今回のデータは成績データを使って分析したいと思う。
ライブラリの読込み&データ作成
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
plt.rcParams['font.family'] = 'MS Gothic'
warnings.filterwarnings('ignore')
df = pd.DataFrame({'出席回数' : [15,15,14,10,12,8,10,15,15,13],
'課題提出回数': [15,15,14,5,10,8,10,15,14,15],
'ノートを取った回数': [0,15,14,10,12,0,0,0,0,13],
'テスト点数': [45,98,85,68,75,3,5,25,32,71]})
df.index = df.index+1
df = df.reset_index()
df = df.rename(columns={'index':'学籍番号'})
df.head()
相関係数を算出
df[['出席回数', '課題提出回数', 'ノートを取った回数', 'テスト点数']].corr()
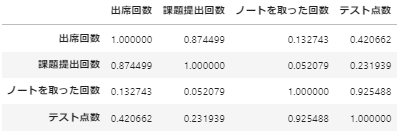
ヒートマップ相関係数を算出
colormap = plt.cm.RdBu
plt.figure(figsize=(14,12))
plt.title('相関係数', y=1.05, size=15)
sns.heatmap(df[['出席回数', '課題提出回数', 'ノートを取った回数', 'テスト点数']].astype(float).corr(), linewidth=0.1, vmax=1, square=True, cmap=colormap, linecolor='white', annot=True)
テストの点数ヒストグラム
df['テスト点数'].plot.hist(bins=range(0, 100, 10))
plt.xlabel('テストの点数')
plt.ylabel('人数')
plt.title('テストの点数')
plt.legend()
plt.show()

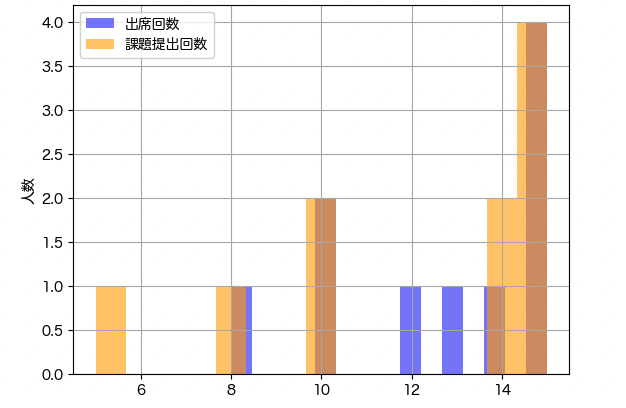
出席回数と課題提出回数
df['出席回数'].hist(alpha=0.5, bins=15, label='出席回数', color='blue')
df['課題提出回数'].hist(alpha=0.6, bins=15, label='課題提出回数', color='orange')
plt.ylabel('人数')
plt.legend()
plt.show()
出席回数とノートを取った回数
df['出席回数'].hist(alpha=0.5, bins=15, label='出席回数', color='blue')
df['ノートを取った回数'].hist(alpha=0.4, bins=15, label='ノートを取った回数', color='green')
plt.ylabel('人数')
plt.legend()
plt.show()

課題提出回数とノートを取った回数
df['課題提出回数'].hist(alpha=0.6, bins=15, label='課題提出回数', color='orange')
df['ノートを取った回数'].hist(alpha=0.4, bins=15, label='ノートを取った回数', color='green')
plt.ylabel('人数')
plt.legend()
plt.show()

成績をつける
60点未満が「不可」、60~69点が「可」、70~79点が「良」、80~89点が「優」、90点以上「秀」に分ける
df.loc[(df['テスト点数'] >= 90), '成績'] = '秀'
df.loc[(df['テスト点数'] < 90) & (df['テスト点数'] >= 80), '成績'] = '優'
df.loc[(df['テスト点数'] < 80) & (df['テスト点数'] >= 70), '成績'] = '良'
df.loc[(df['テスト点数'] < 70) & (df['テスト点数'] >= 60), '成績'] = '可'
df.loc[(df['テスト点数'] < 60), '成績'] = '不可'
df
成績で円グラフを作成
value_counts = df['成績'].value_counts()
plt.figure(figsize=(8,8))
plt.pie(value_counts, labels=value_counts.index, autopct='%1.1f%%', startangle=90)
plt.title('成績割合')
plt.show()

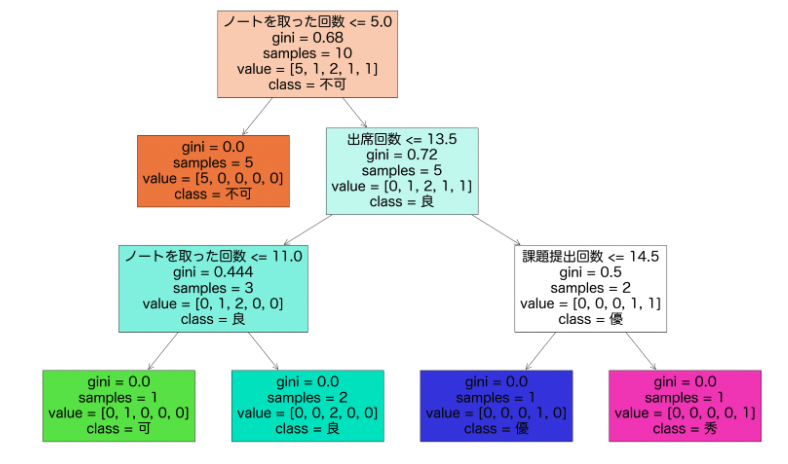
決定木モデルでの可視化
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier()
df['成績'] = df['成績'].replace('不可',0).replace('可',1).replace('良',2).replace('優',3).replace('秀',4)
X = df[['出席回数', '課題提出回数', 'ノートを取った回数']]
y = df['成績']
tree.fit(X,y)
import sklearn.tree
plt.figure(figsize=(40, 25))
sklearn.tree.plot_tree(tree, feature_names=X.columns,
class_names=['不可', '可', '良', '優', '秀'], filled=True)