はじめに
複数のAIエージェントを用いてドットイートゲームをクリアしてみました。
ソースコードはこちらになります。

背景
こちらの記事を読んで、自分でもAIの力を使ってゲームをクリアしてみたいと思ったのがきっかけです。
しかし、ただクリアするだけでは面白くないと思ったのと、AIエージェントが協力するとどういった行動が見られるか気になり、複数のAIエージェントを用いてみました。
目標
今回のプログラムは以下の2つを目標に作成しました。
-
ゲームクリア
まず最低限、自分が設定した簡易的なドットイートゲームのクリアを目指します。 -
利他的行動の発現
AIエージェントの環境認識機能を工夫することで、ゲームクリア(ドットを全て回収)するための利他的な行動を発現させます。
ここでいう利他的な行動というのは、敵をひきつける囮になるなどの、自身の利益ではなく全体の利益になるような行動を指します。
予備知識
-
ドットイートゲーム
ドットイートゲームとは、コンピュータゲームのアクションゲームのジャンル。敵の追跡から逃れつつ、迷路内に敷き詰められた目標(大抵はドットで表現される)の上を通過することで消していくゲームである。(Wikipedia引用)
いわゆるパックマンです。 -
強化学習
強化学習は犬に芸を覚えさせる方法と一緒です。
「お手(行動)をしたらおやつ(報酬)を与える」というのを繰り返すと、犬はお手をしたらおやつが貰えるというのを学習し、お手を何度も行うようになります。
強化学習はこの学習方法を模倣したもので、エージェント(犬)の行動によって報酬を与えて、最適な行動を学習させる方法になります。
強化学習についてはこちらの方が詳しく説明されているので、気になる方は是非見て下さい。
今回作成したプログラムでは、強化学習の1つであるQ学習という学習方法を採用しています。
ゲームの概要
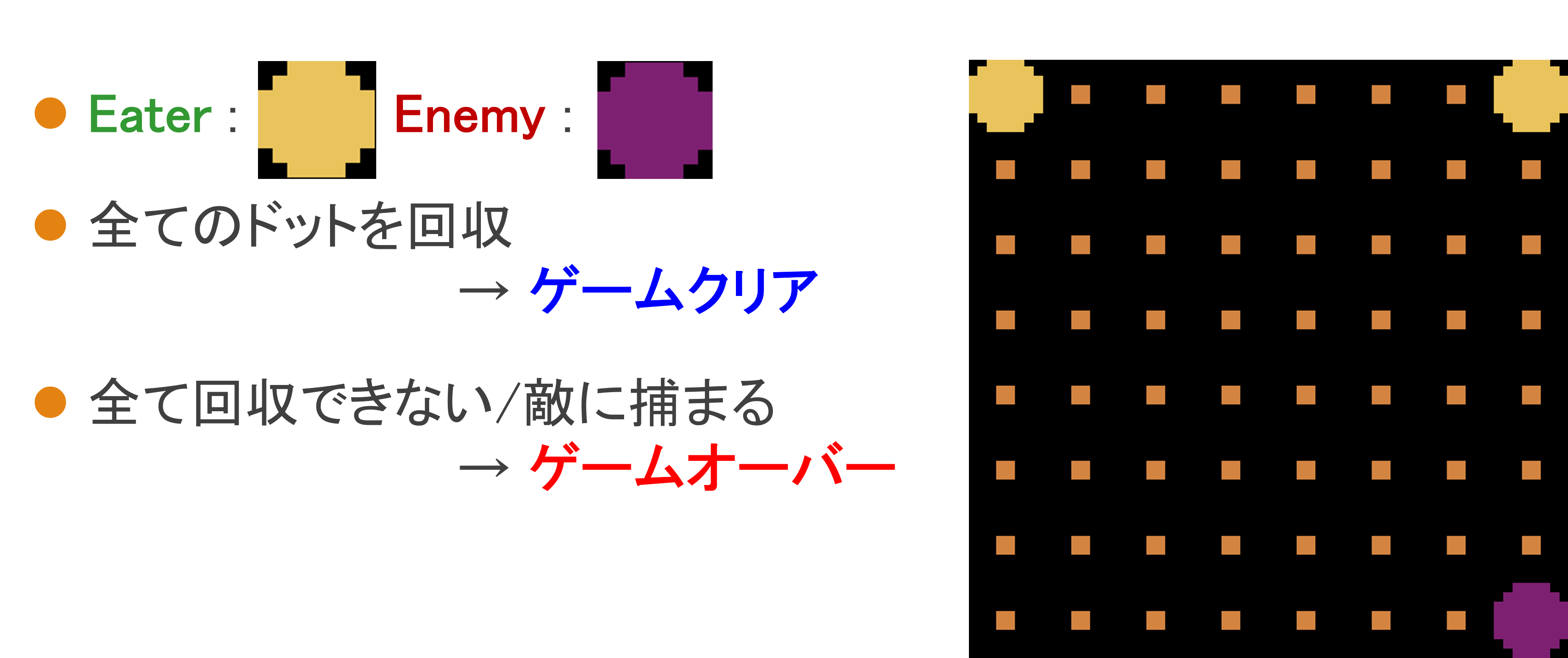
Eater
EaterはEnemyから逃れつつ、マップに敷き詰められたドットを全て回収することが目的になります。
自身が認識している環境の状態から、行動を行い、行動の結果から報酬を得ます。
学習パラメータ
Q学習を行うにあたって必要なパラメータの値は以下のように設定しました。
| 設定 | 値 |
|---|---|
| α(学習率) | 0.1 |
| γ(割引率) | 0.9 |
| k(探索率の係数) | 0.9999 |
報酬
Eaterが受け取る報酬は以下のように設定しました。
| 行動 | 報酬 |
|---|---|
| 移動 | -1 |
| ドットを回収 | +5 |
| 壁にぶつかる | -10 |
| Eaterにぶつかる | -1 |
| 敵にぶつかる | -50 |
| ドットを全て回収* | +50 |
*ドットを全て回収したときの報酬は、全てのEaterに与えられます。
環境認識機能
環境認識機能とは、人間でいうところの視覚や聴覚などの五感にあたります。
実際に私自身がEaterの気持ちになったとき、ゲームをクリアするために必要な認識機能と、他のEaterと協力するために必要な認識機能は何かと考えた結果、以下の5つになりました。
-
周囲2マス
Eaterの周囲2マスに何があるか認識できる。 -
残存ドット数
マップの中に残っているドットの数を認識できる。 -
自身の位置
マップの中での自身の位置を認識できる。 -
Eaterの位置
マップの中にいる他のEaterの位置を認識できる。 -
Enemyの位置
マップの中にいる敵の位置を認識できる。
以上の5つの認識機能を持って、他のEaterと協力しながらゲームクリアを目指します。
Enemy
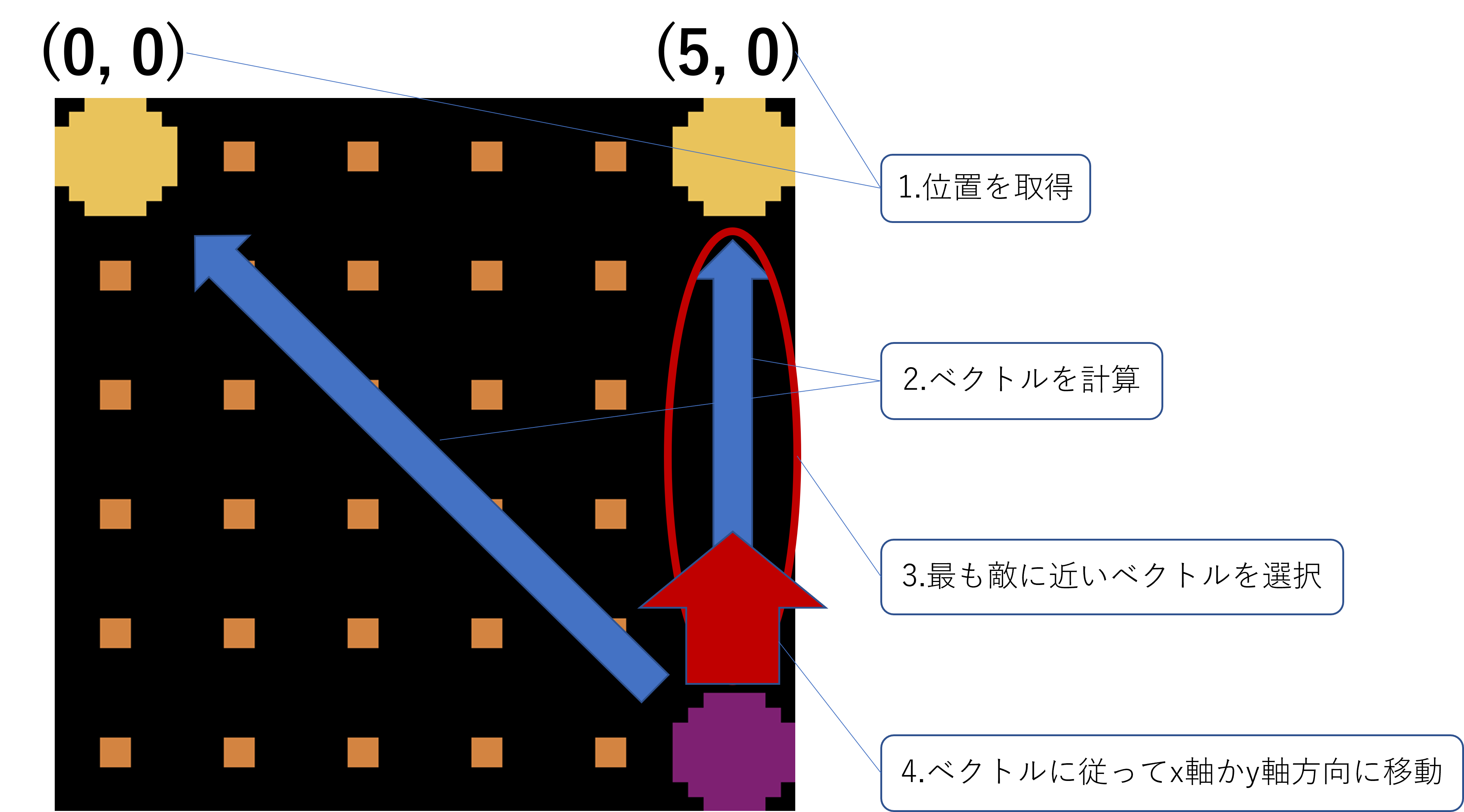
EnemyはEaterを追いかけて、捕まえることが目的になります。
Eaterを追いかけるアルゴリズムは以下の図のようになります。
プレイ画面
プレイの様子は以下のようになります。
EaterがEnemyを連れて、他のEaterがドットを取りやすくしてる様子が見られました。

苦労ポイント
-
処理時間
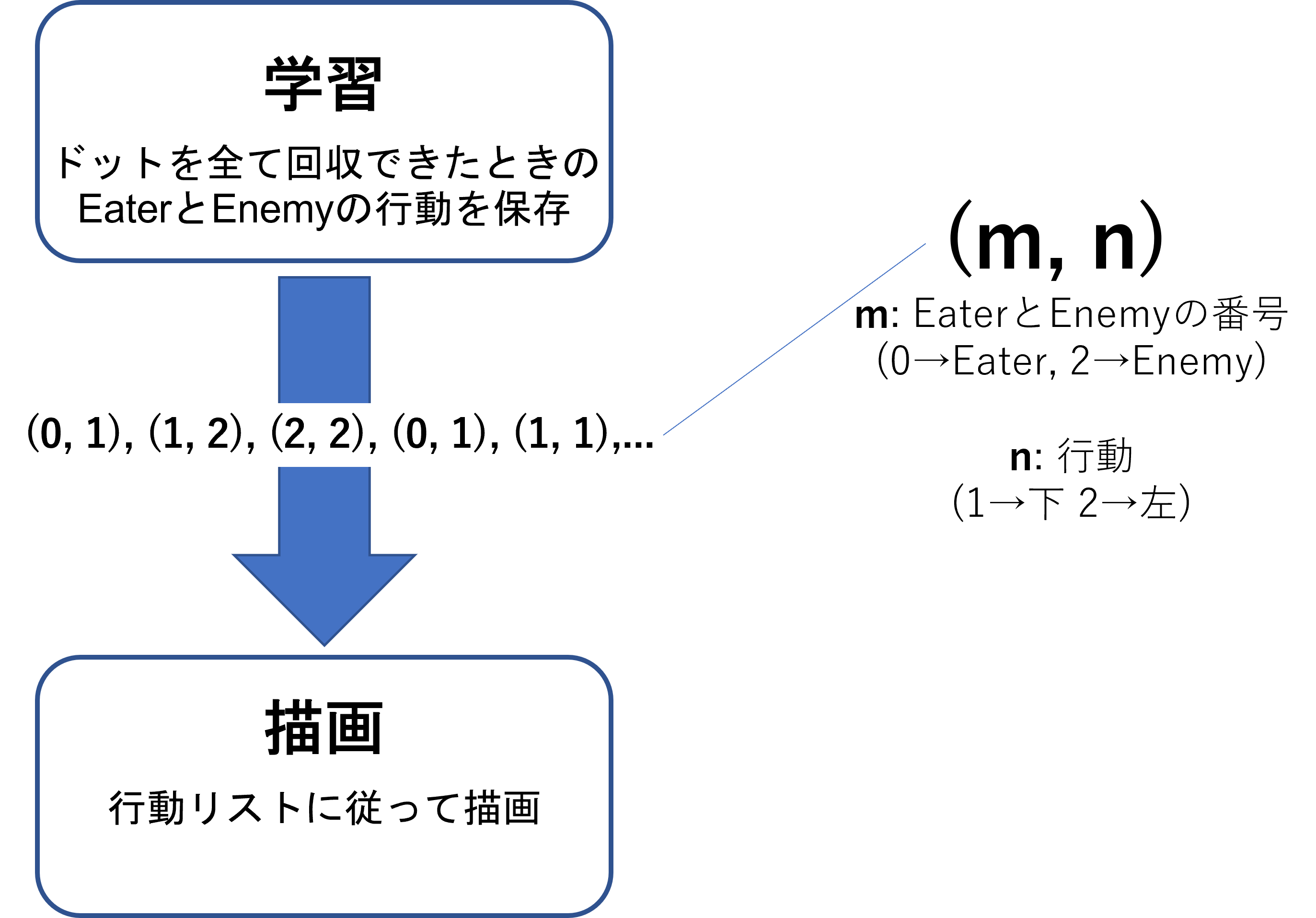
最初Pyxelのゲーム上で描画しながら学習をしていたのですが、まともな動きをするまでかなり時間がかかっていました。
そこで学習パートと描画パートを分けて、処理時間を短くしました。
-
学習
強化学習では最適な行動を見つけるために、一定確率でランダムな行動を取ります。(ε-greedy法)
一定確率の場合、Enemyから逃げてる途中で急に壁にぶつかったり、Enemyにぶつかりにいったりする行動が見られて、学習が上手く進めることが出来ませんでした。
そこで学習が進むとランダムな行動を取る確率を下げるように設定し、うまく学習が進むようにしました。

まとめ
Enemyを引きつける囮になり、他のEaterにドットを回収してもらうといった利他的な行動が見られて、とても面白かったです。
追加で、マップをもっと複雑にしたり、EnemyがEaterを追いかけるアルゴリズムを改良しようと思います。
間違っている点などありましたら教えて頂けると幸いです。
ここまで読んで頂き、ありがとうございました。