はじめに
SIMD化、してますか?>挨拶
「京」が128bit、現在のx86系の石が256bit、そしてポスト「京」がSIMD幅可変、ハード512bitという話もあって、もはやSIMD化しないといろいろつらいというか、ポスト「京」が走りだす時に、えらいひとたちがSIMD化率を気にしだしたり、アプリケーションごとにSIMD化率を提出させられたりするような未来が見えなくもないので、私もSIMD化してみようと思います。
で、「ステップ・バイ・ステップ」とあるけれど、これは教材という意味ではなくて、単に私がどういう形でSIMD化をしていったかの作業記録を保存しようという試みです。もっとすごい人はもっとスパッとSIMD化しているんだと思います。
背景
これまでのあらすじ。
で書いたように、古典分子動力学法でよく使われるカットオフ付きLennard-Jones (LJ)ポテンシャルの力計算をAVX/AVX2の命令を使ってSIMD化してみた。その結果、SIMD化していない最速コードに比べて、SIMD化によって33%程度実行時間が短縮したんだけれど、4倍幅使ってるのに、ちょっと加速率が物足りない。特に問題なのは、粒子系が低密度の場合の加速率が悪い、ということだった。
SIMD化は、ループを4倍展開して自明に独立な演算を4つ作ってSIMD化する、馬鹿SIMD化を採用しているのだが、高密度でループ長が60前後、低密度だと30前後になるため、4倍展開のゴミが見えている可能性がある。
そこで、低密度粒子径でも、もっとループ長が取れる形の計算を馬鹿SIMD化することで、もっと高速化できないか考えた。これから書くのはその作業記録。
ソースコード
SIMD化の元になるコードは https://github.com/kaityo256/lj_simdstep/tree/master/step0 においてある。
ペアリストをO(N^2)で作成していて時間がかかるので、ファイルにキャッシュするようにした。力の計算が4種類定義されているが、それぞれ以下の通り
- force_pair ペア毎に力を計算する
- force_sorted i粒子をキーにソートし、j粒子に対してループを回す
- force_sorted_swp force_sortedを手でソフトウェアパイプライニングしたもの
- force_sorted_intrin force_sortedを手でSIMD化したもの
ペアリストを作成すると、こんな感じで粒子のペアができる。

このペア番号でループを回すのがforce_pair。
で、この方法だと、i粒子とj粒子の情報を毎回ロード/ストアしなければならない。LJの力計算はかなり軽いので、このメモリアクセスのペナルティはわりと大きい。そこで、i粒子をキーにしてソートする。

すると、i粒子の情報がレジスタに載るため、メモリアクセスが減る。これをやったのがforce_sorted。
i粒子の情報がレジスタに載っている前提では、力の計算は
- j粒子の座標を取ってくる
- 相対ベクトルを計算する
- 距離を計算する
- 距離から力を計算する
- 力から力積ベクトルを計算する
- 力積ベクトルを運動量に書き戻す
というステップをとる。このうち、1-2と3-6をループごとにずらして、独立な計算にする。1-2の処理をA、3-6の処理をBとすると、ソフトウェアパイプライニングというのは以下のようなイメージ。
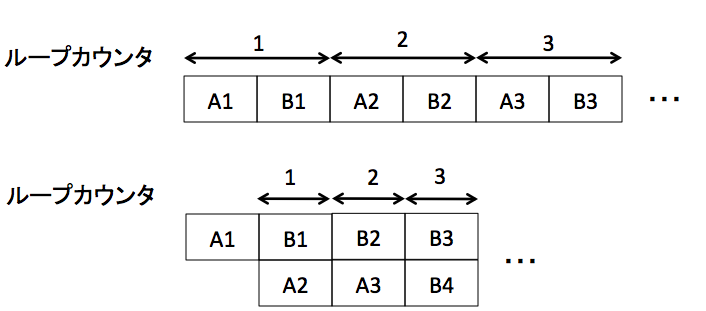
上が普通の処理、下がソフトウエアパイプライニングしたもの。全体の処理内容は変わっていないが、BnはAnが終わらないと実行できないが、BnとAn+1は独立に実行できるから、それを明示的に重ねてIPCを増やしましょう、という方法論。x86ではわりと効果的な最適化手法。もちろんコンパイラは勝手にはやってくれない。
SIMD化方針
SIMD化については、とりあえずデータを
double q[N][4];
double p[N][4];
と4次元ベクトルにしておいて、vmovupdで4成分を一度にロード、あとは適当にシャッフルして4つの力を一度に計算する。
で、低密度で性能が出なかったのは、ループ長が短いせいもあるだろうと考え、i粒子でソートする前のもの、つまりペアでループを回して力を計算する、force_pairをSIMD化することを考える。
ただし、そのままではメモリアクセスのペナルティが大きく、性能が出ないことが予想されるため、
- ペアごとの力の計算ルーチン force_pairを ソフトウェアパイプライニングする
- それを4倍展開する
- それをSIMD化する
というステップを踏むことにしよう。
性能
現状での性能は以下の通り。
| 計算手法 | 実行時間[sec] | 備考 |
|---|---|---|
| pair | 8.166132 | ペアごとにループをまわしたもの |
| sorted | 7.029136 | 相互作用相手でソートして、二重ループにしたもの |
| sorted_swp | 5.79193 | ソートしたものを手でソフトウェアパイプライニングしたもの |
| sorted_intrin | 3.890581 | ソートしたものを手でSIMD化したもの |
目標は、最後の「sorted_intrin」の速度を超えること。