ディップ Advent Calenderの20日目です。
はじめに
はじめまして!
今年からディップにてPMっぽいこともしつつRPAや社内用ツールを作り業務改善を行っている@kahkinです。
今回アドベントカレンダーという制度を利用して、初めてQiitaに投稿させていただきました!
何を投稿しようか・・・と迷いに迷って、
現在社内用ツールとして名寄せ(っぽい)ツールを作っているので名寄せする中で検証したことについて
投稿させていただきます。
名寄せについて
名寄せの手段はいろいろあるかと思いますが、
今回はpythonのdifflib.SequenceMatcherを用いて類似率を計算、
一定の閾値を超えたら同じ情報として該当テーブルに書き込むというような処理にしました。
【概略アルゴリズム】
1. 対象のレコードを抽出する。
2. 比較先のレコードを抽出する
3. 「名前」、「住所項目」、「郵便番号」の類似率を計算する。
4. それぞれの類似率が閾値よりも値が高ければ紐づける
ところが・・・
名寄せの対象となる複数の顧客データベースについて、
住所に関連するデータの格納のされ方が2通りに分かれていました・・・。
「パターン1 まとめて「住所」のみ」
・住所:東京都港区六本木3-2-1 六本木グランドタワー31F
「パターン2 細分化されて格納」
・都道府県:東京都
・市区町村:港区
・町名番地:六本木3-2-1 六本木グランドタワー31F
当然、類似率を計算するにはどちらかに寄せなければいけないのですが・・・。
- できる限り閾値は高く設定したい。(精度を重視するため)
- 分割して各情報毎に類似率出したほうが正しい情報に紐づけやすいのでは?
- 結合したほうが住所全体の類似率見れるから閾値を上げやすいのでは?
- 漢数字とか住所の表記による違いがあったときどっちのほうがいいのだろう?
といろいろ思うことがあったので住所を分割したときと結合したときでの類似率の違いを検証してみました。
住所類似率の検証 結合vs分割
今回の検証用データは「結合」と「分割」によくありそうな表記の揺らぎを下記の3種類用意しました。
➀. 半角英数字、町名・番地は「-」で表記
➁. 全角英数字、町名・番地は漢字で表記
➂. 全角漢数字、町名・番地は漢字で表記
# 結合データ
str1 = "東京都港区六本木3-2-1 六本木グランドタワー31F"
str2 = "東京都港区六本木3丁目2番地の1 六本木グランドタワー31階"
str3 = "東京都港区六本木三丁目二番地の一 六本木グランドタワー31階"
# 分解データ
list1 = ["東京都","六本木","3-2-1 六本木グランドタワー31F"]
list2 = ["東京都","六本木","3丁目2番地の1 六本木グランドタワー31階"]
list3 = ["東京都","六本木","三丁目二番地の一 六本木グランドタワー31階"]
それぞれのデータの類似率を計算します。
各データの半角文字/全角文字は「unicodedata.normalize('NFKC',str1)」で正規化した上で計算しています。
(ざっくりなソースですが・・・)
# 分割側の計算結果格納用
result_list1 = []
result_list2 = []
result_list3 = []
# 結合側データ類似率計算
result1 = str(round(difflib.SequenceMatcher(None,unicodedata.normalize('NFKC',str1),unicodedata.normalize('NFKC',str2)).ratio(),4)*100)
result2 = str(round(difflib.SequenceMatcher(None,unicodedata.normalize('NFKC',str1),unicodedata.normalize('NFKC',str3)).ratio(),4)*100)
result3 = str(round(difflib.SequenceMatcher(None,unicodedata.normalize('NFKC',str2),unicodedata.normalize('NFKC',str3)).ratio(),4)*100)
# 分割側データ類似率計算
result_list1.append(str(round(difflib.SequenceMatcher(None,unicodedata.normalize('NFKC',list1[0]),unicodedata.normalize('NFKC',list2[0])).ratio(),4)*100))
result_list1.append(str(round(difflib.SequenceMatcher(None,unicodedata.normalize('NFKC',list1[1]),unicodedata.normalize('NFKC',list2[1])).ratio(),4)*100))
result_list1.append(str(round(difflib.SequenceMatcher(None,unicodedata.normalize('NFKC',list1[2]),unicodedata.normalize('NFKC',list2[2])).ratio(),4)*100))
result_list2.append(str(round(difflib.SequenceMatcher(None,unicodedata.normalize('NFKC',list1[0]),unicodedata.normalize('NFKC',list3[0])).ratio(),4)*100))
result_list2.append(str(round(difflib.SequenceMatcher(None,unicodedata.normalize('NFKC',list1[1]),unicodedata.normalize('NFKC',list3[1])).ratio(),4)*100))
result_list2.append(str(round(difflib.SequenceMatcher(None,unicodedata.normalize('NFKC',list1[2]),unicodedata.normalize('NFKC',list3[2])).ratio(),4)*100))
result_list3.append(str(round(difflib.SequenceMatcher(None,unicodedata.normalize('NFKC',list2[0]),unicodedata.normalize('NFKC',list3[0])).ratio(),4)*100))
result_list3.append(str(round(difflib.SequenceMatcher(None,unicodedata.normalize('NFKC',list2[1]),unicodedata.normalize('NFKC',list3[1])).ratio(),4)*100))
result_list3.append(str(round(difflib.SequenceMatcher(None,unicodedata.normalize('NFKC',list2[2]),unicodedata.normalize('NFKC',list3[2])).ratio(),4)*100))
# 結果発表
print("str1:str2="+result1)
print("str1:str3="+result2)
print("str2:str3="+result3)
print("list1:list2={0}",result_list1)
print("list1:list3={0}",result_list2)
print("list2:list3={0}",result_list3)
さて、その結果は・・・・
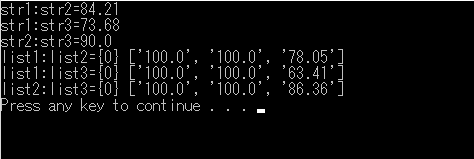
分割データだと揺らぎが発生するのは表記に差がある「町名・番地」部分のみですね・・・。
今回のデータはすべて同一住所を指しているのですが、
それぞれの最低類似率は
結合時:「73.86%」
分割時:「63.41%(町名・番地)」
今回の検証結果からどうしようかと考えましたが・・・
- 誤認を防ぐため類似率を高く設定したい。
- データ量が多いのでできる限り計算回数を減らしたい。
- 今回作るツールは10万以上のレコード×9つのDBの総当たりになるので・・・。
- 住所を「分割」するよりも「結合」するほうがアルゴリズム的には楽。
- 分割するには住所辞書必要ですし・・・。
という諸々の理由から住所を結合して処理をするで決定しました!
(あくまで今回の社内用ツールではですが。)
まだまだ検討の余地はある
今回は諸般の事情で住所を結合して処理することにしましたが、
分割して処理をすることにも当然メリットはありそうです。
私が思いつく限りでは・・・。
- 揺らぎの正規化がしやすそう
- 統一的な情報になる住所辞書はありそうですね。
- データの補正がしやすそう
- 郵便番号がないデータとか、住所が書けているデータとか・・・。
正確性の担保やデータを統一していきたい(クレンジングしたい)のであれば、
はじめから分割した状態でデータ格納しておいたほうが後々処理しやすそうですね。
あとがき
今回は自分で作成していることもあり名寄せについて検証したことを記載しましたが、
まだまだ現状課題があふれている(処理時間の短縮とか・・・・)ので検証系やらなにやら投稿していきたいと思います。
誤った情報やおかしな表記・ご助言等ありましたら、是非コメントください!
最後まで読んでいただきありがとうございました!