はじめに
この記事は社内技術勉強会用に作成したものです。
Twitter APIにより取得したツイートを表すJSONデータをElasticsearchに登録し、SQLで集計したり、Kibanaでグラフを表示したりしてみます。
使用するツイートデータは、自前のREST APIによるクローラで集めた、約14万件を使用します。ばらばらの時間帯、キーワードで2回にわけてクロールした内容を合成したものになっているので、集計結果は分析できるものではありません。
Elasticsearchについて
Elasticsearchについてはこちらのスライドがわかりやすかったので、ご参照ください。
実行環境構築
実行環境はDockerイメージを使用します。
現在リリースされている最新のバージョンは7.9.1ですが、Sudachiプラグインが対応しているバージョンが7.8.1なので、7.8.1を使用します。
また、Elasticsearch SQLを使用したいので、Elastic License ベーシックの機能が使えるイメージを使用します。
- elasticsearch-sudachi:7.8.1
- docker.elastic.co/kibana/kibana:7.8.1
参考:
設定ファイルの準備
前述のDockerイメージを使用する、docker-compose.ymlを用意します。また、Bulk API用の設定を行うため、elasticsearch.ymlも用意しておきます。
elasticsearch.ymlは、サービスを起動するまえに作成しておく必要があります。内容を修正して反映させるには、一度Dockerコンテナを停止、削除し、コンテナを再起動する必要があります。
それぞれのファイルは後述していますので、そちらをご参照ください。
起動
docker-compose up elasticsearch kibana
起動したら、別のコンソールを開いて、elasticsearchコンテナに接続します。
docker-compose exec elasticsearch
Kibanaは、Webブラウザから以下のURLにアクセスします。
http://localhost:5601
停止
停止する時は以下のコマンドを実行します。
docker-compose down
バージョンの確認
elasticsearchコンテナ内で実行します。
curl http://localhost:9200
{
"name" : "972b5e27b52e",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "CSFkD4cJTGmH0JA7hpAYRQ",
"version" : {
"number" : "7.8.1",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "b5ca9c58fb664ca8bf9e4057fc229b3396bf3a89",
"build_date" : "2020-07-21T16:40:44.668009Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
version.numberで7.8.1であると確認できます。
インデックスの作成
ツイートデータを保存するインデックスを作成します。
curl -X PUT -H "Content-Type: application/json" http://localhost:9200/tweets -d '
{
"settings": {
"analysis": {
"tokenizer": {
"sudachi_tokenizer": {
"type": "sudachi_tokenizer",
"resources_path": "/usr/share/elasticsearch/config/sudachi",
"discard_punctuation": false
}
},
"analyzer": {
"sudachi_analyzer": {
"filter": [ "my_posfilter", "my_stopfilter" ],
"tokenizer": "sudachi_tokenizer",
"type": "custom"
}
},
"filter":{
"my_posfilter":{
"type":"sudachi_part_of_speech",
"stoptags":[
"助詞",
"助動詞",
"補助記号,句点",
"補助記号,読点"
]
},
"my_stopfilter":{
"type":"sudachi_ja_stop",
"stopwords":[
"_japanese_",
"は",
"です"
]
}
}
},
"index":{
"mapping":{
"total_fields":{
"limit":"2000"
}
}
}
},
"mappings":{
"properties":{
"created_at":{
"type":"date",
"format":"EEE MMM dd HH:mm:ss Z yyyy"
}
}
}
}'
sudachiプラグインについての設定は、以下のページと書籍を参考に作成しました。
index.mapping.total_fields.limitの値は、デフォルト値は1000です。しかし、ツイートのJSONデータを取り込むと、フィールドの数が1000を超えており、取り込みに失敗することがあります。そこで、取り込みが成功するように、上限値を緩和しています。
mappings.properties.created_atは、ツイートのJSONデータのフィールド、created_atの書式を指定し、date型として取り込むように指定しています。
参考: Elasticsearch - Defining the mapping of Twitter Data
Bulk APIによるツイートデータの取り込み
Bulk APIによるデータ登録用のファイルを作成します。
{"index": {"_index": "tweets"}}
{"contributors":null,"coordinates":null,"created_at":"Sat Sep 12 05:30:44 +0000 2020","display_text_range":[0,135],"entities":{"hashtags":[{"indices":[20,29],"text":"MUSICDAY"}, ...(省略)
{"index": {"_index": "tweets"}}
{"contributors":null,"coordinates":null,"created_at":"Sat Sep 12 05:30:44 +0000 2020","display_text_range":[0,140],"entities":{"hashtags":[{"indices":[111,120],"text":"MUSICDAY"}, ...(省略)
参考: Bulk API
ファイルサイズが大きすぎると登録に失敗するので、ファイルを分割して登録します。後述「Bulk API用の設定」を参照してください。
split -l 30550 ../tweets_bulk.json
curl -H "Content-Type: application/x-ndjson" -X POST --data-binary @xaa http://localhost:9200/_bulk
curl -H "Content-Type: application/x-ndjson" -X POST --data-binary @xab http://localhost:9200/_bulk
curl -H "Content-Type: application/x-ndjson" -X POST --data-binary @xac http://localhost:9200/_bulk
curl -H "Content-Type: application/x-ndjson" -X POST --data-binary @xad http://localhost:9200/_bulk
SQLの実行
登録件数の確認
ツイートのJSONデータをすべて登録できたら、まずは登録された件数を確認してみます。
curl -H "Content-Type: application/json" -X POST http://localhost:9200/_sql?format=txt -d "
{
\"query\":\"SELECT COUNT(id) FROM tweets\"
}"
COUNT(id)
---------------
142119
キーワード検索
full_textフィールドに対してキーワード検索を実行してみます。match()関数を使用します。
curl -H "Content-Type: application/json" -X POST http://localhost:9200/_sql?format=txt -d "
{
\"query\":\"SELECT score(),full_text FROM tweets WHERE match(full_text, '音楽の日') AND retweeted_status.id_str IS NULL ORDER BY score() DESC LIMIT 10\"
}"
score() | full_text
---------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------
9.813963 |@musicday_ntv FNSや音楽の日は全部出してくれたのに・・・😢
9.1681 |今日14:55からテレビ朝日でTHE MUSICDAYあるみたいですよ
音楽番組大好きなので楽しみです😃
9.122601 |影ちゃん『本日は!MUSIC DAYです!🎵私にとって日向坂メンバーとして初めての音楽番組出演です。』影ちゃん日向坂メンバーとして初めての音楽番組出演!頑張れ〜楽しみ!!
# 影山優佳 #日向坂46 #MUSICDAY
https://t.co/Q5SWXW6tiu https://t.co/e4I802a3gB
9.0436735 |音楽 · トレンド
MUSICDAY
トレンドトピック: THE MUSIC DAY
132,975件のツイート
9.000752 |MUSICDAYリアタイで見れないけど
ほんとに楽しみ💕
2日連続でセブチ日本の音楽番組で見れるなんて…😭
8.976725 |音楽を楽しむ翔くんの姿も見れる#MUSICDAY 💕
((o(´∀`)o))ワクワク
8.872035 |【TV】 本日9/12(土)14:55~22:54 日本テレビにて生放送の音楽特番「THE MUSIC DAY」に、LiSAが出演します!8時間の音楽特番!
是非番組をチェックしてください!
おたのしみに!
https://t.co/kVIEvwP9iQ
# LiSA
# MUSICDAY
8.752537 |なんでさ。jo1がmusicdayに出れへんの?闇深すぎるやろ、日本の音楽界(笑)(笑)
8.649813 |@musicday_ntv
音楽番組見ます
8.4992485 |明日放送「#THEMUSICDAY」#ジャニーズシャッフルメドレー 組み合わせ発表(音楽ナタリー)
# Yahooニュース
https://t.co/celIDqpVAI
検索を実行し、スコア値を確認することができました。
集計:1時間ごとのツイート数
SQLで集計してみます。1時間ごとのツイート数を集計します。公式リツイートも含む件数とします。
curl -H "Content-Type: application/json" -X POST http://localhost:9200/_sql?format=txt -d "
{
\"query\":\"SELECT DATETIME_FORMAT(created_at, 'YYYY-MM-dd HH:00') AS created_at, COUNT(id) FROM tweets GROUP BY 1 ORDER BY 1\"
}"
created_at | COUNT(id)
----------------+---------------
2020-09-11 12:00|37177
2020-09-11 13:00|12604
2020-09-11 14:00|5380
2020-09-11 15:00|2613
2020-09-11 16:00|1130
2020-09-11 17:00|493
2020-09-11 18:00|400
2020-09-11 19:00|230
2020-09-11 20:00|354
2020-09-11 21:00|503
2020-09-11 22:00|896
2020-09-11 23:00|707
2020-09-12 00:00|5155
2020-09-12 01:00|12031
2020-09-12 02:00|7883
2020-09-12 03:00|11640
2020-09-12 04:00|14485
2020-09-12 05:00|13622
2020-09-12 06:00|764
2020-09-12 07:00|388
2020-09-12 08:00|765
2020-09-12 09:00|832
2020-09-12 10:00|9898
2020-09-12 11:00|2169
集計:ユーザごとのツイート数
各ユーザが何件ツイートしているかを出力します。今度は公式リツイートを除きます。
curl -H "Content-Type: application/json" -X POST http://localhost:9200/_sql?format=txt -d "
{
\"query\":\"SELECT user.id_str,COUNT(id_str) FROM tweets WHERE retweeted_status.id_str IS NULL AND user.id_str <> '1356026714' GROUP BY 1 ORDER BY 2 DESC LIMIT 20\"
}"
user.id_str | COUNT(id_str)
-------------------+---------------
990603579449733120 |36
978420825178058752 |25
1291365191544795136|20
995466703717859328 |20
2232105834 |19
1212214643252330498|18
1267643229119213568|18
1304340074268557312|18
1035866692981731328|17
1285575649931825153|17
395649936 |17
2496439194 |16
787898207913193472 |16
1226403588835950592|15
1232463581221797888|15
1492379906 |15
1170368498494623745|14
1236601573049905153|14
1246575354463924224|14
3241292509 |14
集計:ツイート数ごとのユーザ数(1回目)
集計結果を逆転させて、ツイート数ごとのユーザ数を出力します。前項のSQLを副問い合わせにします。
curl -H "Content-Type: application/json" -X POST http://localhost:9200/_sql?format=txt -d "
{
\"query\":\"SELECT t1.tweet_count,COUNT(t1.user.id_str) FROM (SELECT user.id_str,COUNT(id_str) AS tweet_count FROM tweets WHERE retweeted_status.id_str IS NULL AND user.id_str <> '1356026714' GROUP BY 1) AS t1 GROUP BY 1 ORDER BY 2 DESC LIMIT 20\"
}"
{
"error": {
"root_cause": [
{
"type": "sql_illegal_argument_exception",
"reason": "Cannot GROUP BY t1.tweet_count{r}#3862"
}
],
"type": "sql_illegal_argument_exception",
"reason": "Cannot GROUP BY t1.tweet_count{r}#3862"
},
"status": 500
}
エラーが発生しました。GROUP BYを含む副問い合わせはサポートされていないことが原因です。
この集計は、インデックスの変換後にもう一度挑戦します。
Kibana
インデックスパターンの設定
Kibanaで、前述のSQLと同様の集計結果をグラフで表示させてみます。
まずは、インデックスパターンの設定を行います。

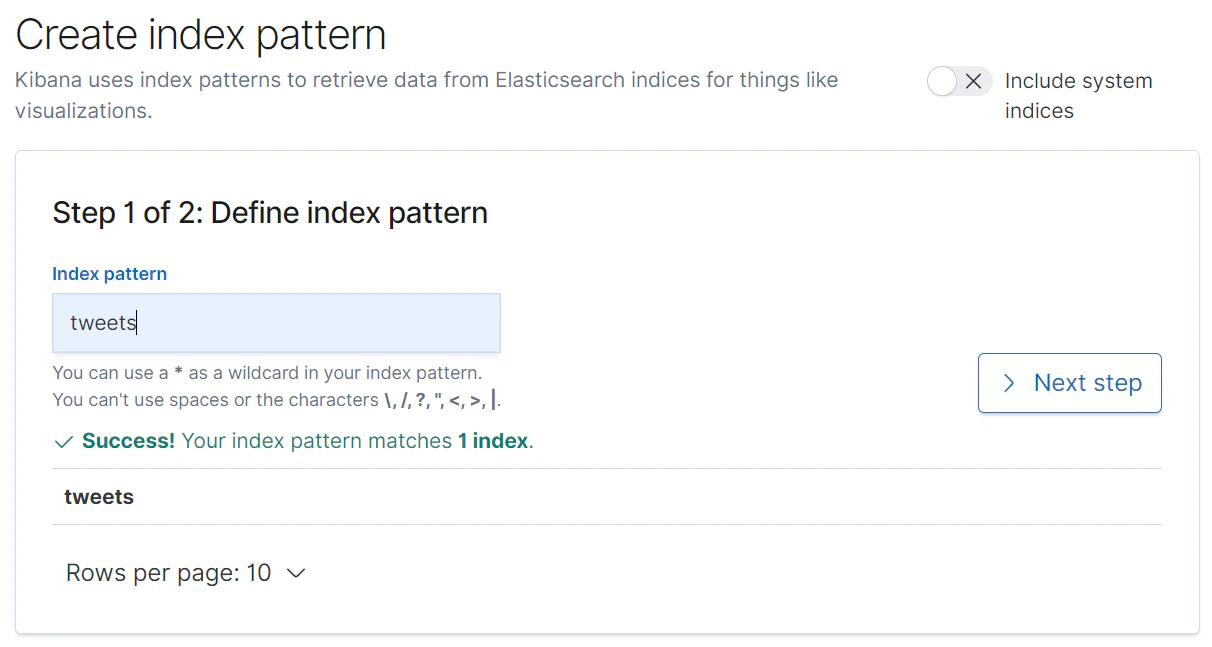


created_atフィールドのAggregatableに「○」が付いていることを確認します。型を指定することによって、集計ができるようになります。
また、インデックスパターンを登録したら、画面右上の「Refresh field list.」ボタンをクリックし、再読み込みさせておきます。
参考: Kibana5, index pattern does not contain any of the following field types: *
インデックスの変換を行う
ツイート数ごとのユーザ数を集計するSQLでは、GROUP BYを含む副問い合わせが実行できませんでした。
1回のSQLでは実行できなかったので、あらかじめユーザごとのツイート数を集計した結果を保存したインデックスを作成しておき、そこからツイート数ごとのユーザ数を集計してみることにします。
transformの定義を作成します。


{
"bool": {
"must_not": {
"exists": {
"field": "retweeted_status.id_str"
}
}
}
}



「Create and start」ボタンをクリックし、transformの作成と実行を行います。
変換で作成したインデックスによる集計
集計:ツイート数ごとのユーザ数(2回目)
transformにより作成したインデックス tweet_quantities を使用して、SQLでツイート数ごとのユーザ数を集計してみます。
curl -H "Content-Type: application/json" -X POST http://localhost:9200/_sql?format=txt -d "
{
\"query\":\"SELECT id_str.keyword.value_count, COUNT(user.id_str.keyword) FROM tweet_quantities WHERE user.id_str.keyword <> '1356026714' GROUP BY 1 ORDER BY 2, 1 DESC LIMIT 20\"
}"
id_str.keyword.value_count|COUNT(user.id_str.keyword)
--------------------------+--------------------------
36 |1
25 |1
19 |1
20 |2
16 |2
18 |3
17 |3
15 |3
14 |5
13 |7
11 |7
12 |9
10 |22
9 |22
8 |32
7 |55
6 |74
5 |134
4 |206
3 |450
集計が実行できました。
Kibanaでグラフの作成
グラフ:1時間ごとのツイート数
KinabaのVisualizeにより、グラフを作成してみます。まずは1時間ごとのツイート数です。
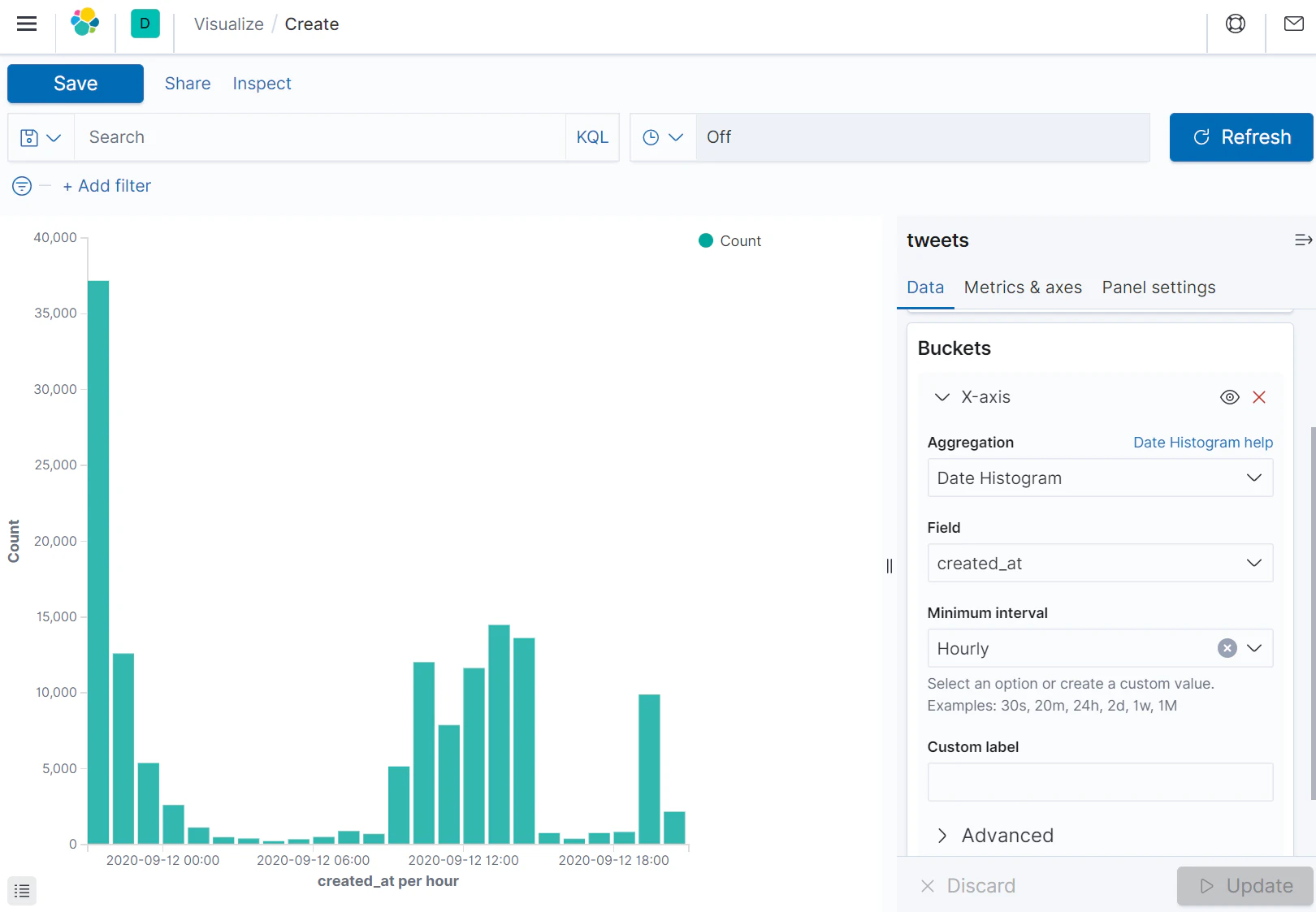
「Date Histgram」によって作成することができました。
ここで、グラフの集計対象から公式リツイートを除きたい場合は、フィルターを指定します。

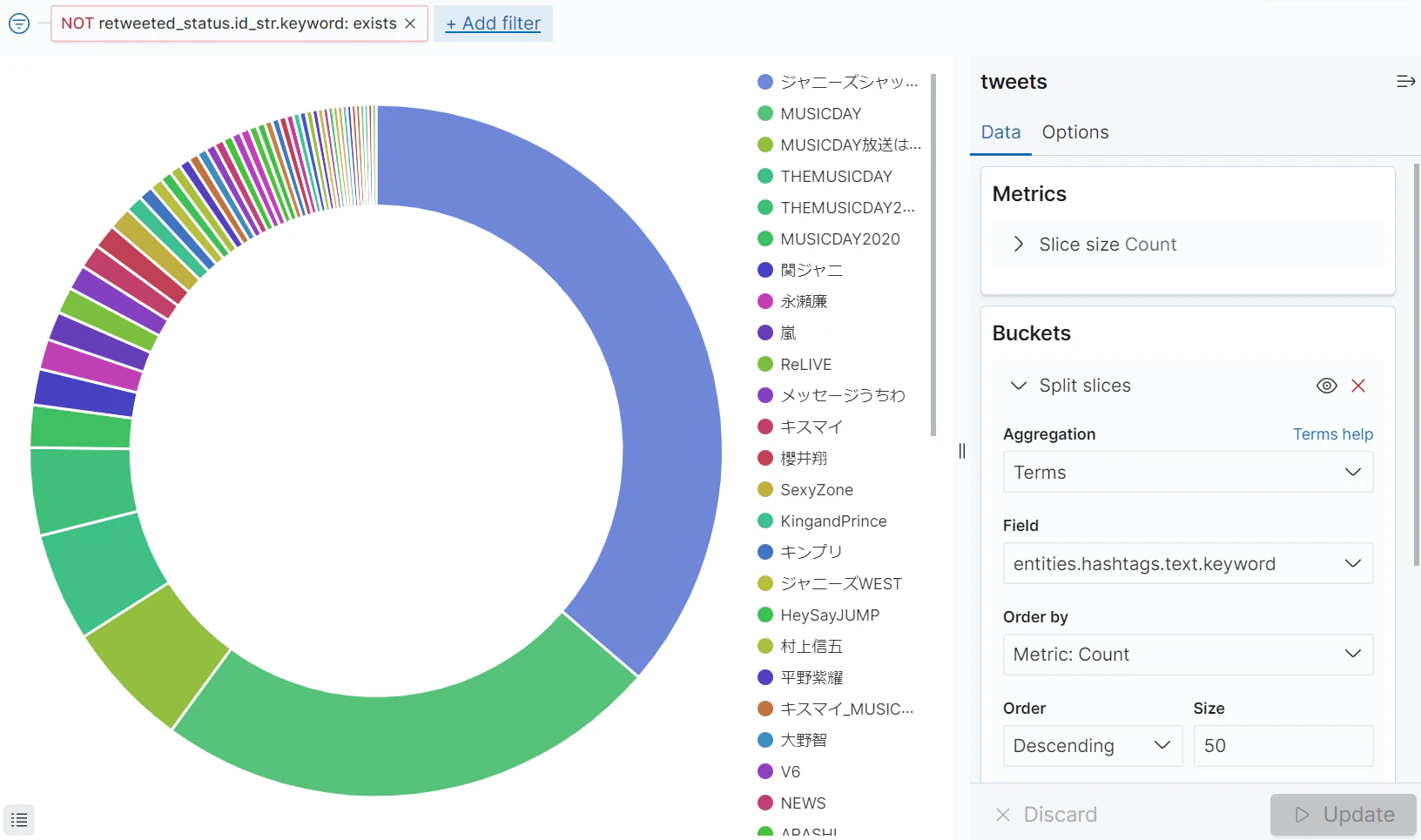
タグクラウド:ハッシュタグ
ツイートのJSONデータ内のフィールド、entities.hashtagsを使用して、ハッシュタグのタグクラウドを作成してみます。

前項と同様に、公式リツイートを対象から除きたい場合は、フィルターを追加します。
グラフ:ハッシュタグ投稿数の割合
前述のタグクラウドと同じ条件で、円グラフを作成してみます。
ツイート数ごとのユーザ数
インデックス tweet_quantities を使用して、ツイート数ごとのユーザ数の棒グラフを作成してみます。

ダッシュボード
Visualizeで作成したグラフなどを配置して、ダッシュボードを作成します。グラフを一覧表示できました。

設定
Elasticsearch Dockerファイル
ElasticsearchのDockerイメージにsudachiプラグインを追加したDockerfileを作成します。
FROM docker.elastic.co/elasticsearch/elasticsearch:7.8.1
COPY analysis-sudachi-7.8.1-2.0.3.zip /usr/share/elasticsearch
RUN bin/elasticsearch-plugin install file:///usr/share/elasticsearch/analysis-sudachi-7.8.1-2.0.3.zip && \
rm analysis-sudachi-7.8.1-2.0.3.zip
RUN curl -o sudachi-dictionary-20200722-core.zip https://object-storage.tyo2.conoha.io/v1/nc_2520839e1f9641b08211a5c85243124a/sudachi/sudachi-dictionary-20200722-core.zip && \
mkdir -p config/sudachi && \
unzip sudachi-dictionary-20200722-core.zip && \
mv sudachi-dictionary-20200722/system_core.dic config/sudachi/ && \
rm -Rf sudachi-dictionary-20200722 && \
rm sudachi-dictionary-20200722-core.zip
docker-compose
version: '3.7'
services:
elasticsearch:
image: elasticsearch-sudachi:7.8.1
build:
context: .
dockerfile: Dockerfile-es
volumes:
- .:/local
- ./elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
ports:
- 9200:9200
- 9300:9300
environment:
- discovery.type=single-node
kibana:
image: docker.elastic.co/kibana/kibana:7.8.1
volumes:
- .:/local
ports:
- 5601:5601
elasticsearch.yml
cluster.name: "docker-cluster"
network.host: 0.0.0.0
http.max_content_length: 2147483647b
Bulk API用の設定
Bulk APIによるデータ登録用のファイルを作成し、登録を実行します。ファイルのサイズは368MBでした。
curl -i -H "Content-Type: application/x-ndjson" -X POST --data-binary @tweets_bulk.json http://localhost:9200/_bulk
HTTP/1.1 413 Request Entity Too Large
content-length: 0
413 Request Entity Too Largeのエラーになりました。どのくらいのサイズなら登録できるのでしょうか。
参考:
- Why Elastic search bulk operation failing for large size of data
- Set up Elasticsearch » Configuring Elasticsearch » HTTP
指定できるファイルサイズの上限はhttp.max_content_lengthの設定によるもので、デフォルトは100MBのようです。大きなサイズ、例えば2GBを指定してみます。
http.max_content_length: 2048MB
Elasticsearchのサービスを起動しようとすると、起動中のログに以下のエラーが出力されました。
elasticsearch_1 | {"type": "server", "timestamp": "2020-09-20T06:44:08,023Z", "level": "ERROR", "component": "o.e.b.ElasticsearchUncaughtExceptionHandler", "cluster.name": "docker-cluster", "node.name": "b8efd4ec3542", "message": "uncaught exception in thread [main]",
elasticsearch_1 | "stacktrace": ["org.elasticsearch.bootstrap.StartupException: java.lang.IllegalArgumentException: failed to parse value [2048MB] for setting [http.max_content_length], must be <= [2147483647b]",
2147483647bまで指定できるようです。2147483647 / 1024 / 1024 = 2047.9999990463257 ということで、2048MB以上ではダメということでした。
http.max_content_length: 2147483647b
ではもう一度。
curl -i -H "Content-Type: application/x-ndjson" -X POST --data-binary @tweets_bulk.json http://localhost:9200/_bulk
HTTP/1.1 100 Continue
HTTP/1.1 429 Too Many Requests
content-type: application/json; charset=UTF-8
content-length: 885
{"error":{"root_cause":[{"type":"circuit_breaking_exception","reason":"[parent] Data too large, data for [<http_request>] would be [1265194912/1.1gb], which is larger than the limit of [1020054732/972.7mb], real usage: [495440896/472.4mb], new bytes reserved: [769754016/734mb], usages [request=0/0b, fielddata=0/0b, in_flight_requests=769754016/734mb, accounting=0/0b]","bytes_wanted":1265194912,"bytes_limit":1020054732,"durability":"TRANSIENT"}],"type":"circuit_breaking_exception","reason":"[parent] Data too large, data for [<http_request>] would be [1265194912/1.1gb], which is larger than the limit of [1020054732/972.7mb], real usage: [495440896/472.4mb], new bytes reserved: [769754016/734mb], usages [request=0/0b, fielddata=0/0b, in_flight_requests=769754016/734mb, accounting=0/0b]","bytes_wanted":1265194912,"bytes_limit":1020054732,"durability":"TRANSIENT"},"status":429}
今度はData too largeのエラーになりました。
参考:
- “[circuit_breaking_exception] [parent]” Data too large, data for “[]” would be error
- After Upgrade to 6.2.4 Circuitbreaker Exception Data too large
- CircuitBreakingException: [parent] Data too large IN ES 7.x
理解はできていないのですが、JVMの設定により制限されている、ということでしょうか。
the limit of [1020054732/972.7mb]の制限がどこからきているのかわかっていませんが、この状態で、登録するファイルのサイズを変えながら繰り返し実行してみたところ、サーバ起動直後で286MBのファイルまで登録できました。ただし続けて別のファイルで登録処理を実行すると、もっと小さなサイズでなければ成功しませんでした。
この時は、368MBのファイルを登録するために、ファイルを4分割、1つあたり90MB前後にして、Bulk APIを4回実行し、登録しました。
その他のリンク
おわりに
ElasticsearchにツイートのJSONデータを取り込み、SQLで集計したり、Kibanaでグラフを作成したりしてみました。
SQLの副問い合わせの制限に対しては、インデックスの変換を行うことにより代替できました。
全文検索がElasticsearchの特徴ですが、集計とグラフ表示だけから初めてみるのはいかがでしょうか。