はじめに
機械学習でよく出てくる手書き文字の認識データMNISTのデータを、ラベルで仕分けして画像データとして保存します。わりと欲しくなるのに意外にそのものずばりのスクリプトが見つからなかったので作りました。
ソースはここです。
データの取得にChainerを使っているため、Chainerがimportできる環境で実行する必要があります。
使い方
スクリプトmnist_dump.pyを実行すると、最初に0から9のディレクトリを作り、そこにtest0000.pngから通し番号でデータを対応するラベルのディレクトリに保存していきます。
$ python mnist_dump.py
7/test0000.png
2/test0001.png
(snip)
6/test0098.png
9/test0099.png
例えば0/には
test0003.png
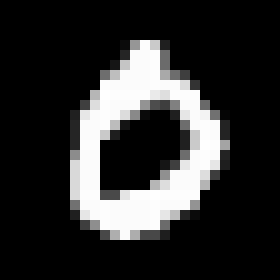
test0010.png
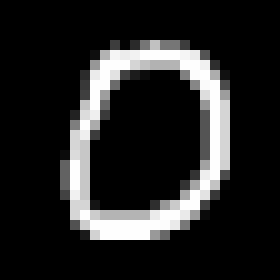
test0013.png
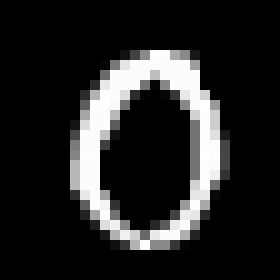
といった具合に、ラベル"0"に対応するデータが保存されます。
デフォルトでは最初の100個だけですが、スクリプトの
for i in range(100):
save(test[i][0], i, test[i][1])
のところを
for i in range(len(test)):
save(test[i][0], i, test[i][1])
にすればテストデータ全部(1万個)について保存します。
簡単な説明
データの取得
MNISTの一次配布元のデータフォーマットは意外に面倒なので、各種ライブラリで読み込むのが楽です。多くのライブラリがMNISTを一発ゲットできる関数を用意しています。Chainerだと、
import chainer
train, test = chainer.datasets.get_mnist()
で一発です。ローカルになければウェブから取得し、ローカルにあればそれを使うため、何度実行してもウェブから取ってくるのは一度だけです。
データ形式
chainer.datasets.get_mnist()で取得したtrainやtestはTupleDatasetというオブジェクトになっています。訓練用が6万、テスト用に1万のデータがあります。データ形式はこんな感じになっています。
-
test[i]がi番目のデータとラベルのセット -
test[i][0]がデータで、784個のfloat32のリスト -
test[i][1]がラベルで、0から9の整数
手書き文字データは28*28のグリッドのデータがずらずらと1次元的に並んだものになっています。グレースケールで、値の範囲は0.0から1.0までです。
データの可視化
データを可視化するのに、Pythonの画像処理ライブラリPillowを使うと楽です。
from PIL import Image
img = Image.new("L", (28, 28))
とすると、縦28ピクセル、横28ピクセルのモノクロ8bitのキャンバスができます。そのピクセル値には
pix = img.load()
とすればアクセスできます。たとえば(x,y)座標の場所の値はpix[x, y]で読み書きできます。あとはMNISTのデータの値をコピーするだけです。ただし、MNISTのデータが0から1までのfloat32で、ピクセル値は0から255までの整数値なので、適当に変換する必要があります(256倍して整数にキャストするだけだが)。
その、キャストしながらコピーしているのがここの処理です。
for i in range(28):
for j in range(28):
pix[i, j] = int(data[i+j*28]*256)
あとは画像データとして保存するだけですが、そのままだと小さすぎるので10倍に拡大してみます。リサイズすれば良いだけなんで簡単です。
img2 = img.resize((280, 280))
あとはimg2.save("hoge.png")とかすればPNGフォーマットで保存できます。
まとめ
Chainerを使ってMNSITデータを取得し、Pillowで画像データとしてディレクトリごとに仕分けしながら保存するスクリプトを作ってみました。実際に画像をダンプしてみると、同じ数字でもわりとバラエティがあって面白いです。例えば7なら、
シンプルな奴
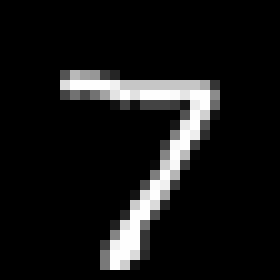
1と区別するための横棒つきの奴
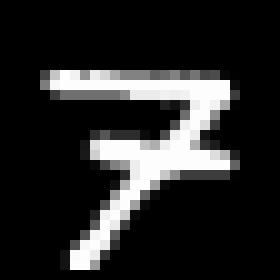
縦棒をつけてカタカナの「ワ」みたいにする奴
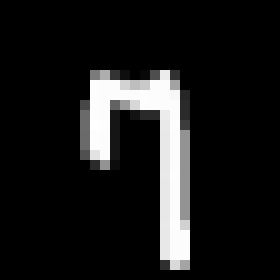
みたいなのがあります。横棒をつける流儀は欧米で、縦棒をつける流儀は日本でよく見かける気がしますが、どうなんでしょうね?