JavaScript の Segments という機能を知りました。
JavaScript って標準 API でこんなこともできるのかhttps://t.co/ckHTlqcium pic.twitter.com/hrwfgvtF4J
— naporitan (@naporin24690) December 25, 2023
これは面白い! ブラウザの標準機能で自然言語処理ができる時代だ!
とりあえず、お手元で試したい方はこちらをどうぞ。お使いのブラウザの console に貼り付ければ動くはずです。
const segmenter = new Intl.Segmenter("ja", { granularity: "word" });
const string1 =
"東京都府中市は「とある科学の超電磁砲」の舞台ではない。京都府中京区も違う。";
const segments = segmenter.segment(string1);
console.table(Array.from(segments));
こんなことができるというサンプルです。
https://pokosho.com/a/js_nlp/
何ができる?
例えば、文章から単語を取り出してタグクラウドを作ったりするには、バックエンドで自然言語処理を行う必要がありました(kuromoji.js や TinySegmenterという選択肢もあります)。
これがフロントエンドだけで完結できる可能性があります。
Chrome 87 (2020/11/17〜)から使えます。結構昔から使えたんですね。
API 仕様
Segmenter
const segmenter = new Intl.Segmenter("ja", { granularity: "word" });
第一引数は locale です。
第二引数は options で、granularity (粒度) を指定できます。
word, sentence, grapheme のいずれかを指定します。
それぞれオプションについてみます。
word
単語に分割します。これは上にサンプルがあるので割愛。
isWordLike が返却されており、記号などの場合は false になっています。
sentence
文節に分割します。
文頭に上げた例だと以下になりました。
- 東京都府中市は「とある科学の超電磁砲」の舞台ではない。
- 京都府中京区も違う。
最近の日本語は末尾に「。」をつけないケースや絵文字をつけるケースも多いのですが、この辺は対応していません。
ざっくり触った感じだと「。」と改行を文節として見なすようです。
これなら split を使ったほうがいい気もしますね。
grapheme
これは初めて見る方も多いのではないでしょうか。日本語だと「書記素」と言うそうです。一つの音を表すために使われる文字であるようです。「あ」「ふぁ」とかでしょうか?
試した見たところ「ファミリー」は「フ」「ァ」「ミ」「リ」「ー」になりました。
これも split("") を使ったほうが良い気がします。
よく使われる例が「正しく文字数をカウントする」です。
ハングル、タイ語、タミル語など複数の組みわせで一つの文字になる言語は多くあり、
Unicodeのコードポイントを数えただけだと、人間が捉える文字数とずれてしまうためです。
また、絵文字のカウントにも有用です。(thx @oswe99489)
const str = '👩👩👦👦👩👩👦👨👧';
// 文字列を配列にして出力する
console.log([...str]);
// ['👩', '', '👩', '', '👦', '', '👦', '👩', '', '👩', '', '👦', '👨', '', '👧']
console.log([...new Intl.Segmenter('ja', { granularity: 'grapheme'}).segment(str)].map(v => v.segment));
// ['👩👩👦👦', '👩👩👦', '👨👧']
segment
const segments = segmenter.segment("今日はいい天気");
引数に文章を渡し、戻り値は Segments のイテレーターです。
segment は以下を保持しています。
- segment: 分割された文章
- index: 元の文章に対する segment の index
- input: 元の文章
- isWordLike:
word指定時のみ返却。単語っぽい場合 true
触ってみた
granularity: word 以外は日本語だと使い物にならなかったので word を指定した場合について調べてみました。
きちんと単語を分割できるか? 東京都府中市、京都府中京警察署
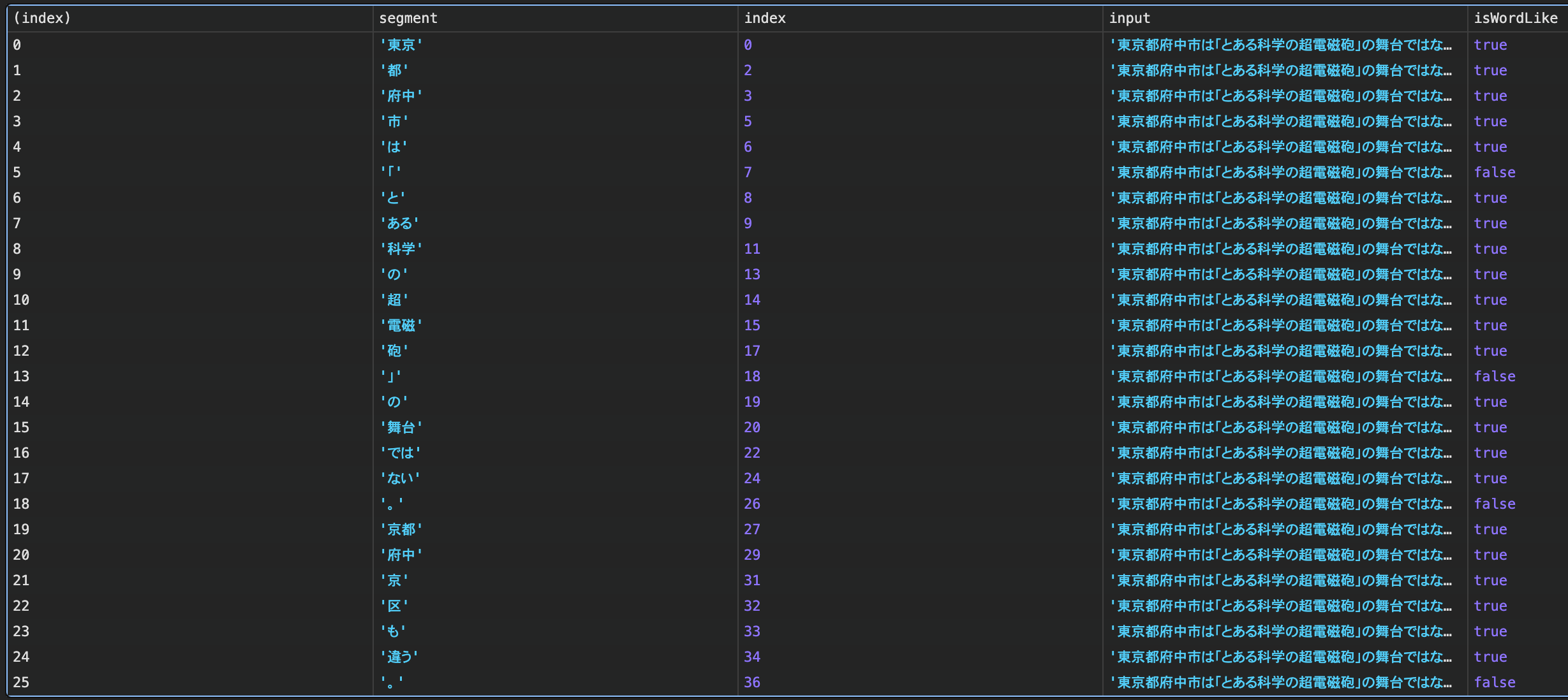
日本語の分割は難しいです。「東京都府中市」「京都府中京区」はどちらも「府中」を含みますが、後者は府中で切ってはいけません。
(京都府中京区は正確には京都府京都市中京区ですね… 京都府中京警察署とかにすればよかったですね…)
固有名詞の扱いは? とある科学の超電磁砲
「とある科学の超電磁砲」は作品名なので一単語にしてほしい場合もあります。
上記のスクショの通り残念でしたが、これが正しく分割できる方法があるといいですね。
要望
ブラウザで簡単な単語分割ができてすごい!
…がもう一歩という印象でした。
- 精度が悪い
- 辞書のカスタマイズができない
- よみがな、品詞、基本形などが得られない
この辺が改善されると最高ですね!
いや、バックエンドでやれというオチかもしれませんが…
使い所を考えてみた
以下のユースケースを思いつきました。
NG ワードチェック
以前 Twitter の NG ワードチェックが雑すぎると話題になった覚えがあります。
例えば「マラソン」の先頭 2 文字だけだと淫語なのかもしれませんが「マラソン」は淫語ではありません。
Segments で分割して NG ワードを含むか見るとこの問題を解決できそうです。
単語数を把握する
- 入力された文章に罵詈雑言が多用されていた場合をチェックしたいようなケース
- 文字数ではなく単語数で入力制限したいケース
いや、そんなケースあるのかと言われると疑問ですが…
テキストの上位 30 作ってみたので触ってみてください。助詞(てにおは)が取り除ければ使い道が増えそうなんだが…
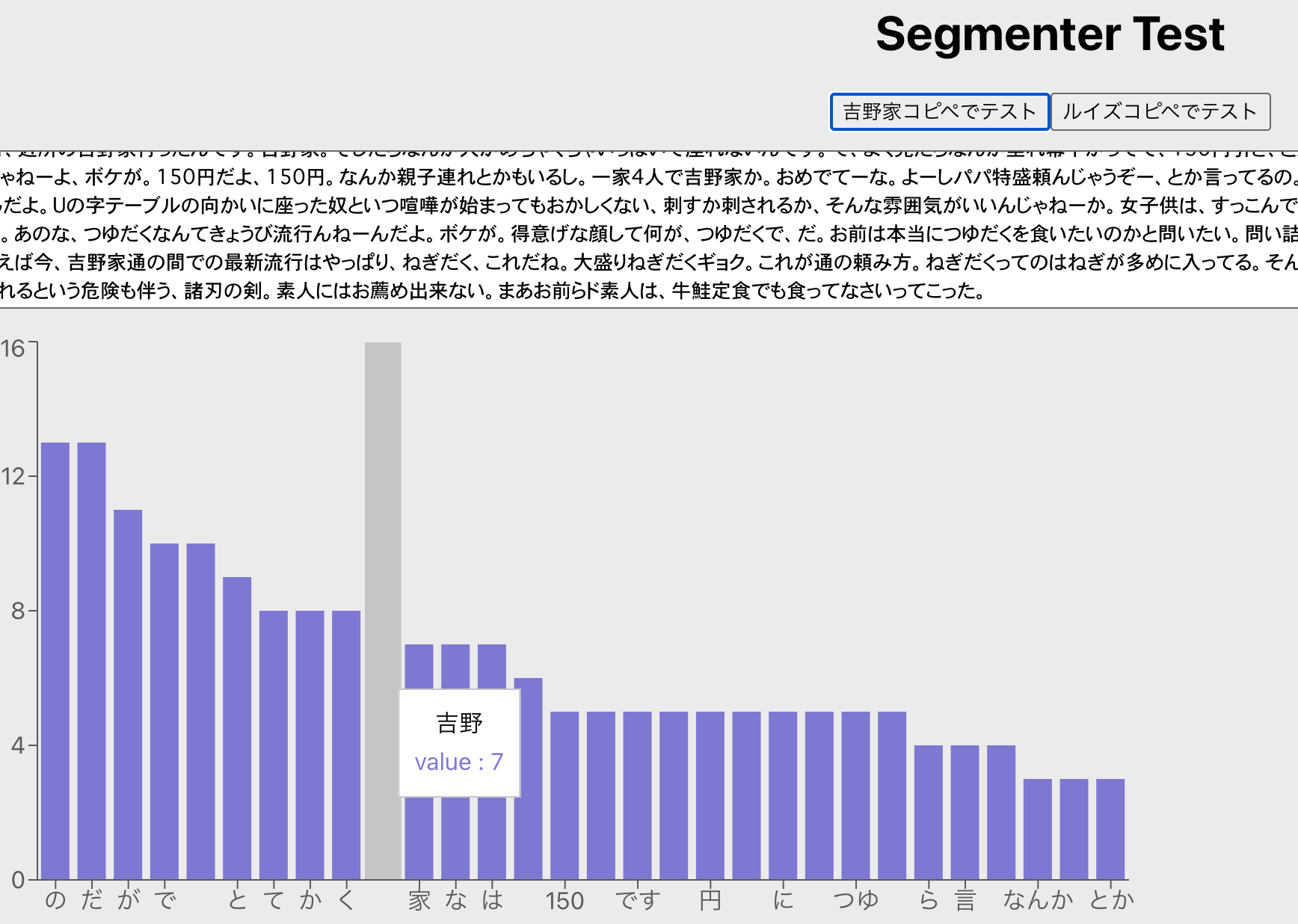
吉野家コピペは確かに吉野家について熱弁していることがわかりました。
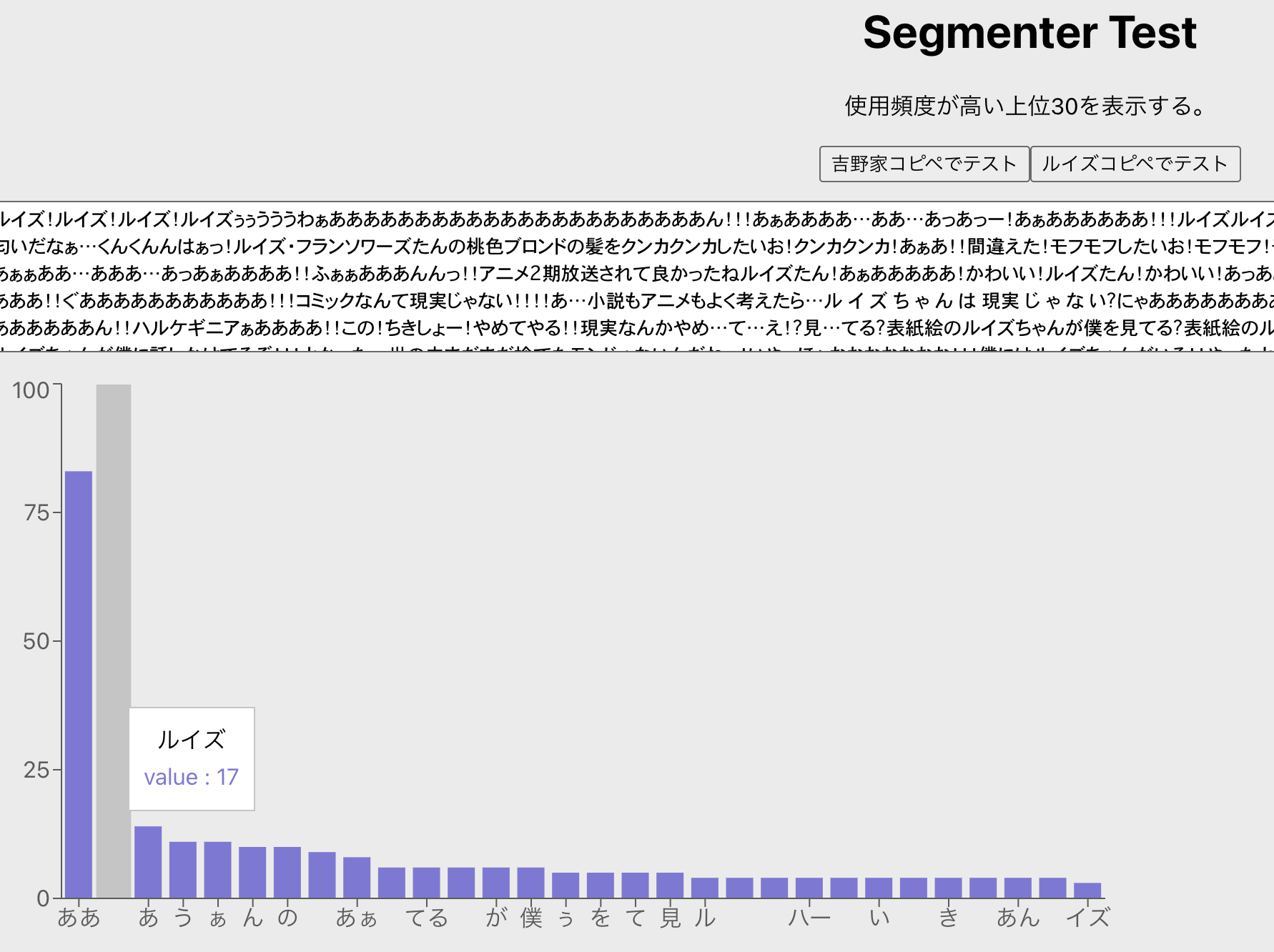
ルイズコピペはルイズたんについて熱く語っていることがわかりました。
これは大きな発見ですよ!(ではない)
その他の情報
ブラウザごとの実装
標準APIなのでブラウザの実装によるところがあると思います。
Chrome, Safari は違いが見つかりませんでした。
Firefoxは残忍ながらサポートしていません。
CSS の word-break で使いたい
word-break: auto-phrase;
というのがあります。恐らく同じ部品を使って実装しているのではないでしょうか?
https://developer.chrome.com/blog/css-i18n-features?hl=ja
終わり
自然言語処理目的だと機能が足りず使い所が難しい API でした。良い使い所思いついたらコメントください。