前提としてAWS re:Invent2022のkeynoteを聞いていた人が参加した感想です。
また、かなり情報を削いでそれっぽくしているので細かい話は動画とかを観るのがいいかと思います。
また、撮影OKだったもののそのまま発表スライドの写真を載せていいかどうかは怪しいので今回はスライドを載せません。
受けた内容は以下です。
1日目
- 通信業界におけるリファレンスアーキテクチャ
- インシデントを起点に考えるシステム運用のユースケースをご紹介
- 従来の監視の課題とObservavilityの必要性
2日目
AWS Gameday(こちらの内容は記載しません)
1. 通信業界におけるリファレンスアーキテクチャ
5Gの通信実現においてAWSの活用事例がありました。
- 5Gネットワークの領域での課題
- AWS活用に期待する価値
自動化/俊敏性
工数管理を低減
経済性 - アーキテクチャ上の考慮点
遅延要件
遅延要件を満たす技術機能のサポート
自社のデータセンター上にOutpostsを配置してオンプレ上でAWSを使っています。
自社のデータセンターに配置するので通信のレイテンシーが低くなることなどが特徴に挙げられます。
以下はOutpostsの写真です。
(iphoneカメラのレンズが割れていてスモークがかかっているみたいになってすみません)

このセッションは途中から聞いていたのでどこの事例だったかはわからなかったですが、聞いていて思い出すのはこちらです。

NASDAQはミッションクリティカルなシステムでもAWS化に成功していて、re:Inventでもよく事例がでてきます。
上に挙げている動画の内容としては自社のデータセンタ上でOutpostsを置いて、低レイテンシーのネットワークをひいてます。
オンプレ上でAWSのサーバを置くとなると「従来のオンプレでも問題ないような?」と一見思いがちですが運用負荷の軽減という意味でAWSを使いたいというニーズがあるみたいです。
ではAWSの運用負荷ってどんなものなのでしょうか?
2.インシデントを起点に考えるシステム運用のユースケースをご紹介
IncidentManager、SystemsManagerをうまく使っていこうという話がメインでした。
1.インシデントの初動に対して
Runbookで修復定義を作成しておくとSystemsManagerAutomationで登録したRunbookが自動実行され自動修復したり手順表示したりできます。
IncidentManagerでなぜかSSHの接続が失敗したときの対応プランを作るとします。
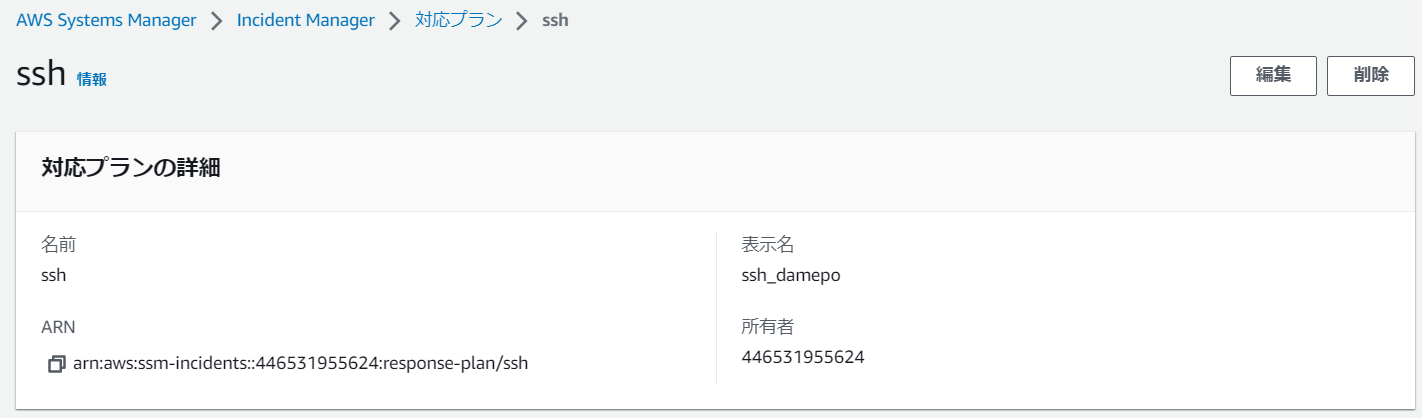
対応プランの中でrunbookを定義します。

このドキュメントはSSHのトラブルシューティングのrunbookでAWS側が8つのステップで解決を試みるようです。
また、IncidentManagerで「GWはincident-masterさんにメールが飛ぶようにしよう!」ってできます・・・。

他にも初動の対応としては以下が挙げられます。
- CloudWatch Logs Insight:細かいログを見る
- CloudWatch Internet Monitor:インターネットからアクセスした際の可用性とパフォーマンスと可視化
- CloudWatch Trail Lake:画面でイベントの分析ができる
(Athenaのテーブル定義をクリアして確認したり、S3からログをダウンロードしてないよね?)
2.トラブルシューティングについて
いろいろ見えてきて、EC2にログインしたいとします。
・Systems Manager Change Managerを使う
→上長承認がないと特権ユーザを使えないようにする
・接続はSSHでなく、Session Managerを使う
→SSHやRDPのインバウンドポートを開けないからセキュアでSSH鍵管理がなく、接続履歴が残るので発見的統制が取りやすい
終わったらなぜなぜ分析してRunbookの整備を行います(ここは汗をかく場所と言ってました)。
対応方針が満足でないならSSH接続が失敗したときにほかのrunbookも試すというイメージで理解してます。
3.日常運用で取り組んででいただきたいこと
以下の話をしていました。
おおよそ以下でした。
- 可視化
AWS Systems Manager Explorerでカスタマイズしたダッシュボードの管理、Systems Manager Inventoryで各サーバのメタデータを収集する。 - ベースラインの構築:AWS全体
AWS Security Hubでセキュリティベストプラクティスに従っているかを確認する。 - 定形作業の自動化の整備:Runbook
Systems Manager Patch Managerでパッチは適用を自動で確認する。
3.従来の監視の課題とObservavilityの必要性
従来のシステムと違ってELBやEC2、Lambda、Fargateのようにマクロサービスが増えて監視対象が増えて動的な状態が増えてきました。
(アーキテクチャによってはコンテナがサーバレスで100個以上起動していたら従来の監視で対応するのは難しいですよね。)
そこで、Observavilityという概念が出てきます。
Observavility:システムのどこで何がなぜ起こっているのか動作状況を把握できている状態
Observavilityに必要なテレメトリデータ
メトリクス(CloudWatch):時間間隔で計測されたデータの数値表現
→傾向の把握、予測に役立つ
ログ(CloudWatch Logs Insight):タイムスタンプが記録された、時間の経過とともに起こったイベントの記録
→予測不可能な振る舞いの発見に役立つ
トレース(AWS X-Ray):エンドツーエンドのリクエストフローの記録
→リクエストの流れと構造の両方を可視化することで因果関係の追跡に役立つ
これらを用いてObservabilityを達成していきます。
インシデント対応時は抽象度を意識して解析します。
上から順に抽象度は高いです。
- アラーム(CloudWatch)
- トレース(AWS X-ray)
- ダッシュボード(CloudWatch Dashboard)
- メトリクス分析(CloudWatch Embedded Metrics Format)
- ログ解析(CloudWatch Log Insight)
- 生ログ
このAWS X-rayでのObservabilityについてはすぐに画面を作れなかったのでまた今度やってみようかと思います。
セッション中は以下のような画面が出てきた気がします。
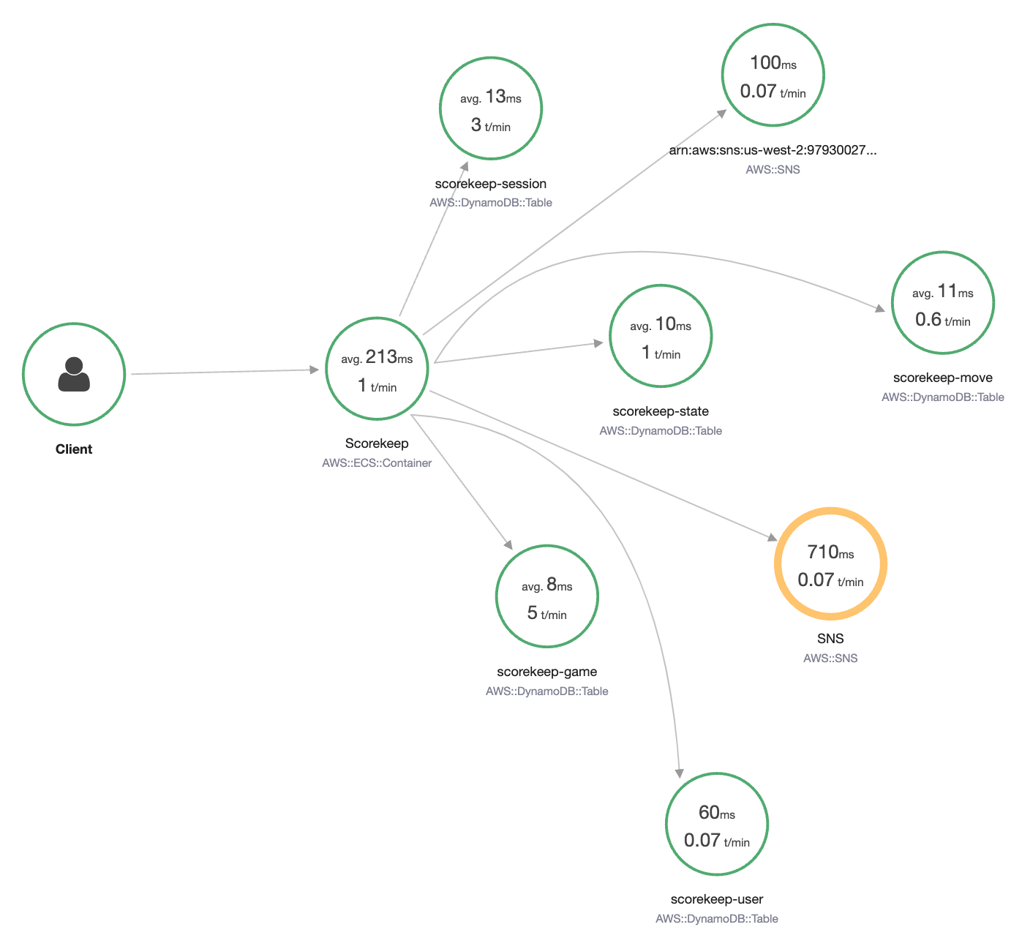
参考:https://docs.aws.amazon.com/ja_jp/xray/latest/devguide/aws-xray.html
これをみればAWS SNSが原因で遅延が起きていそうなのが一目瞭然ですね。
このセッションとは別にObservabilityで有名なNew Relicの展示で体験してきました。
メトリクスで問題になっているところをポチポチするだけで問題の原因まですぐにわかってしまうというモノでした。
AWS X-rayなどを使いこなせれば問題ないですが、ダッシュボードの管理に人手を割きたくなければ選択肢に入って来そうと思いました。
(お値段は知らないですが..)
基調講演について
基調講演はAWS re:Invent2022のkeynoteと話が被っているような部分は見受けられました。
そのせいで、認定者ラウンジでステッカーを先に取ることを優先して離席してしまいました。
ただし、AWS re:Invent2022のkeynoteとの明らかに違いはありました。
最初にAIや機械学習の話を最初にもってきていたことです。
ChatGPTの話が熱くなったのも年が明けてからなので、近年の情勢見て話の構成を考えていそうだなと思いました。
という訳で基調講演中に出てきたCodeWhispererを試してみました。
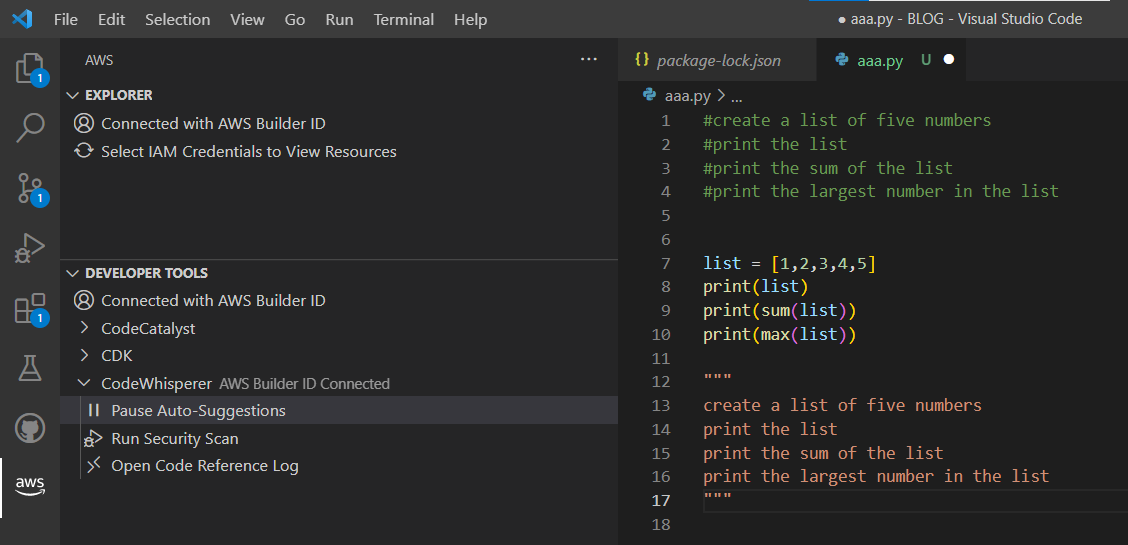
上記の結果のうち、実際にこちらで書いたのは以下だけです。
#create
勝手にガンガン書いてもらいましたが、python知らない私がこのレコメンドで勉強になりますね。(笑)
いろんなブログでS3バケットを作成するpythonを書いてもらってたりしますが、
うちの子はほかの子とは全く異なるコードを書いてくるので載せれません。。。