はじめに
統計もデータ解析もRも勉強したことがありませんが、知らないままでは仕事の幅も広がらないので、少し勉強してみることにします。
今回はTwitterのツイートデータを集めるクローラを使用して、集めたツイートデータの集計をしてみたいと思います。
間違っているところや効率の悪い書き方をしている部分などあるかと思いますが、なにとぞご容赦を。
集計やデータ解析に用いられる言語
集計やデータ解析といえば、世の中では以下のような言語がよく使われていそうです。
- SQL
- Python
- R
試してみる言語
PythonとRを比較する記事はいろいろあるようでした。少し経験のあるPythonを使用するのもよいですが、食わず嫌いはよくないというのが自分の信条なので、Rを試してみることにします。
実行環境の準備
LinuxにRをインストールすると、bashなどのシェルで「R」というコマンドを実行すると、Rのコンソールが起動します。
これでターミナルでも実行できますが、RStudioという統合環境もあります。
RStudioはデスクトップ版とサーバ版があり、サーバ版だと、Webブラウザでサーバにアクセスして使用する形になります。
今回はサーバ版をLinuxにインストールして使用します。ついでにMeCabもインストールします。
| アプリケーションなど | バージョン |
|---|---|
| ディストリビューション | Fedora29 |
| R | 3.5.2 |
| RStudio Server | 1.1.463 |
| MeCab | 0.996 |
基本的統計量の計算
平均値や最大値、最小値などの、代表的な統計学上の値を基本統計量と呼ぶそうです。Rで計算させてみます。データは、Rに付属しているirisのデータの一部を使用します。
> petal_list <- subset(iris, Species == "setosa")$Petal.Length
> petal_list
[1] 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 1.5 1.6 1.4 1.1 1.2 1.5 1.3 1.4 1.7
[20] 1.5 1.7 1.5 1.0 1.7 1.9 1.6 1.6 1.5 1.4 1.6 1.6 1.5 1.5 1.4 1.5 1.2 1.3 1.4
[39] 1.3 1.5 1.3 1.3 1.3 1.6 1.9 1.4 1.6 1.4 1.5 1.4
> sum(petal_list)
[1] 73.1
> mean(petal_list)
[1] 1.462
> max(petal_list)
[1] 1.9
> summary(petal_list)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 1.400 1.500 1.462 1.575 1.900
ツイートデータの分析
ツイートデータを表すJSON文字列を保存したテキストファイルを読み取り、いくつか集計してみます。
- 使用するデータは、2019/02/18(月)に放送されたドラマに関するハッシュタグで、放送時間中1時間に投稿されたツイートデータを集めたものとします。
- ファイルの形式は、1行にツイート1つ分のJSON文字列が記述されているとします。
各投稿者のツイート数
ドラマの放送時間中に、ユーザが何回ツイートしているかを調べてみます。
コード
library(jsonlite)
# ファイルの読み取り
tweet_json_list <- readLines("./tweet_json_list.txt")
tweet_user_list <- c()
for (tweet_json in tweet_json_list) {
# 1行ごとにJSONを分解して、ツイートしたユーザのスクリーン名を取り出しリストに追加する
escaped_json <- gsub("\\\\\"([^,])", "\\\"\\1", tweet_json)
tweet <- fromJSON(escaped_json)
tweet_user_list <- append(tweet_user_list, tweet$user$screen_name)
}
# 何件のツイートデータがあったか
length(tweet_user_list)
# 何人のユーザがツイートしたか
user_tbl <- table(tweet_user_list)
length(user_tbl)
# 1人が投稿した最大のツイート件数
max(user_tbl)
# 10回よりも多くツイートしたユーザの一覧を出力
over_10_list <- rev(sort(user_tbl[sapply(user_tbl, function(it) { it >= 10 })]))
over_10_list
# ヒストグラムを作成
histgram = hist(user_tbl)
histgram$breaks
histgram$counts
実行結果
ヒストグラムは以下のようになりました。1,542人がツイートしており、1,347人は5回未満のツイートですが、一方で、44回ツイートした人もいるようです。
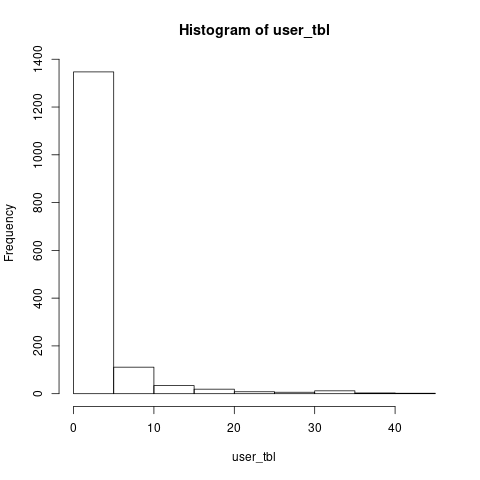
> length(user_tbl)
[1] 1542
> max(user_tbl)
[1] 44
> histgram$breaks
[1] 0 5 10 15 20 25 30 35 40 45
> histgram$counts
[1] 1347 111 34 19 8 6 12 3 2
プロフィール文に使用されている単語
放送時間中にツイートしたユーザの、プロフィールに使用されている単語の種類と件数を集計してみます。
- 集計対象の単語は名詞、動詞、形容詞、副詞のみとします。
- 1文字の名詞の単語は、絵文字や記号が多かったので、今回は集計対象から除外しています。
コード
library(jsonlite)
library(RMeCab)
target_part_of_speech_list <- c("名詞", "動詞", "形容詞", "副詞")
tweet_json_list <- readLines("./tweet_json_list.txt")
user_list <- c()
word_list <- c()
for (tweet_json in tweet_json_list) {
escaped_json <- gsub("\\\\\"([^,])", "\\\"\\1", tweet_json)
tweet <- fromJSON(escaped_json)
# まだプロフィールの文章を解析していないユーザだけ処理を行う
if (is.null(user_list) || is.na(user_list[tweet$user$screen_name])) {
# プロフィールの文章を取り出す
profile_txt <- c(tweet$user$description)
if (!is.null(profile_txt) && nchar(profile_txt) > 0) {
# 形態素解析を実行
profile_line_txt <- gsub("\\\\n", " ", profile_txt)
morpheme_list <- RMeCabC(profile_line_txt, dic = "./mecab-ipadic-neologd.csv.dic")
for (morpheme in morpheme_list) {
part_of_speech <- names(morpheme)
word <- morpheme[[1]]
# 対象の品詞だけリストに追加
if (is.element(part_of_speech, target_part_of_speech_list) && nchar(word) > 1) {
word_list <- append(word_list, word)
}
}
# プロフィールの解析を行ったユーザを記録する
names(profile_txt) <- c(tweet$user$screen_name)
user_list <- c(user_list, profile_txt)
}
}
}
# プロフィールを登録しているユーザが何人いたか
length(user_list)
# 単語がいくつあるか
length(word_list)
# 単語ごとに登場する回数を集計
word_tbl <- table(word_list)
length(word_tbl)
# 30回以上登場した単語の一覧を出力
over_30_list <- rev(sort(word_tbl[sapply(word_tbl, function(it) { it >= 30 })]))
over_30_list
実行結果
プロフィールの文章を登録しているユーザは1,467人、単語の合計数は21,146、単語の種類の数は8,245でした。30回以上登場する単語は以下のようになりました。
> length(user_list)
[1] 1467
> length(word_list)
[1] 21146
> length(word_tbl)
[1] 8245
> over_30_list
word_list
好き さん 関ジャニ∞ 大好き くん フォロー
437 314 281 252 238 223
eighter ドラマ 無言 ちゃん こと AAA
201 132 122 113 107 99
推し 応援 ください 映画 てる 実況
81 79 63 62 60 58
参戦 錦戸亮 音楽 する フォロバ アニメ
58 56 53 53 51 51
もの あり Nissy line 失礼 なり
50 50 48 48 44 44
呟き ジャニーズ エイト 大人 気軽 ファン
42 41 41 40 40 40
ツイート いる アカウント 仲良く 20 漫画
40 39 39 38 36 35
渋谷すばる !! 自由 世代 基本 やっ
35 35 34 33 33 33
テレビ 亮ちゃん 高橋優 ない 最近 ゲーム
33 32 32 32 31 31
いい https http:// )/ :// つぶやき
31 31 31 31 31 30
フォロー数とツイート数の相間
フォロー数が多い人は活発に活動していてツイート数も多いのでは、という仮説を立てて、検証してみます。検証のために、フォロー数とツイート数の散布図を作成します。ここでいうツイート数とは、放送時間1時間中のツイート数です。
コード
library(jsonlite)
library(RMeCab)
tweet_json_list <- readLines("./tweet_json_list.txt")
screen_name_list <- c()
follow_count_list <- c()
follower_count_list <- c()
for (tweet_json in tweet_json_list) {
escaped_json <- gsub("\\\\\"([^,])", "\\\"\\1", tweet_json)
tweet <- fromJSON(escaped_json)
# スクリーン名、フォロー数、フォロワー数を取り出してリストで記憶
screen_name_list <- append(screen_name_list, tweet$user$screen_name)
follow_count_list <- append(follow_count_list, tweet$user$friends_count)
follower_count_list <- append(follower_count_list, tweet$user$followers_count)
}
# 何件のツイートがあったか
length(screen_name_list)
# ユーザ別のツイート数を表すデータフレームを作成
tweet_data <- data.frame(table(screen_name_list))
colnames(tweet_data) <- c("screen_name", "tweet_count")
# ユーザ別のフォロー数とフォロワー数を表すデータフレームを作成
raw_data <- data.frame(screen_name = screen_name_list, follow_count = follow_count_list, follower_count = follower_count_list)
agg_data <- aggregate(x = raw_data[c("follow_count", "follower_count")], by = list(raw_data$screen_name), FUN = max)
colnames(agg_data) <- c("screen_name", "follow_count", "follower_count")
# スクリーン名でデータフレームをマージ
summary_data <- merge(agg_data, tweet_data)
# フォロー数が1000以上のユーザは図の作成から除外
subset_data <- subset(summary_data, follow_count < 1000)
# 散布図を作成
plot(subset_data$follow_count, subset_data$tweet_count)
フォロワー数も取り出していますが、参考までに取り出してみただけのもので、散布図の作成には使用していません。
実行結果
以下のような結果になりました。さすがに1時間という短い期間では、相間関係はなさそうです。
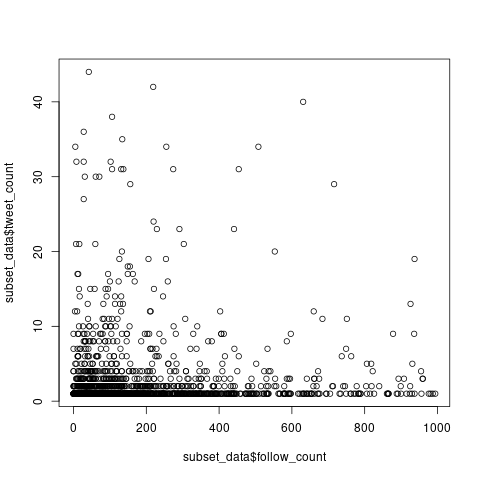
おわりに
分析結果はさておき、テキストから単語を切り出したり、散布図を作成したりすることができました。
普段の開発ではRubyを使うことが多いのですが、集計処理だけならRでできるようになると、作業の効率が上がるかもしれません。精進してみます。