今回のデータ解析を通して、楽しく学んでいきましょう
ライブラリ&データの読み込み
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
from statsmodels.tsa.stattools import adufuller
from statsmodels.tsa.seasonal import seasonal_decompose
plt.rcParams['font.family'] = 'Hiragino Maru Gothic Pro'
#df = pd.read_csv('AirPassengers.csv', index_col='Month', parse_dates=True)
df = pd.read_csv('AirPassengers.csv')
df.set_index('Month', inplace=True)
df.head()
datetime型にして曜日取得
df.index = pd.to_datetime(df.index)
df['weekday'] = df.index.strftime('%A')
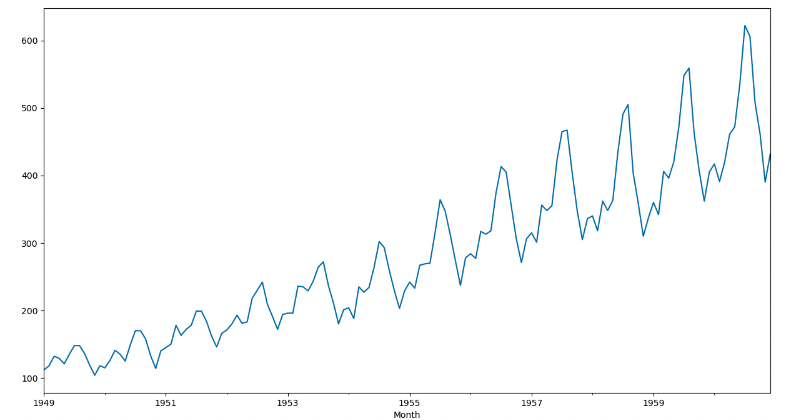
時系列データを可視化
plt.figure(figsize=(15,8))
df['#Passengers'].plot()
定常性とは
時系列データの特性である平均、分散、自己相関がどこの時間でも一定であることを言います。
・平均がどこの時間でも一定:
時間とともに平均が変化しないことであり、ある時点の平均が違う時点の平均と一緒であること。
・分散がどこの時間でも一定:
分散(データのばらつき)がどこでも、一緒または変化しないことであり、ある時点の分散が時点の平均と一緒であること。
・自己相関がどこの時点でも一定:
2つの時点を比較しても、時間の影響が受けないこと。
→時系列データがどの時間でも変化しない
定常性を確認方法とアプローチ
・確認方法
ADF検定を用いることで定常性について確認することが可能。
「帰無仮説」: 単位根過程(非定常{過程})である
「対立仮説」: 定常性{過程}である
・アプローチ
トレンド非定常性の定常化
差分取得:データの時点間での差分を取ることで、トレンドを除去する
季節性非定常性の定常化
季節差分:季節の影響が受けている場合、季節性の除去する
例)冬になるとコタツを買う人が増えるなど
分散非定常性の定常化
データの分散が増加または減少をしているときに、Box-Cox変換や対数変換をすることによって分散を一定にする
ADF検定で定常性の確認
dftest = adfuller(df['#Passengers'])
print('p-value:', dftest[1])
#出力 p-value: 0.9918802434376409
p値が0.05以下なら定常性より、非定常性である。
よって上記に記載したアプローチを使って、定常性にしていく。
対数変換した後に、トレンド非定常の定常化&季節性非定常性の定常化
1期前と12期前(季節階差 1)のデータの差分をした時系列データをプロット
dflog = pd.DataFrame(np.log(df['#Passengers']))
dflog_diff1_12 = pd.DataFrame(dflog['#Passengers'].diff(1).diff(12).dropna())
dflog_diff1_12.plot()
dftest = adfuller(dflog_diff1_12['#Passengers'])
print('p-value:', dftest[1])
#出力 p-value: 0.0002485912311384022
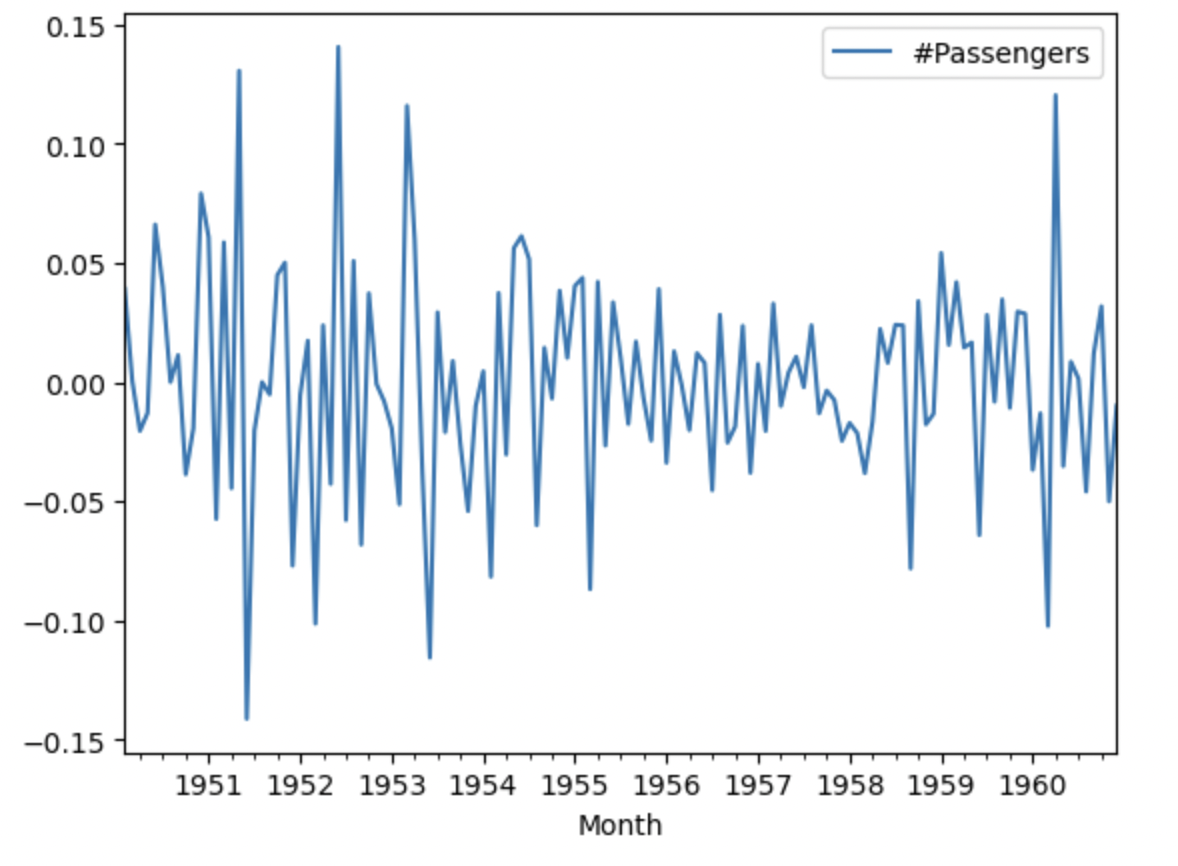
p-valueが0.05以下より定常性が確認できた。
自己相関とコレログラム
自己相関
現在と過去を比較し相関関係を表したもの。
df['#Passengers_shift1'] = df['#Passengers'].shift()
df['#Passengers_shift12'] = df['#Passengers'].shift(12)
df['#Passengers_shift8'] = df['#Passengers'].shift(8)
df[['#Passengers','#Passengers_shift1', '#Passengers_shift12']].plot()
df[['#Passengers','#Passengers_shift8']].plot()
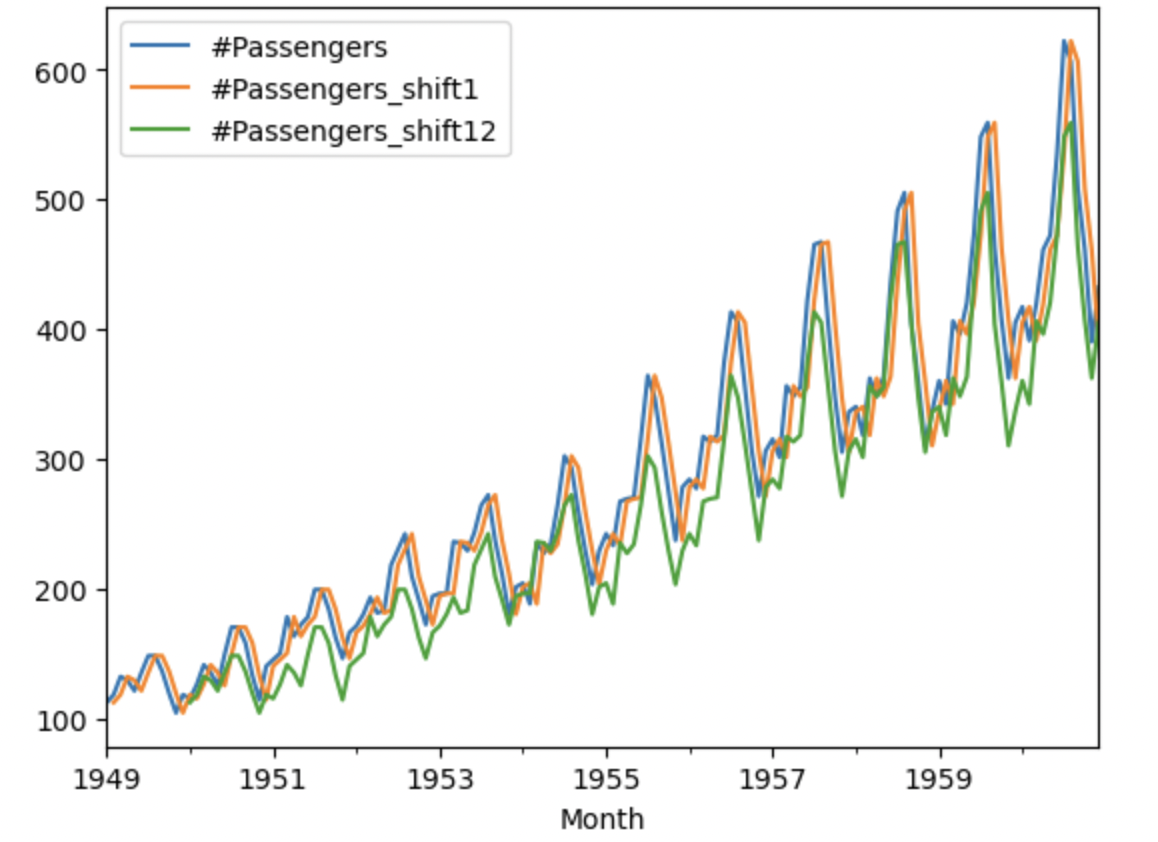
原系列(#Passengers)と似ていることがわかる。
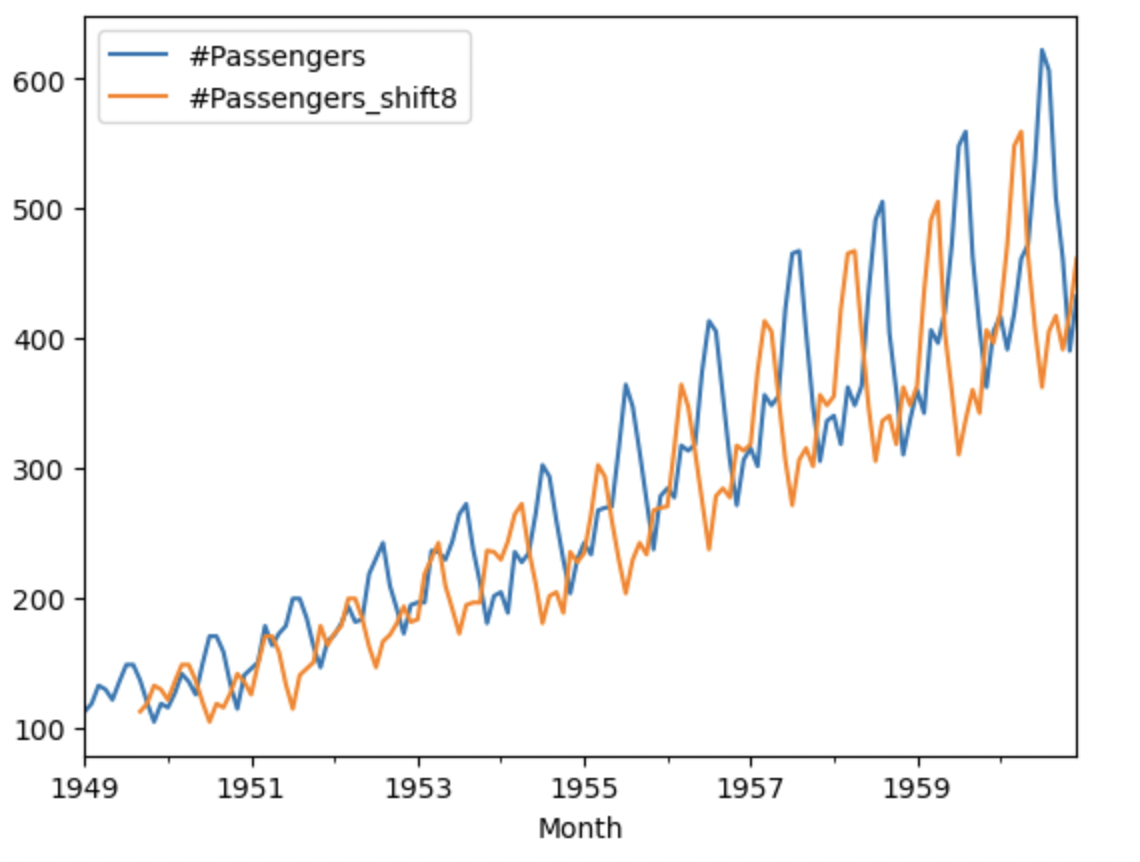
原系列と噛み合っていないことがわかる。
コレログラム
自己相関を順に並べてグラフにしたもの。
ラグと自己相関をグラフに表したもの。
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(df['#Passengers'], lags=24)
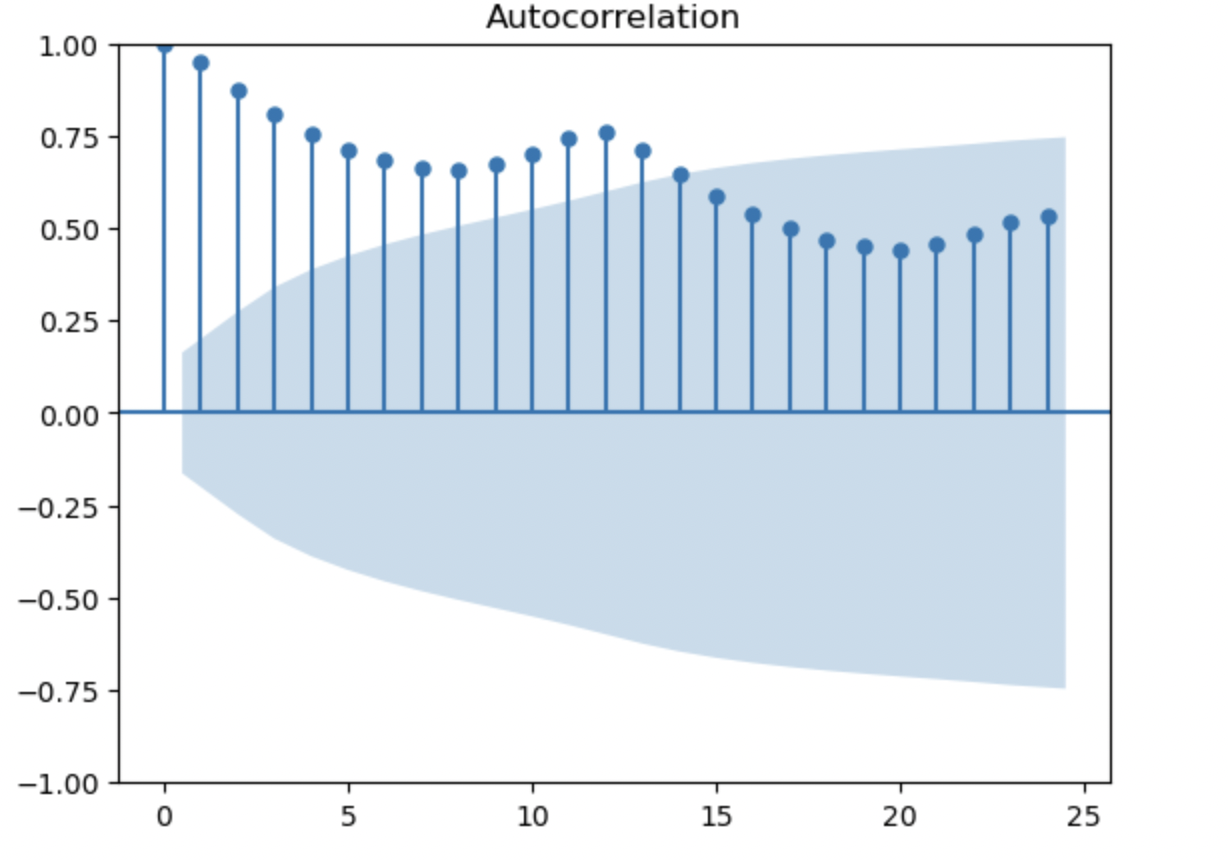
1期前と12期前(季節階差 1)の相関が高いと言える。
8期前の相関が低いと言える。
予測モデルの作成
改めてデータの読み込み
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import xgboost as xgb
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
plt.rcParams['font.family'] = 'Hiragino Maru Gothic Pro'
df = pd.read_csv('AirPassengers.csv')
df.set_index('Month', inplace=True)
特徴量作成(ラグ特徴量、ローリング特徴量)&データの欠損値を削除
for i in [1,2,3,12]:
df['shift'+str(i)] = df['#Passengers'].shift(i)
for i in [3,12]:
df['rolling'+str(i)] = df['#Passengers'].rolling(i).mean()
df = df.dropna()
df.head(3)
訓練データとテストデータに分ける
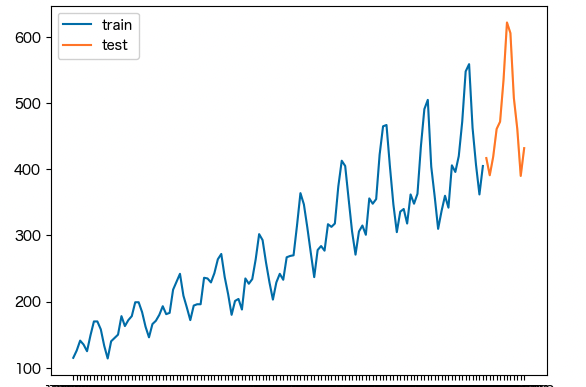
train = df.iloc[:-12]
X_train = train.iloc[:,1:]
y_train = train.iloc[:,0]
test = df.iloc[-12:]
X_test = test.iloc[:,1:]
y_test = test.iloc[:,0]
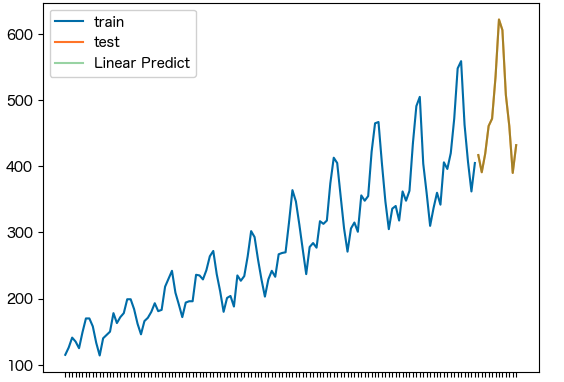
今回はtestのオレンジ色のところを予測する
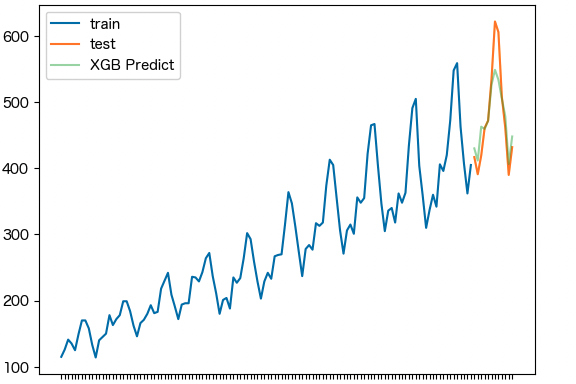
XGBモデル
xgb_model = xgb.XGBRegressor()
xgb_model.fit(X_train, y_train)
y_pred = xgb_model.predict(X_test)
print('RMSE:', np.sqrt(mean_squared_error(y_pred, y_test)))
print('MAE:', np.sqrt(mean_absolute_error(y_pred, y_test)))
fig, ax = plt.subplots()
ax.plot(y_train.index, y_train.values, label='train')
ax.plot(y_test.index, y_test.values, label='test')
ax.plot(y_test.index, y_pred, label='XGB Predict', alpha=0.4)
plt.legend()
plt.show()
# RMSE: 34.17281943476206、MAE: 4.886581357980655から良いモデルといえない。
重回帰モデル
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
y_pred = lr_model.predict(X_test)
print('RMSE:', np.sqrt(mean_squared_error(y_pred, y_test)))
print('MAE:', mean_absolute_error(y_pred, y_test))
fig, ax = plt.subplots()
ax.plot(y_train.index, y_train.values, label='train')
ax.plot(y_test.index, y_test.values, label='test')
ax.plot(y_test.index, y_pred, label='Linear Predict', alpha=0.4)
plt.legend()
plt.show()
# RMSE: 1.3826706435155173e-13,MAE: 9.947598300641403e-14からほぼ0より良いモデルといえる。