Introduction
Python は業務中に嫌というほど触っており、個人では業務の延長線上で確認作業をすることが主でした。
仕事とプライベートを分けるために、記事にするのは意図的に避けていました。
ただ折角の GW なので、連休中は Python に関する記事も投稿します。
ソースコードはGitHubにもあげております。
https://github.com/kagami-tsukimura/create-movie
今回の内容に限っては非常に簡易的なライブラリを用いているため、初心者の方でもお試ししやすいと思います。
必要なのはPython環境と 3 行だけです!
本記事が少しでも読者様の学びに繋がれば幸いです!
「いいね」をしていただけると今後の励みになるので、是非お願いします!
環境
Ubuntu22.04
Python3.11.1
icrawler0.6.6
概要
クローリングは、主にデータセットを作成する際に用いることが多いです。
機械学習においては実装よりもデータの準備や前処理、モデル管理等が遥かに大変な作業になります。
最終的にスライドショーを作るだけなのでKaggle等から取得しても良いのですが、今回は実務でも良く行っているブラウザからクロールする手法を取ります。
Kaggleデータセットは業務で流用する場合、国や地域、画質、データセットの偏り、外れ値、枚数等の問題で工数に見合った対価が得られないことが多いです。
上記問題をコントロールするためにも、クロール技術を身につけておくとデータセット取得の幅が広がります。
クローリングとは(スクレイピングとの違い)
-
クローリング: 「Web 上を徘徊して情報を取得すること」 -
スクレイピング: 「Web 上の情報を抽出すること(Webスクレイピング)」
ざっくりですが、クローリング+データ加工=スクレイピングです。
混同されている方をよく見かけるので、両方の定義を覚えて認識の齟齬対策をしましょう。
icrawler とは
icrawlerは簡易的な Web クローラーです。
機械学習における画像集めで私は良くお世話になっています。
特徴としてはScrapyの軽量版の立ち位置で、最短 3 行でお手軽クローリングが可能です。
ライブラリはpipとcondaでインストールできます。
pip install icrawler
conda install -c hellock icrawler
お試し版の 3 行スクリプトです。
from icrawler.builtin import GoogleImageCrawler
google_crawler = GoogleImageCrawler(storage={'root_dir': './Penguin'})
google_crawler.crawl(keyword='Penguin', max_num=10)
'root_dir'の value に画像保存先のディレクトリ
keywordに検索ワード
max_numにクロール枚数を指定すればお好みの画像がクローリングできます。
実行結果を見るとPenguinディレクトリに、指定通り可愛らしいペンギンさんの画像が 10 枚取得できています!
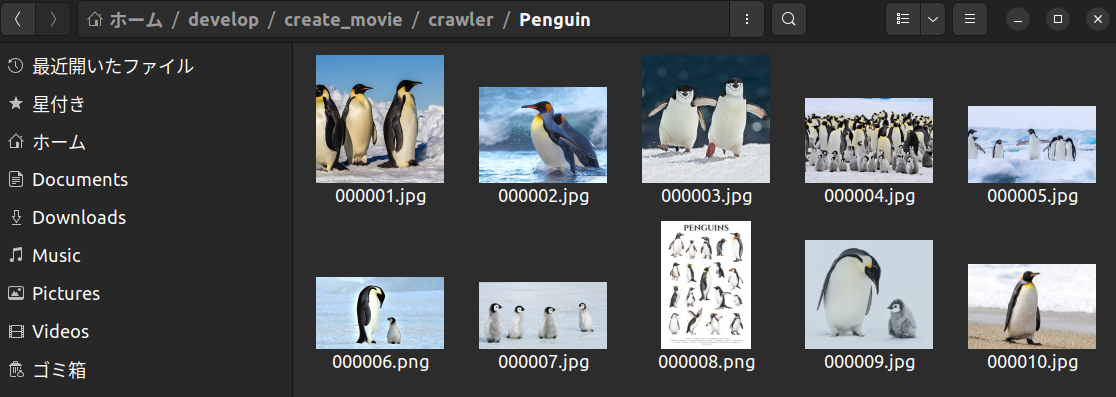
以前Googleでは parser 変更でクロールできませんでしたが、記事化にあたり試したところクロールできるように改善されていました。
デフォルトの検索エンジンはGoogleでBingにも対応できるように実装します。
前準備
- 重複画像の排除。
上記は画像ファイル名を URL にして重複画像はスキップしてしまえば(基本的に)重複しなくなります。
ただ長過ぎるファイル名は書き込みエラーが発生します。
解決にはicrawlerのfilesystem.pyを以下のように修正します。
# -*- coding: utf-8 -*-
import os
import os.path as osp
import six
from icrawler.storage import BaseStorage
class FileSystem(BaseStorage):
"""Use filesystem as storage backend.
The id is filename and data is stored as text files or binary files.
"""
def __init__(self, root_dir):
self.root_dir = root_dir
def write(self, id, data):
filepath = osp.join(self.root_dir, id)
folder = osp.dirname(filepath)
if not osp.isdir(folder):
try:
os.makedirs(folder)
except OSError:
pass
mode = 'w' if isinstance(data, six.string_types) else 'wb'
# with open(filepath, mode) as fout:
# fout.write(data)
try:
with open(filepath, mode) as fout:
fout.write(data)
except FileNotFoundError:
pass
def exists(self, id):
return osp.exists(osp.join(self.root_dir, id))
def max_file_idx(self):
max_idx = 0
for filename in os.listdir(self.root_dir):
try:
idx = int(osp.splitext(filename)[0])
except ValueError:
continue
if idx > max_idx:
max_idx = idx
return max_idx
修正したのはこの範囲です。
# with open(filepath, mode) as fout:
# fout.write(data)
try:
with open(filepath, mode) as fout:
fout.write(data)
except FileNotFoundError:
pass
ちなみにfilesystem.pyの格納先は以下になります。
※私はpipで管理しています。
/home/<ユーザー名>/.local/lib/python3.11/site-packages/icrawler/storage
実装
詳細は GitHub からどうぞ。
https://github.com/kagami-tsukimura/create_movie
ソースコードは GitHub にありますが、こちらにも公開します。
import os
import argparse
import base64
from enum import Enum
from six.moves.urllib.parse import urlparse
from icrawler import ImageDownloader
from icrawler.builtin import BingImageCrawler
from icrawler.builtin import GoogleImageCrawler
class SearchEngine(Enum):
BING = "bing"
GOOGLE = "google"
def setting_args():
"""Parse command line arguments for the image crawler.
Returns:
Namespace: Containing parsed arguments.
"""
parser = argparse.ArgumentParser(description="crawling images")
parser.add_argument("-o", "--output", default="./images", type=str)
parser.add_argument("-n", "--N", default=10, type=int)
parser.add_argument("-e", "--engine", default="google", type=str)
return parser.parse_args()
class Base64NameDownloader(ImageDownloader):
def get_filename(self, task, default_ext):
"""Base64 encodes the URL path and generates a file name.
Args:
task (dict): A dictionary with a "file_url" key.
default_ext (str): A default extension to use.
Returns:
str: The generated filename.
"""
url_path = urlparse(task["file_url"])[2]
# If the image contains an extension, get it.
if "." in url_path:
extension = url_path.split(".")[-1]
if extension.lower() not in [
"jpg",
"jpeg",
"png",
]:
extension = default_ext
else:
extension = default_ext
# Encoding the URL to the file name.
filename = base64.b64encode(url_path.encode()).decode()
return f"{filename}.{extension}"
def get_crawler(args, dir_name):
"""Returns a crawler object based on the search engine in the arguments.
Args:
args (argparse.Namespace): Containing parsed arguments.
dir_name (str): The output directory for downloaded images.
Returns:
A crawler object for the selected search engine.
"""
if args.engine == SearchEngine.BING.value:
crawler = BingImageCrawler(
downloader_cls=Base64NameDownloader, storage={"root_dir": dir_name}
)
elif args.engine == SearchEngine.GOOGLE.value:
crawler = GoogleImageCrawler(storage={"root_dir": dir_name})
return crawler
def main(args):
"""Main processing.
Args:
args (argparse.Namespace): Containing parsed arguments.
"""
SEARCH_FILE = "./configs/search.txt"
print("Start crawling images...")
with open(SEARCH_FILE, encoding="utf_8") as f:
read_data = list(f)
# If there is no output directory, create it.
os.makedirs(args.output, exist_ok=True)
for i in range(len(read_data)):
# Setting the directory name to save.
dir_name = os.path.join(args.output, read_data[i].replace("\n", ""))
crawler = get_crawler(args, dir_name)
crawler.crawl(keyword=read_data[i], max_num=args.N)
print("Finish crawling images!")
if __name__ == "__main__":
args = setting_args()
main(args)
検索ワードは./configs/search.txtに改行区切りで記述します。
ペンギン
橋
空 背景
引数
-
-o: 出力ディレクトリ- デフォルト:
./images
- デフォルト:
-
-n: 出力枚数- デフォルト:
10(最大1000)
- デフォルト:
-
-e: 検索エンジン - デフォルト:
google
実行
python3 crawling.py -n 15
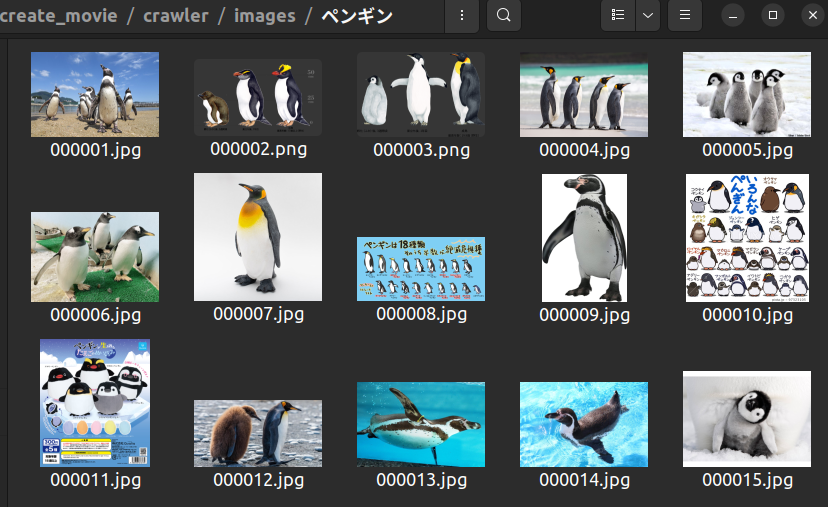
./imagesにsearch.txtで指定した画像がクロールされていることが確認できます。
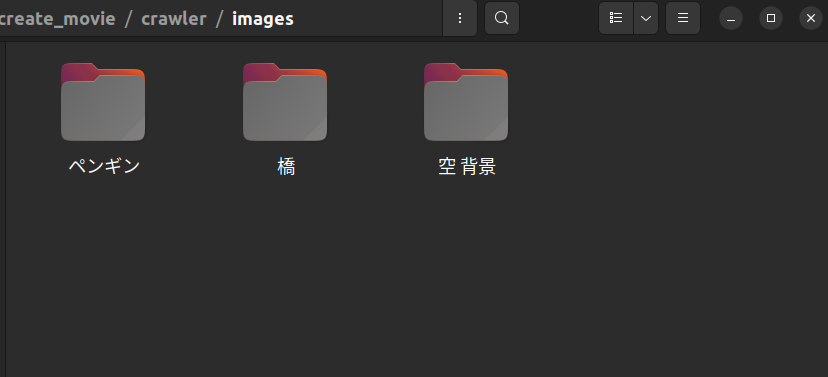
ペンギンさん可愛いです......
最後に
閲覧頂きありがとうございました。
本記事がお役に立てば幸いです!
参考 URL
https://icrawler.readthedocs.io/en/latest/