はじめに
この記事では、Colaboratoryでword2vecの学習とTensorboardによる可視化を行ないます。
- TensorBoardの出力結果はインターネット上で公開されてしまうので、オープンデータのみ使用するようしてください
- (公開せずにTensorBoardのPROJECTORを実装する方法をご存知の方がいらっしゃましたら教えてください)
- word2vecとTensorboardの説明は、行わないので別途学習してください
使用データ/行うこと
word2vecの学習には、著作権が切れたためにフリーで公開されている青空文庫にある夏目漱石作の「吾輩は猫である」を使用します。
小説内の単語をword2vecで学習することで、コンピューターが正しく**「吾輩」は「猫」であると認識できるか可視化**しながら検証を行います。
(正しく認識すると、吾輩の単語ベクトルと猫の単語ベクトルが近くなる)
出力
実装
ここから、Google Colaboratoryを使用して実装を行っていきます。
[Step1] ライブラリのインストール/インポート
Colaboratory上に必要なライブラリをインストールしていきます。以下の2つを使用します。
- MeCab (+ mecab-ipadic-neologdの辞書)
-
MeCabは、フリーソフトウェアの形態素解析器で文章を単語ごとに分割してくれます。
- mecab-ipadic-neologdの辞書を使用することで、wikiediaにのっているような固有名詞も正しく認識することができます。 - (参考)新語・固有表現に強い「mecab-ipadic-NEologd」の効果を調べてみた
-
MeCabは、フリーソフトウェアの形態素解析器で文章を単語ごとに分割してくれます。
- TensorbordX
- Tensorboardを作成するためのライブラリ
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
!pip install mecab-python3 > /dev/null
# エラー回避
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
!pip install tensorboardX
%load_ext tensorboard
インストールしたライブラリと標準のライブラリをインポートします。
import re
import MeCab
import torch
from gensim.models import word2vec
from tensorboardX import SummaryWriter
from itertools import chain
[Step 2] データのダウンロード
青空文庫のサイトから、「吾輩は猫である」のzipファイルをColaboratory上でダウンロードし、解凍します。
!wget https://www.aozora.gr.jp/cards/000148/files/789_ruby_5639.zip
!unzip 789_ruby_5639.zip
すると、「wagahaiwa_nekodearu.txt」が現れますので、ファイルを読み込みます。
f = open('./wagahaiwa_nekodearu.txt', 'r', encoding='shift-jis')
texts = [t.strip() for t in f.readlines()]
f.close()
ファイルを出力してみましょう。
texts
['吾輩は猫である',
'夏目漱石',
'',
'-------------------------------------------------------',
'【テキスト中に現れる記号について】',
'',
'《》:ルビ',
'(例)吾輩《わがはい》',
'',
'|:ルビの付く文字列の始まりを特定する記号',
'(例)一番|獰悪《どうあく》',
'',
'[#]:入力者注\u3000主に外字の説明や、傍点の位置の指定',
'(数字は、JIS X 0213の面区点番号またはUnicode、底本のページと行数)',
'(例)※[#「言+墟のつくり」、第4水準2-88-74]',
'',
'〔〕:アクセント分解された欧文をかこむ',
'(例)〔Quid aliud est mulier nisi amicitiae& inimica〕',
'アクセント分解についての詳細は下記URLを参照してください',
'http://www.aozora.gr.jp/accent_separation.html',
'-------------------------------------------------------',
'',
'[#8字下げ]一[#「一」は中見出し]',
'',
'吾輩《わがはい》は猫である。名前はまだ無い。',
'どこで生れたかとんと見当《けんとう》がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。しかもあとで聞くとそれは書生という人間中で一番|獰悪《どうあく》な種族であったそうだ。この書生というのは時々我々を捕《つかま》えて煮《に》て食うという話である。しかしその当時は何という考もなかったから別段恐しいとも思わなかった。ただ彼の掌《てのひら》に載せられてスーと持ち上げられた時何だかフワフワした感じがあったばかりである。掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始《みはじめ》であろう。この時妙なものだと思った感じが今でも残っている。第一毛をもって装飾されべきはずの顔がつるつるしてまるで薬缶《やかん》だ。その後《ご》猫にもだいぶ逢《あ》ったがこんな片輪《かたわ》には一度も出会《でく》わした事がない。のみならず顔の真中があまりに突起している。そうしてその穴の中から時々ぷうぷうと煙《けむり》を吹く。どうも咽《む》せぽくて実に弱った。これが人間の飲む煙草《たばこ》というものである事はようやくこの頃知った。',
'この書生の掌の裏《うち》でしばらくはよい心持に坐っておったが、しばらくすると非常な速力で運転し始めた。書生が動くのか自分だけが動くのか分らないが無暗《むやみ》に眼が廻る。胸が悪くなる。到底《とうてい》助からないと思っていると、どさりと音がして眼から火が出た。それまでは記憶しているがあとは何の事やらいくら考え出そうとしても分らない。',
'ふと気が付いて見ると書生はいない。たくさんおった兄弟が一|疋《ぴき》も見えぬ。肝心《かんじん》の母親さえ姿を隠してしまった。その上|今《いま》までの所とは違って無暗《むやみ》に明るい。眼を明いていられぬくらいだ。はてな何でも容子《ようす》がおかしいと、のそのそ這《は》い出して見ると非常に痛い。吾輩は藁《わら》の上から急に笹原の中へ棄てられたのである。',
・・・]
出力結果をみると、以下のようなことが分かります。
- 文章の前後に小説(テキスト)の説明が記述されている
- 説明によると、小説中にルビや入力者注が記述されている
- リストの1つの要素内に複数の文章が記述されている
次のStepでこれらの前処理を行っていきます。
[Step 3] データの前処理
ここでは、文章の前処理用の関数を用意します。
def preprocessTexts(texts):
# 1. 文章の前後にある小説の説明文を削除
texts = texts[23:-17]
# 2. ルビ・区切り記号・入力者注・アクセント分解された欧文を削除
signs = re.compile(r'(《.*?》)|(|)|([#.*?])|(〔.*?〕)|(\u3000)')
texts = [signs.sub('',t) for t in texts]
# 3. 文章を「。」で分割
texts = [t.split('。') for t in texts]
texts = list(chain.from_iterable(texts))
# 一文字以下の文章を削除(文章ではないため)
texts = [t for t in texts if len(t) > 1]
return texts
texts = preprocessTexts(texts)
print('文章数:', len(texts))
文章数: 9058
前処理によって、word2vecが学習できる文章のリストになりました。
[Step 4] word2vecの学習
いよいよword2vecの学習です。学習する前に、文章を分かち書き(単語ごとに分割)する必要があります。
インストールしたMeCabを使用して、それぞれの文章を分かち書きにしましょう。
分かち書きにする関数を定義します。
def getWords(sentence, tokenizer, obj_pos=['all'], symbol=False):
"""
文章を単語に分割(分かち書きに)する
Parameters
----------
sentence : str
分かち書きする文章
tokenizer : class
MeCabのtokenizer
obj_pos : list of str, default ['all']
取得する品詞
symbol : bool, default False
記号を含むか否か
Returns
--------
words : list of str
単語毎に分割された文章
"""
node = tokenizer.parseToNode(sentence)
words = []
while node:
results = node.feature.split(",")
pos = results[0] # 品詞
word = results[6] # 単語の基本形
if pos != "BOS/EOS" and (pos in obj_pos or 'all' in obj_pos) and (pos!='記号' or symbol):
if word == '*':
word = node.surface
words.append(word)
node = node.next
return words
関数を使って、単語を分かち書きにしていきます。このとき、2パターンの分かち書き結果を準備します。
- 全品詞の分かち書き結果 ⇒ word2vecの学習に使用
- 名詞のみの分かち書き結果 ⇒ TensorBoardに使用(TensorBoardの可視化をシンプルにするため)
# Tokenizerを設定
path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"
tokenizer = MeCab.Tagger(path)
# 文章を分かち書きにする
words = [getWords(t, tokenizer, symbol=True) for t in texts]
# 名詞を取得
nouns = [getWords(t, tokenizer, obj_pos=['名詞']) for t in texts]
nouns = set(chain.from_iterable(nouns)) # 出現する名詞の集合
ここから、word2vecの学習です。パラメータを以下のように設定します。
| パラメータ | 値 | 説明 |
|---|---|---|
| size | 300 | 単語ベクトルの次元数 |
| sg | 1 | 使用するアルゴリズム (skip-gram:1, C-BOW:0) |
| min_count | 2 | 出現回数がmin_count未満の語を無視 |
| seed | 0 | 乱数のシード |
一般的に、精度が高いと言われているskip-gramを使用し、再現性を担保するためにシード値を設定しています。sizeとmin_countは経験則~~(という名の適当)~~です。その他のパラメータは、デフォルトのままにしております。
size = 300
sg = 1
min_count = 2
seed = 0
次に、モデルの学習です。可視化を分かりやすくするために、学習結果のベクトルをL2ノルムにしております。
model = word2vec.Word2Vec(words, size=size, min_count=min_count, sg=sg, seed=seed)
model.init_sims(replace=True)
これで、word2vecの学習の完了です。今回は、可視化をシンプルにするために、名詞の出現頻度上位500語に絞ります。
# 分散表現・単語のリストを取得
word_vectors = model.wv.vectors
index2word = model.wv.index2word
# 名詞のindexを取得
nouns_id = [i for i, n in enumerate(index2word) if n in nouns]
# 品詞が名詞である単語の上位500語を抽出
word_vectors = word_vectors[nouns_id][:500]
index2word = [index2word[i] for i in nouns_id][:500]
[Step 5] Tensorboardによる可視化
いよいよ学習したword2vecを、Tensorbordによって可視化します。
可視化用のファイルを出力します。ライブラリTensorbordXを使用することで、簡単に出力ができます。
writer = SummaryWriter('./runs')
writer.add_embedding(torch.FloatTensor(word_vectors), metadata=index2word)
writer.close()
出力したファイルを実行します。ngrokを使用することで、ColaboratoryでTensorboardの実行ができます。
LOG_DIR = './runs'
get_ipython().system_raw(
'tensorboard --logdir={} --host 0.0.0.0 --port 6006 &'
.format(LOG_DIR)
)
!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip
!unzip ngrok-stable-linux-amd64.zip
get_ipython().system_raw('./ngrok http 6006 &')
!curl -s http://localhost:4040/api/tunnels | python3 -c \
"import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"
上記のコードを実行すると、「 http://XXXXXXXX.ngrok.io 」のようなURLが出力されるので、アクセスするとTensorBoardが見れます!
これで完了です!
出力結果の確認
アクセスすると、以下のようになっています。しばらく待機するか、右上の「INACTIVE」を「PROJECTOR」に変更してください。
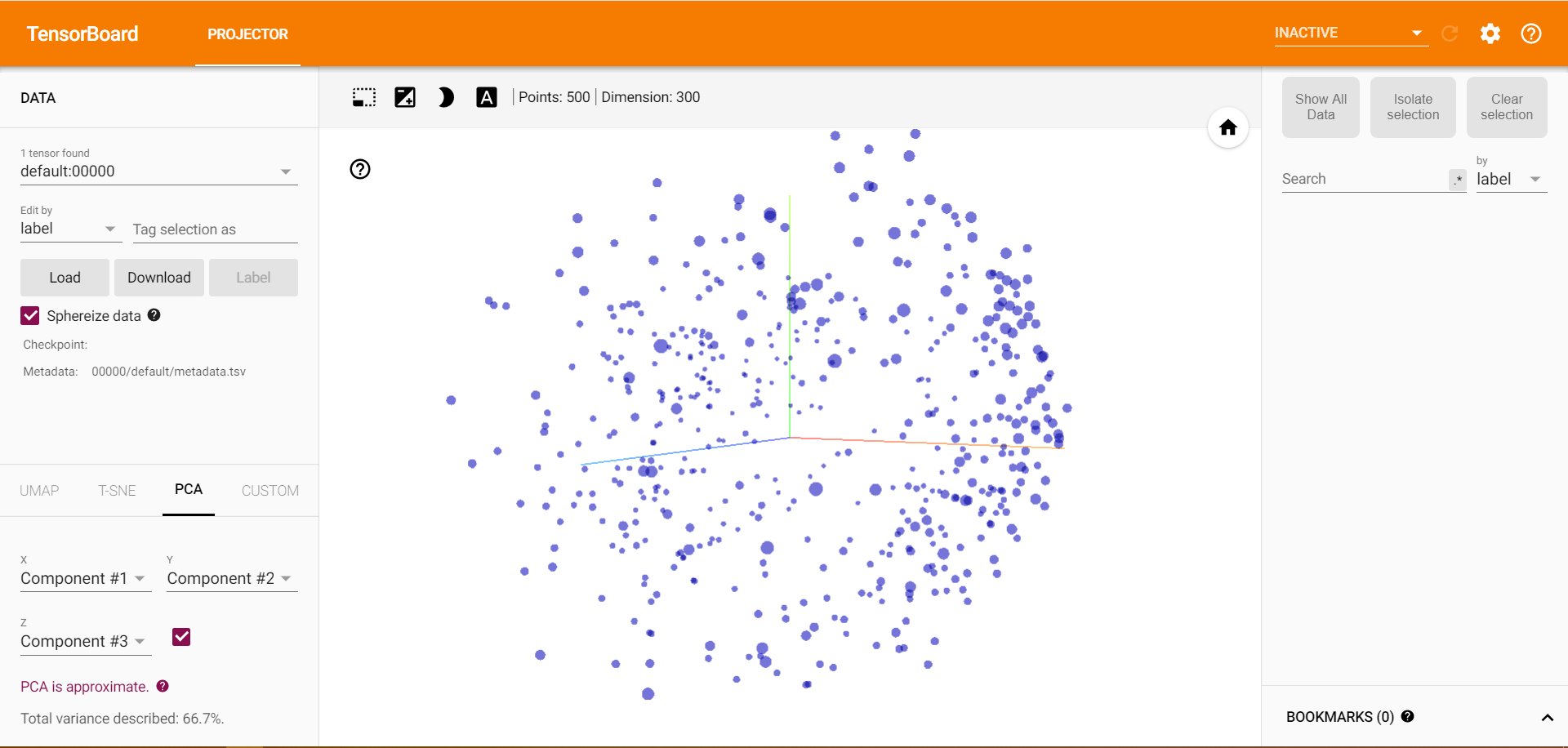
すると、PCAで3次元にまとめられた結果が現れます。
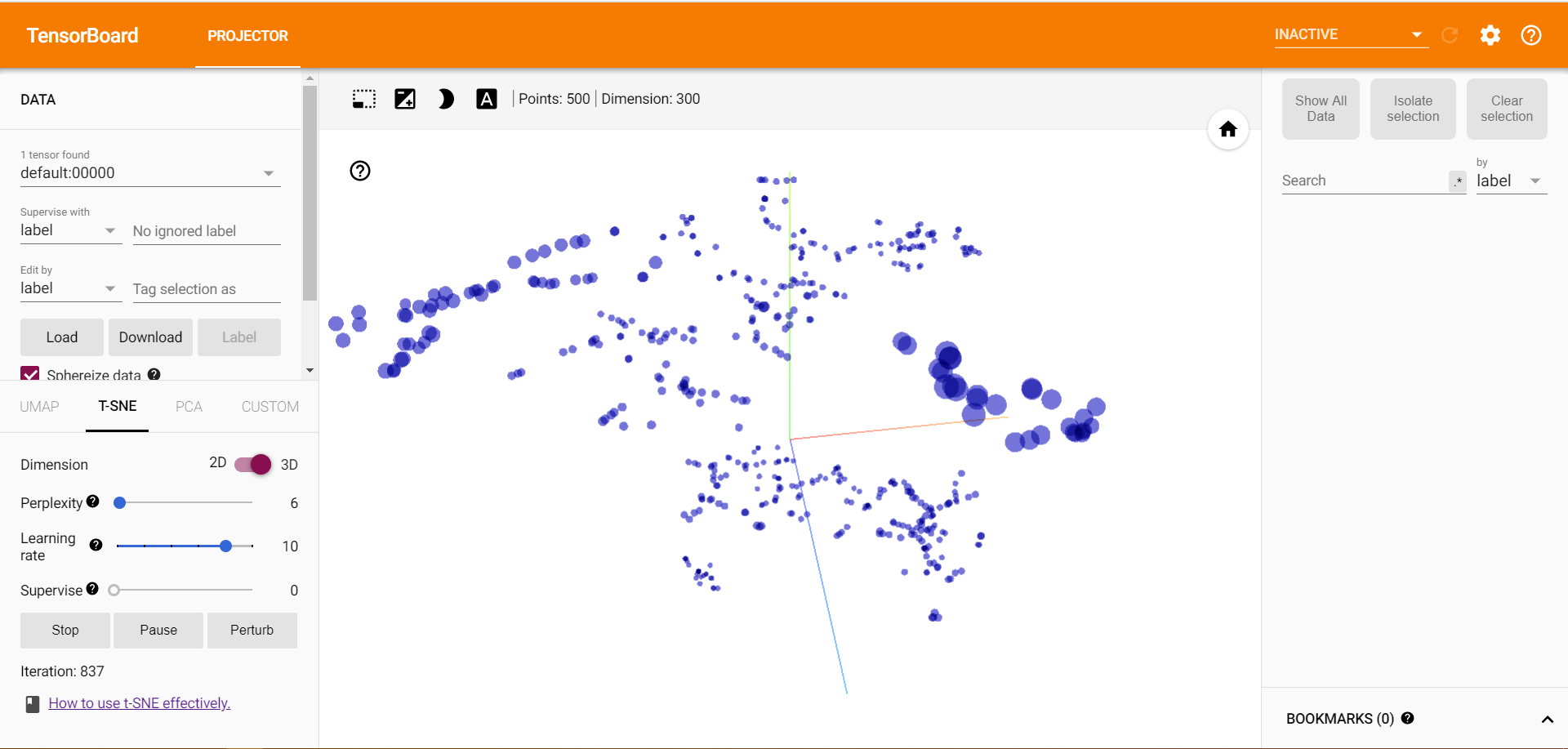
左にあるPCAから、T-SNEに変更してください。さらに集約されて類似の単語がまとめられていきます。
こちらはスクショですが、実際は学習の様子が動いてみえるのでとても興味深いです。
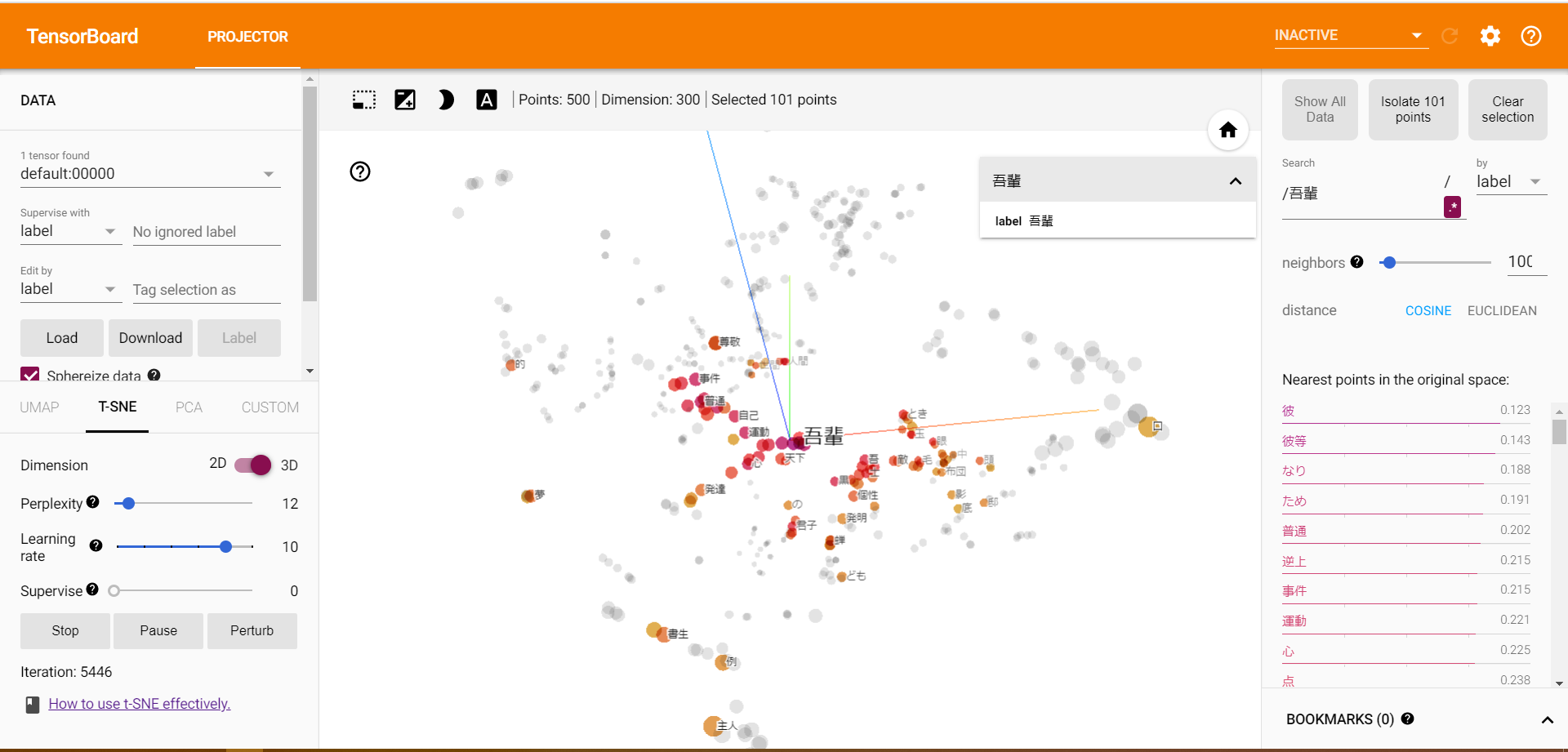
学習が収束してきたら、本題である「吾輩」と「猫」の類似性(距離)をみてみましょう。
右のsearchから「吾輩」と入力し、「吾輩」の点を見つけます。
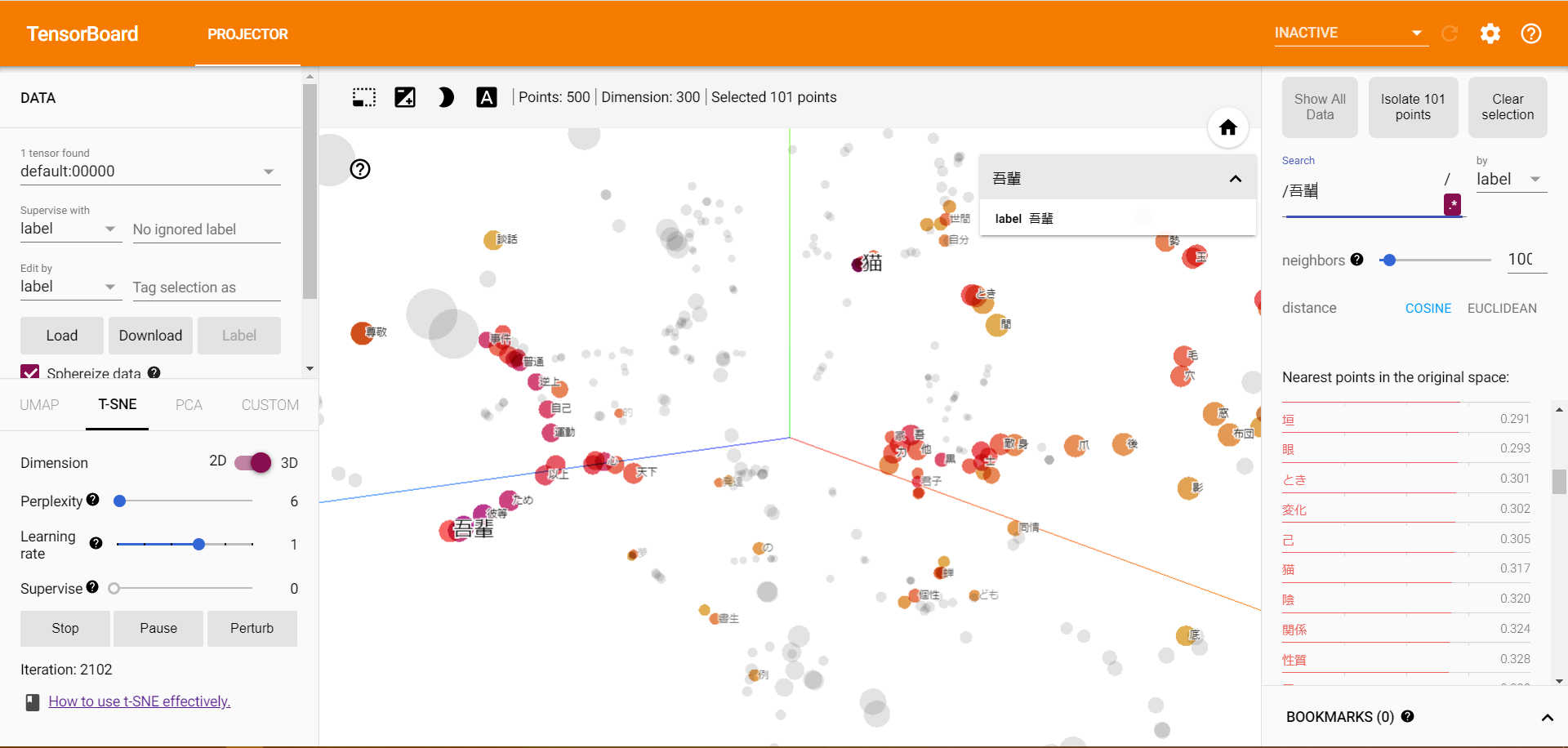
左下の方に「吾輩」、右上に「猫」がいます。距離は、0.317とすごく類似しているとは言い切れませんがそこそこ類似していることが分かりました。
「吾輩」と「猫」が同じ文脈上に現れることが少ないためこのようになったと考えられます。
それぞれの単語の類似性が高い語をみてみると、
「吾輩」に近い単語は上位に「彼」「彼等」と人称がきており、「猫」に最も近い単語は「人間」となり一応動物同士でまとめられているます。類似語をみてみると、うまく学習できてるように思えます。
まとめ
今回は、Colaboratory上でword2vecの学習とTensorBoardによる可視化を行ないました。
環境構築せずに、簡単に実装できるのはとても便利ですね。
インターネット上に公開せず、Colaboratoy上でPROJECTORの可視化もできれば、さらに便利になるのに!PROJECTORの可視化の対応を期待しています。
詳細な説明を省きましたので、用語やライブラリなどの詳しい説明は参考記事をご確認ください。
参考記事
【データ可視化】TensorBoardのProjectorをKerasとColaboratoryで実行する
Google Colaboratory で Mecab-ipadic-Neologd を使うまで
gemsimのword2vecのオプション一覧
ngrokが便利すぎる