4未満なら1を返す」などとしなかったのは、コンパイラが最適化してよくわからないコードを吐いてきたりするのを防ぐためです(興味のある人はやってみてください)。
このアセンブリはこうなります。
func:
subq $8, %rsp
cmpl $3, %edi
jg .L2
movl $0, %eax
call func1
jmp .L1
.L2:
movl $0, %eax
call func2
.L1:
addq $8, %rsp
ret
アセンブリに詳しくない人でも、
-
funcの引数が%ediに入ってきて -
cmpl $3, %ediで、%ediと3を比較して -
jg .L2は、直前の比較結果を見て、「大きければ .L2に飛べ」という意味だろう
ということは想像がつくかと思います。jgはJump If Greaterの略なので、どうせGreater EqualとかLesser とかあるんだろうということは想像がつきます。
これを元に、is_compositの冒頭、
cmp $4,%eax /* 4未満なら合成数でない */
jl is_composit_end
を書くのは難しくないと思います。
商と余り
x86における割り算はちょっと(知らないと)面倒です。こんなコードを書いてみましょう。
int quot(int a, int b){
return a/b;
}
int rem(int a, int b){
return a%b;
}
対応するアセンブリはこんな感じです。
quot:
movl %edi, %eax
cltd
idivl %esi
ret
rem:
movl %edi, %eax
cltd
idivl %esi
movl %edx, %eax
ret
int funcの返り値が%eaxに入る、という知識が必要ですが、それさえ知っていれば、
-
cltd, idivlで割り算ができる -
idivlは引数として被除数をとり、除数は%eaxが使われる - 除算結果は、 商が
%eaxに、余りが%edxに入る
ということがわかるかと思います。いま欲しいのは割った余りですから、とにかく割り算をして、%edxがゼロなら合成数だ、という判定ができます。
以上を実装したのが、合成数か判定する関数is_compositです。
/* %eaxに入れられた数字が合成数か判定 */
/* 合成数なら1、それ以外なら0を返す */
is_composit:
push %rbx
push %rcx
push %rdx
cmp $4,%eax /* 4未満なら合成数でない */
jl is_composit_end
mov %eax, %ebx
/* メインループ */
shrl %eax /* 入力を2で割る */
mov %eax, %ecx
mov %ebx, %eax
is_composit_loop:
mov %ebx, %eax
cltd
idivl %ecx
cmp $0, %edx
jne is_composit_next
mov $1, %eax /* 合成数だったので1を返す */
pop %rdx
pop %rcx
pop %rbx
ret
is_composit_next:
sub $1, %ecx
cmp $1, %ecx
jne is_composit_loop
/* 合成数ではなかったので0を返す */
is_composit_end:
mov $0, %eax
pop %rdx
pop %rcx
pop %rbx
ret
cmpによる比較とジャンプ、四則演算くらいしか使ってないので読み解くのは難しくないと思います。今回は汎用レジスタとしてr8〜r15を使わないことにしたので、やりくりにちょっと苦労していますが、まぁそこはそれ。
あとpush %rdxとかの説明はかったるくなってきたので割愛します。x86のレジスタはちょっといろいろ面倒なので、興味のある人はhttps://tanakamura.github.io/pllp/docs/index.htmlを読みましょう(丸投げ)。
まとめ
というわけで、x86アセンブリで「合成数列の和」を計算するコードを書いてみました。対応するC言語を書いてアセンブリを出してみると、単純なコードであれば命令がほぼ一対一に対応し、何をやっているかわかりやすいと思います。っていうか、上記を見ていると「わざわざアセンブリで書かなくても、C言語で書いたのとほぼ同じじゃない?」という感想を持つかもしれませんが、正解です。暴論を承知でいえば、C言語は「少し書きやすくしたアセンブリ」です。なのでCが書ければアセンブリも書けます。っていうか、おそらく「C言語を完全に理解する」よりも「アセンブリを完全に理解する」方が簡単だと思います2。本稿が、少しでも「アセンブリは難しい」という誤解を解く助けになれば幸いです。
おまけ:SPARCアセンブリで回答
さて、x86なら「いちいちC言語で書いてアセンブリを見て・・・なんてやらなくても、これくらいのアセンブリ書けるよ!」という人も多いかもしれません。では別のアセンブリではどうでしょうか。例えばSPARCは?ごく一部の例外を除けば、「x86もSPARCもアセンブリはバリバリ書けるよ」という人はそうそういないと思います(たぶん)。私もSPARCのアセンブリなんてほとんど知りませんが、「簡単なCのコードのアセンブリを見る」を繰り返して、お題への回答コードを書きました。こんな感じです。
.section ".rodata"
.FMT:
.ascii "%d\012\000"
.section ".text"
/* %i0に入れられた数字を表示する */
myprint:
save %sp,-192,%sp
mov %i0, %g4
mov %g4, %o1
sethi %h44(.FMT),%o0
or %o0,%m44(.FMT),%o0
sllx %o0,12,%o0
call printf
or %o0,%l44(.FMT),%o0
ret
restore
/* %i0に入れられた数字が合成数か判定 */
/* 合成数なら1、それ以外なら0を返す */
is_composit:
save %sp,-192,%sp
cmp %i0, 4 /* 4未満なら合成数ではない */
bl is_composit_end
nop
/* メインループ */
srl %i0, 1, %l1 /* 入力を2で割る */
is_composit_loop:
sdivx %i0, %l1, %l2
mulx %l2, %l1, %l2
cmp %l2, %i0
bne is_composit_next
nop
mov 1,%o0 /* 合成数だったので1を返す */
ret
restore %o0,%g0,%o0
is_composit_next:
nop
sub %l1, 1, %l1
cmp %l1, 1
bne is_composit_loop
nop
/* 合成数ではなかったので0を返す*/
is_composit_end:
mov 0,%o0
ret
restore %o0,%g0,%o0
/* %o0に入った数(N)だけ合成数を合計する */
composit_sum:
save %sp,-192,%sp
mov %g0, %l1 /* ループカウンタ */
mov %g0, %l2 /* 見つけた合成数の数 */
mov %g0, %l3 /* 見つけた合成数の和 */
composit_sum_loop:
mov %l1, %o0
call is_composit
nop
cmp %g0,%o0
be composit_sum_continue
nop /* 合成数を見つけたので部分和を表示 */
add %l2, 1, %l2
add %l1, %l3, %l3
mov %l3, %o0
call myprint
nop
composit_sum_continue:
mov %l0,%o0
add %l1,1,%l1
cmp %l2, %i0
bl composit_sum_loop
nop
ret
restore
.global main
main:
save %sp,-192,%sp
/* ここでNを指定する */
mov 100, %o0
call composit_sum
nop
ret
restore %g0,%g0,%o0
x86と同じ形に書いたので、比較して見ると面白いかもしれません。
x86アセンブリに慣れた人がSPARCのアセンブリを読む注意点として、レジスタウィンドウの存在や遅延スロットがあります。せっかくなので簡単にレジスタウィンドウと遅延スロットも説明しておきます。
レジスタは極めて高速なメモリですが、いわばグローバル変数であり、どこで誰がいじるかわかりません。なので、関数呼び出しをする際に、呼び出し側と呼び出し元のどちらがレジスタを保存する責任を負うかをあらかじめ決めておく必要があります。また、あとでCPUに実装されたレジスタの数が変わるとアセンブリに非互換性が生まれてしまいます。それらの問題を解決するのがレジスタウィンドウです。
つまり、レジスタは多数用意しておくが、一度に「見える/触れる」レジスタの数を限ることにします。レジスタ全体をレジスタファイル、一度に見えるレジスタをレジスタウィンドウと呼びます。SPARCは、iで始まるのがインプットレジスタ(つまり引数)、lで始まるのがローカル変数、oで始まるのが次の呼び出しレベルにわたすレジスタです。図解するとこんな感じです。
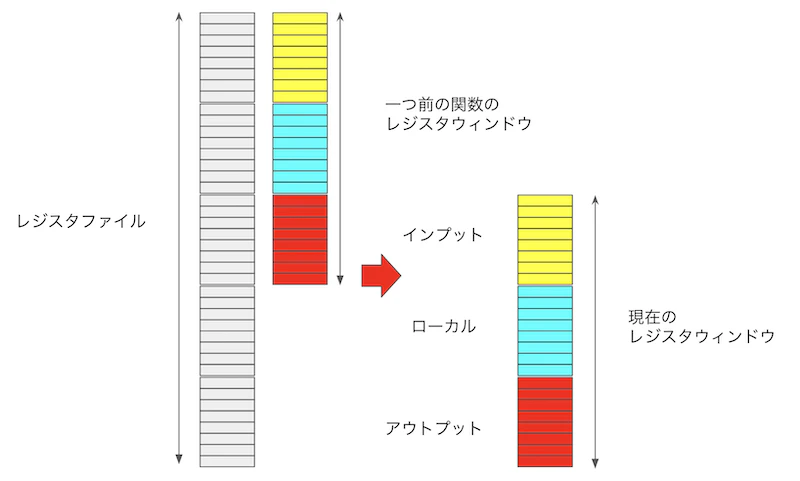
SPARCでは、一度に見えるレジスタはインプット、ローカル、アウトプットそれぞれ8本ずつです。関数コールで、レジスタウィンドウの位置をずらします。すると、アウトプットレジスタだったものが、次のレベルではインプットレジスタになります。ローカルレジスタは他の関数に触られないことが確定しているのでコーディングが楽かもしれませんね。また、レジスタファイルを大きくしても「一度に見えるレジスタ数」を固定しておけば、アセンブリは変更を受けません。
次に、遅延スロットです。SPARCでは、分岐命令やジャンプ命令は「命令が発行されてから実行されるまでに、少し間があく」という性質があります。
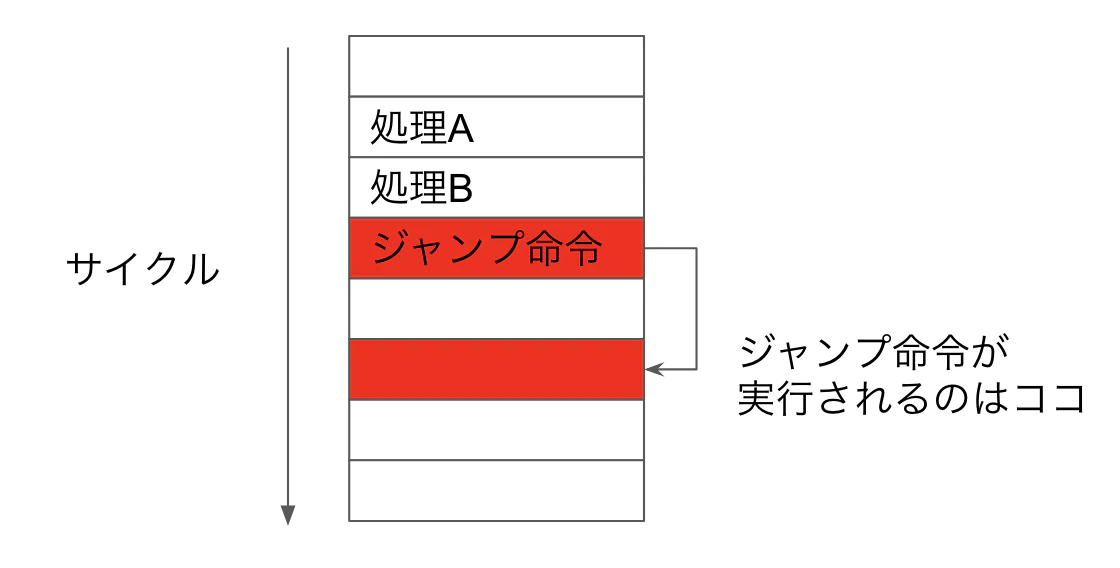
上記で、処理A、処理Bをしてからジャンプをしたいとします。しかし、ジャンプ命令の実行が予約されてから、2サイクル後に実行されるため、1サイクルCPUが遊んでしまいます。「ここ空いているのでもったいないよね。だから処理Bをそこに突っ込んでおこう」と考えたくなりません?これが遅延スロットです。
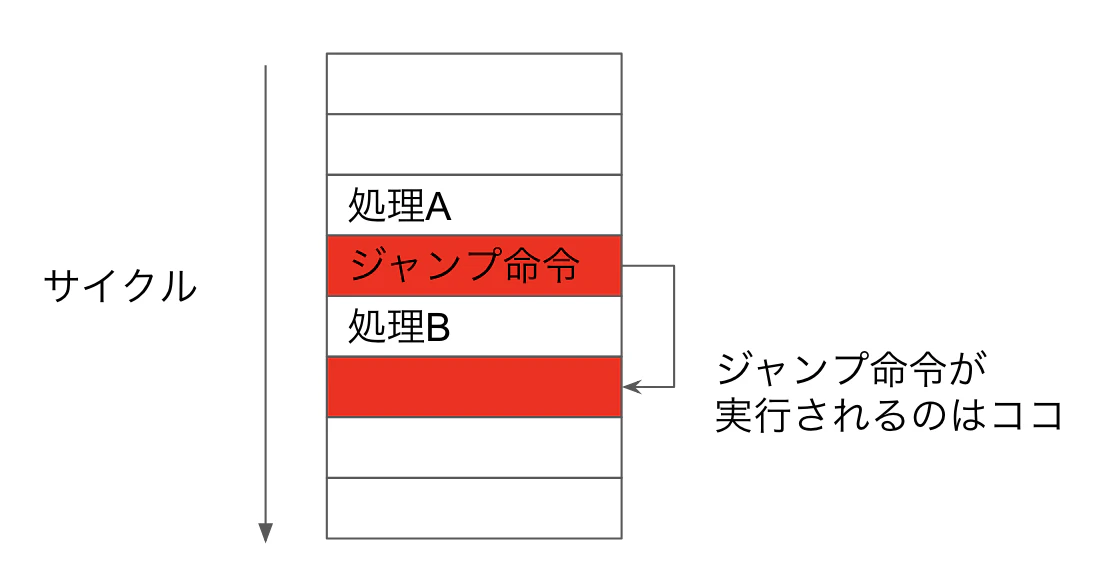
アセンブリとしては、「処理A、ジャンプ、処理B」と並んでいますが、実行される順番は「処理A、処理B、ジャンプ」となります。先程の例では、関数の最後に
ret
restore %o0,%g0,%o0
というアセンブリがありますが、この「ret」はジャンプ命令なので、その直後の遅延スロットにあるrestore %o0,%g0,%o0が実行されてからジャンプします。また、比較命令beなんかも遅延スロットを持ちますが、面倒だったので遅延スロットに「nop」を突っ込んであります。
レジスタウィンドウと遅延スロットは、知らないと混乱するかもしれませんが、それ以外はx86より簡単です。例えば演算がほとんど非破壊型です。除算なら
sdivx %i0, %l1, %l2
は、「%i0を%l1で割った商を%l2に代入せよ」です。余りがゼロかどうか判定するには、商と除数の積が元の数と等しいか調べれば良いのでこんな感じにかけます。
mulx %l2, %l1, %l2
cmp %l2, %i0
bne is_composit_next
これを見て「商%l2に除数%l1をかけた結果を%l2に代入し、それを元の数%i0と比較(cmp)して、等しくなければジャンプせよ(jne)」と理解するのは難しくないと思います。また、レジスタの構造もx86より簡単です。
私はさほどアセンブリ言語の種類を知りませんが、それでも「x86は特異的にアセンブリが複雑だ」という感想を持っています。逆にいえば、x86ができれば他のアセンブリも楽に理解できる気がします。