全体の目的
Apache Beam の簡単なプログラムを作成して,仕組みを理解していく
前回の内容
起動の確認も兼ねて,読み込んだテキストをそのまま書き出した
Apache Beam 入門(1) ~テキスト読み書き~
今回の目的
読み込んだテキストの各行に対して,ParDo処理を行うことによってデータ型を変更
具体的には,「Bitcoinのティッカー情報をテキストデータから読み込み,それそこから任意の値を抽出する」という処理をします.
そもそもParDoって何?
Core Beam Transforms
Beamは以下の6つを基本的なデータの変形として提供している(処理の大枠みたいな感じ)
- ParDo (今回やる)
- GroupByKey
- CoGroupByKey
- Combine
- Flatten
- Partition
この内の1つがParDo
どんな処理?
- MapReduceのアルゴリズムのMapの部分を担う
- input として受け取ったPCollectionに対して処理を行う
- 0個または 1個 あるいは複数のPCollectionを出力する
要するに入力データ(1個)に何らかの加工をして出力(個数は問わない)する処理
本編
環境
前回と同じ
IntelliJ IDEA 2017.3.3 (Ultimate Edition)
Build #IU-173.4301.25, built on January 16, 2018
Licensed to kaito iwatsuki
Subscription is active until January 24, 2019
For educational use only.
JRE: 1.8.0_152-release-1024-b11 x86_64
JVM: OpenJDK 64-Bit Server VM by JetBrains s.r.o
Mac OS X 10.12.6
Maven : 3.5.2
手順
使用するテキストデータ
使用するデータは以下のもので,
bitflyer における BTC/JPY のレート情報を10秒おきに取得したデータ10回分です.
<トレードシンボル>,<取引所名>,<タイムスタンプ>,<ASK>,<BID>の順です.
BTC/JPY,bitflyer,1519845731987,1127174.0,1126166.0
BTC/JPY,bitflyer,1519845742363,1127470.0,1126176.0
BTC/JPY,bitflyer,1519845752427,1127601.0,1126227.0
BTC/JPY,bitflyer,1519845762038,1127591.0,1126316.0
BTC/JPY,bitflyer,1519845772637,1127801.0,1126368.0
BTC/JPY,bitflyer,1519845782073,1126990.0,1126411.0
BTC/JPY,bitflyer,1519845792827,1127990.0,1126457.0
BTC/JPY,bitflyer,1519845802008,1127980.0,1126500.0
BTC/JPY,bitflyer,1519845812088,1127980.0,1126566.0
BTC/JPY,bitflyer,1519845822743,1127970.0,1126601.0
このテキストを読み込み,ParDoを使って各行から任意の情報(今回はBID)を抽出します.
コード変更
今回のコードは以下のようになります.
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.values.PCollection;
public class SimpleBeam {
// 追加
public static class ExtractBid extends DoFn<String, String> {
@ProcessElement
public void process(ProcessContext c){
// 行を取得
String row = c.element();
// コンマで分割
String[] cells = row.split(",");
// BID を返す
c.output(cells[4]);
}
}
public static void main(String[] args){
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
// テキスト読み込み
PCollection<String> textData = p.apply(TextIO.read().from("Sample.txt"));
// ココから追加
PCollection<String> BidData = textData.apply(ParDo.of(new ExtractBid()));
// ココまで追加
// テキスト書き込み
BidData.apply(TextIO.write().to("output/bid"));
// Pipeline 実行
p.run().waitUntilFinish();
}
}
前回のコードの出力が"wordcount"になっていてサンプルコピペしたのまるわかりだったので,出力先を変更しました...
実行方法は前回と同じなのでこちらを参照してください.
実行結果
実行結果は以下のようになっており,BIDのデータ(Sample.txtの一番右側)が抽出できていることがわかります.
今回は簡単化のためにStringを1つだけ抜き出す処理にしましたが,これによりデータ型の変更やデータ整形などが行なえます.
このような処理でinputデータに任意のKeyを設定してReduce処理に移ることができます.
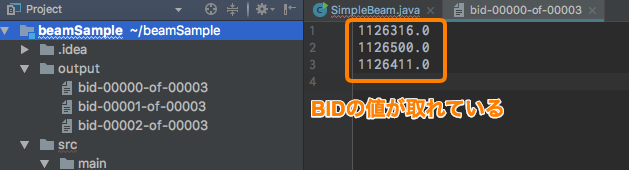
画像のように出力が3つのファイルに分かれているのはMap処理を完了し,次にReduce分散して実行するためなのかな?
SimpleFunction について
同じような処理を実現するのにSimpleFinctionというクラスが用意されており,何が違うのか気になって調べたのでおまけ程度にまとめておきます.
公式ドキュメントによると,
If your ParDo performs a one-to-one mapping of input elements to output elements–that is, for each input element, it applies a function that produces exactly one output element, you can use the higher-level MapElements transform. MapElements can accept an anonymous Java 8 lambda function for additional brevity.
という感じで無名関数を用いてParDoのDoFnよりも抽象的かつ簡易的に処理を記述できるという話みたい
SimpleFunctionを使って書き直してみる
コード
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.values.PCollection;
import org.apache.beam.sdk.values.TypeDescriptors;
public class SimpleBeam {
public static void main(String[] args){
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
// テキスト読み込み
PCollection<String> textData = p.apply(TextIO.read().from("Sample.txt"));
// 無名関数を使って同じ処理を実装
PCollection<String> BidData = textData.apply(
MapElements.into(TypeDescriptors.strings())
.via((String row) -> row.split(",")[4])
);
// テキスト書き込み
BidData.apply(TextIO.write().to("output/bid"));
// Pipeline 実行
p.run().waitUntilFinish();
}
}
だいぶシンプルになった!
少しの間Beamを触った所感としてはただ単にデータ型を変更するだけの処理とかが合ってその都度DoFnを作るのは結構手間なので,積極的に利用していきたい.
つまりそうなところ
Java8を有効化できない
通常の変更方法
File => Project Structure...
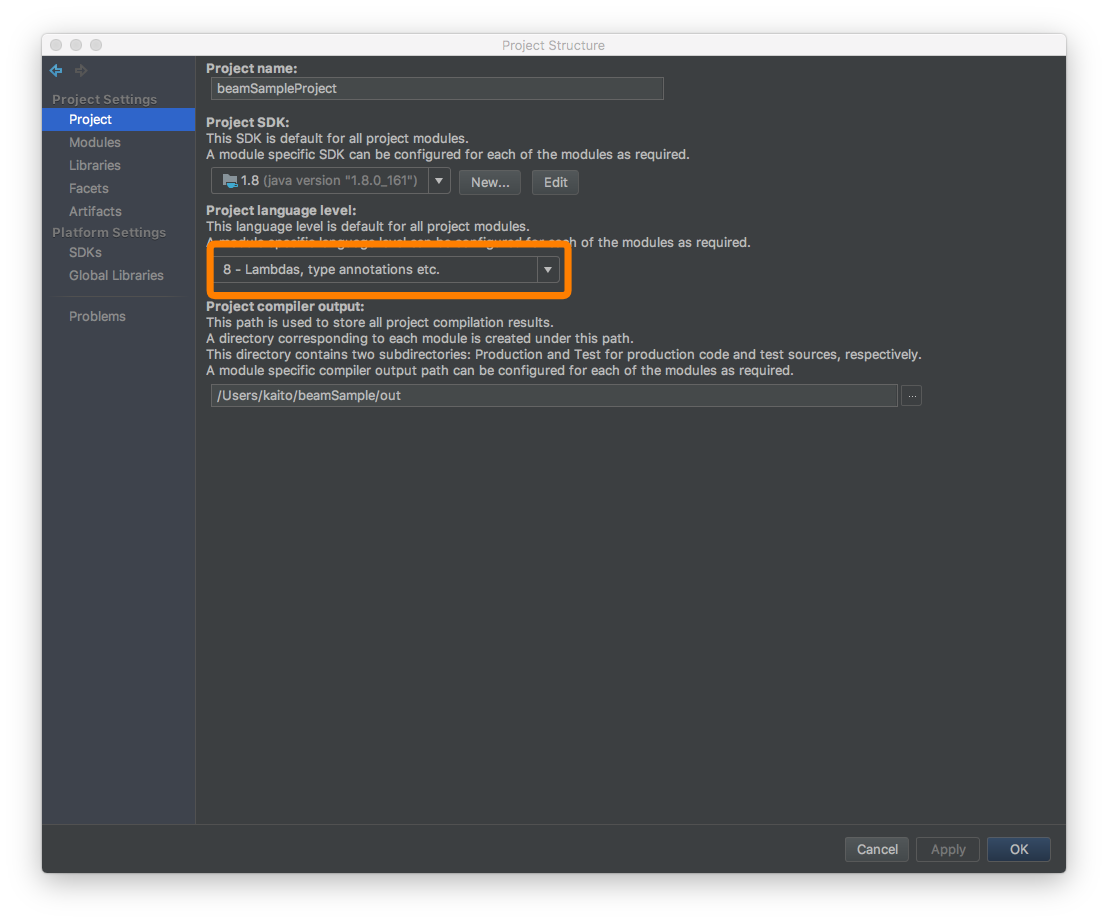
ProjectSettings => Project => Project language level を 8 に設定
それでも通らない...そんなときは以下の手順
解決策
pom.xmlに以下の記述を追加
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>beamSample</groupId>
<artifactId>beamSample</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 1.8を認識してもらうために追加 -->
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<!-- ココまで追加 -->
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>2.4.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
</project>
次回以降
今回はMapReduceのMap処理に相当するParDoを実装してみた.
次回はReduce処理を簡単に実装してティッカー情報の平均などを求めたい.