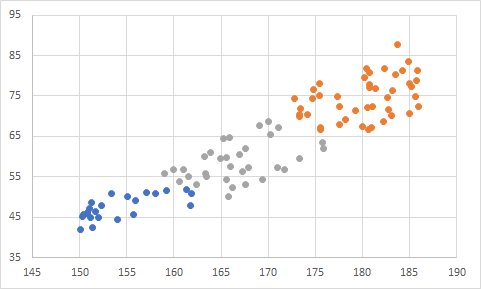
身長(x)と体重(y)のデータに対して体格ごとにpythonを用いてクラスタリングを行った。
今回はコードを簡単にするため、クラスを用いず、必要な処理を関数にまとめた。
main関数の流れ
1. read_data関数でファイルを読み込む。
2. データ数やクラスタ数を決める。
3. 重心の位置の初期化(最初はすべてx, yともに0としておく)
4. clustering関数でクラスタを行う。クラスタしたデータと各クラスタの重心が返される。
5. 分類結果をファイルに書き込む。
6. 結果を表示
尚、実際のコードではmain関数は一番下に書いた。
# main関数
def main():
# 2次元データ読み込み
filename = "height_weight.csv"
data = read_data(filename)
# データ数
N = len(data)
# クラスタ数
number = 3
# 重心
# すべて0に初期化しておく
# [(グループ番号), (xの重心), (yの重心)]
u = [[1, 0.0, 0.0],[2, 0.0, 0.0], [3, 0.0, 0.0]]
# クラスタリング
cluster, u = clustering(data, u, number, N)
# 2次元データ書き込み
filename2 = "cluster.csv"
write_data(filename2, cluster)
# 結果表示
print("Clustering")
for sample in cluster:
print(sample)
# 重心表示
print("Center")
for sample in u:
print(sample)
if __name__ == "__main__":
main()
まずはファイルの読み取り。読み込んだデータはなぜかfloat型に変換するという作業が必要らしい。これをしないとエラーが出た。ここの原因や理屈はよく分からない。
# coding:utf-8
import csv
import random
# 2次元データ読み込み
def read_data(filename):
data = []
with open(filename, "r") as f:
reader = csv.reader(f)
for row in reader:
data.append(row)
data = [[float(data[i][j]) for j in range(0, len(row))] for i in range(0, len(data))]
return data
クラスタリング(グループ分け)したデータをファイルの書き込む。読み込み・書き込み共に、C/C++と比較して大分簡単である。
# ファイル書き込み
def write_data(filename, cluster):
with open(filename, "w") as f:
writer = csv.writer(f)
writer.writerows(cluster)
print("File was written .")
メインの処理工程となるクラスタリング関数。最初は各データをランダムにグループ分けする。言い換えれば、ランダムにグループ番号を割り振る。
次に、各グループの重心をcenter関数で求め、その重心から再度belong関数によりグループ分けを行う。これを一定回数繰り返し、正確なグループ分けと各グループの重心を求める。
# クラスタリングの関数
def clustering(data, u, number, N):
# クラスタしたデータを格納する配列の初期化
cluster = []
for m in range(0, N):
# 初期はランダムにクラスタリング
# [(グループ番号), (データ番号), (xデータ), (yデータ)]
cluster.append([random.randrange(1, number+1),m+1, data[m][0], data[m][1]])
# 1回目のランダムなクラスタリング結果を表示
print("First cluster nuclear")
for sample in cluster:
print(sample)
print("\nStart Clustering")
# クラスタリング開始
for count in range(0, 10000):
# 重心計算
u = center(u, number, N, cluster)
# グループ分け
cluster = belong(u, number, N, cluster)
# クラスタリング後にクラスタ番号(グループ番号)ごとに並べる
cluster.sort()
print("Finish clustering .")
# クラスタリング結果返す
return cluster, u
重心を計算する関数
# 重心計算
def center(u, number, N, cluster):
# 各グループごとの重心を計算
for n in range(0, number):
x_center = 0.0
y_center = 0.0
sample_count = 0
for m in range(0, N):
if cluster[m][0] == n + 1:
x_center = x_center + cluster[m][2]
y_center = y_center + cluster[m][3]
sample_count = sample_count + 1
if sample_count != 0:
x_center = x_center / sample_count
y_center = y_center / sample_count
u[n][0] = n + 1
u[n][1] = x_center
u[n][2] = y_center
return u
グループ分けを行う関数。各データから一番近い重心のグループに割り振る。
# グループ分け
def belong(u, number, N, cluster):
# サンプル点がどの重心に一番近いかを計算
# つまりどのグループに所属(belong)しているか
for m in range(0, N):
d_min = (cluster[m][2] - u[0][1])**2 + (cluster[m][3] - u[0][2])**2
temp_number = 1
for n in range(1, number):
d = (cluster[m][2] - u[n][1])**2 + (cluster[m][3] - u[n][2])**2
# 最小値更新
# これによりグループが決まる
if d < d_min:
d_min = d
temp_number = n + 1
cluster[m][0] = temp_number
return cluster
クラスタリングした結果。しっかりと分類できている。