DynamoDB もしばしば使われますが、KVS よりちょっと複雑な印象で敬遠してました。
無理やり機会を作って触ってみました。
環境構築、テストデータ
開発やテスト用の DynamoDB Local の Docker Imageがありますが、AWS のマネジメントコンソールからクエリを発行できたりするので AWS を使います。
今回はランチの評価データを管理してみます。
- ユーザID
- 店名(本当は店IDが良いかもしれませんがわかりやすいので…)
- コメント
ユーザIDと店名をキーにしてみます。
今回は Ruby と AWS SDK でやってみます。
テーブルを作成する
require "json"
require "aws-sdk"
TABLE = "meals"
dynamo = Aws::DynamoDB::Client.new(
region: "ap-northeast-1",
access_key_id: ENV["AWS_ACCESS_KEY_ID"],
secret_access_key: ENV["AWS_SECRET_ACCESS_KEY"],
)
options = {
table_name: TABLE,
key_schema: [
{
attribute_name: "user_id",
key_type: "HASH"
},
{
attribute_name: "shop_name",
key_type: "RANGE"
}
],
attribute_definitions: [
{
attribute_name: "user_id",
attribute_type: "N"
},
{
attribute_name: "shop_name",
attribute_type: "S"
}
],
provisioned_throughput: {
read_capacity_units: 1,
write_capacity_units: 1
}
}
# NOTE: テーブル作成は非同期。この直後にデータ挿入を行うとテーブルがなくてエラーになります。
dynamo.create_table(options)
データを挿入する
100.times do |n|
# NOTE:一括はbatch_write_itemのほうが速いです
dynamo.put_item(
table_name: TABLE,
item: {
user_id: [1, 2, 3].shuffle[0],
shop_name: %w(海 馬 山 川 山本 鈴木 ゴン キン ベジ).shuffle[0] + %w(寿司 ラーメン カレー 中華 アジアン 食堂).shuffle[0],
text:
%w(ぎとぎとしてて さっぱりしてて ぬるぬるしてて まったりしてて ぱさぱさで).shuffle[0] + %w(美味しかった うんま! まずかった まずまずだった くっせ!).shuffle[0]
}
)
end
雑ですが適当に、ユーザ1〜3がいろんな店のコメントを書いている、というデータを挿入しました。
データを読み出してみる
Rubyでやってもよいですが、AWSのコンソールに触れてみたかったのもあり、触ってみます。
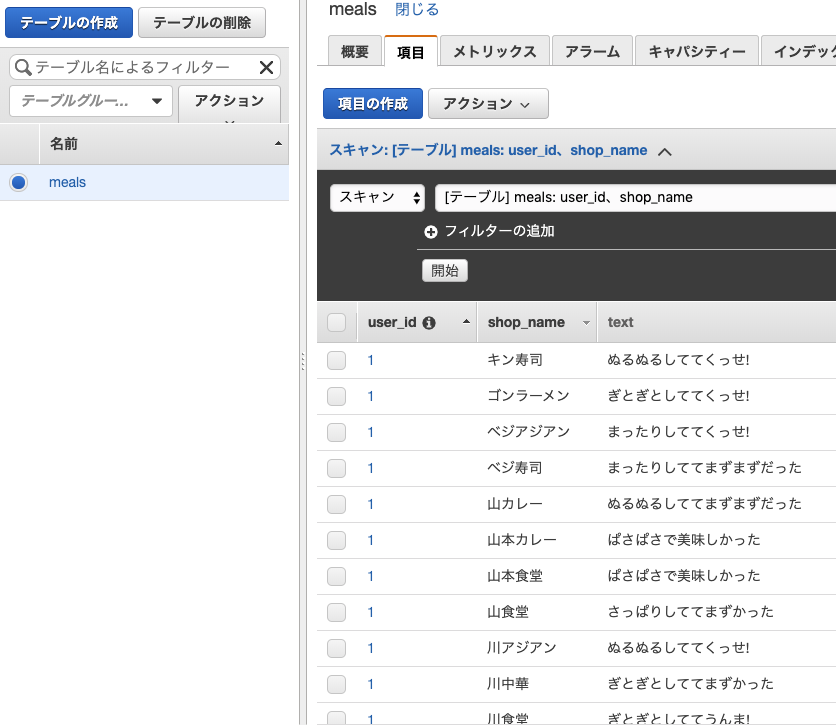
おー、入ってる。キーがユーザIDと店名なので2回目の来店で上書きされてますね。
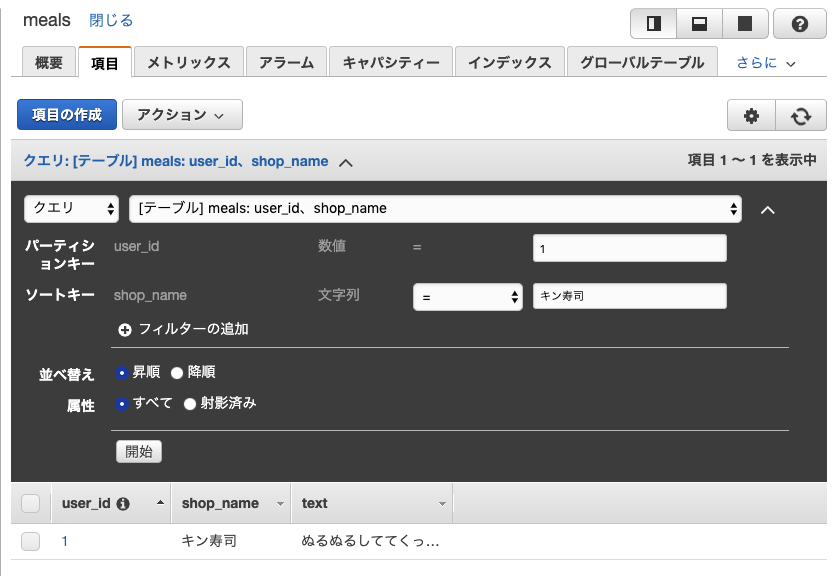
誰が、どの店を、の条件で検索もできました。
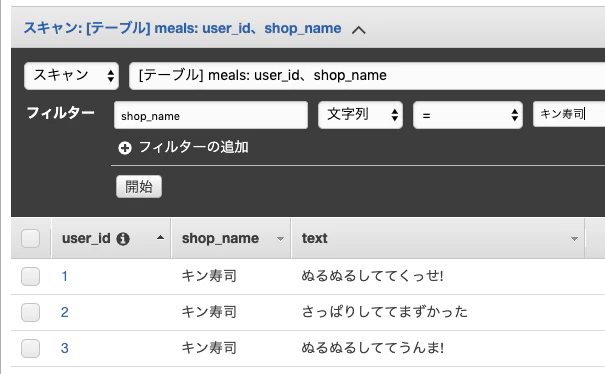
キン寿司の評価を探してみました。
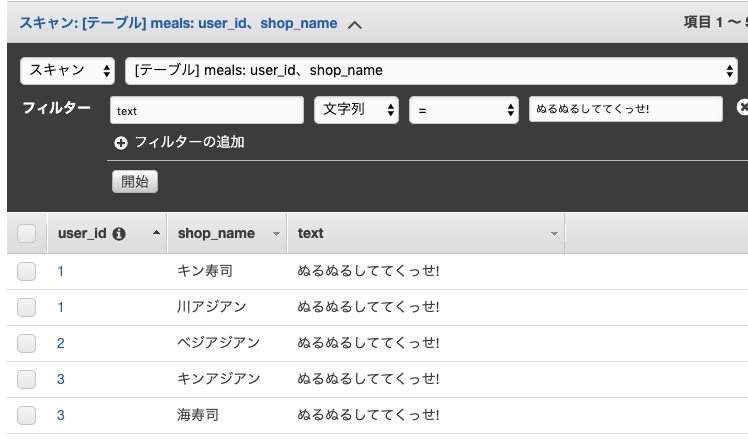
key に指定していない text で探すこともできた。
本当か!? indexとは?
向いていること
- KVS。シンプルでメンテのいらない高速なKVSとして使用できます
- 副業主キーが表現できる
- データを挿入さえしてしまえばkeyではない項目でも検索できる(まじか? コンソールだけの機能かも)
向いていないこと
- RDBにあるような参照や制約
まとめ
スキーマレスでキーを複数指定できるKVSです。
スキーマレスではありますが、キーの定義は必要で、テーブル定義がとっつきにくく感じました。
躓いた感があり、十分に評価できていません。
memcachedより複雑なデータ構造を扱うことができ、運用のことを考えなくて良いのが良いところですね。