きっかけ
Observability というワードそのものはずっと聞くので、やってみたいなとは思っていました。
ただ、下記の理由でずっと後回しにしていました。
- 実際に動いてるこそ監視のやりがいがありそう、アプリは作れない。。
- ある程度の規模でないと面白味が薄そう(X-rayとかそう)
- 個人開発で環境準備する(動くものを作る)のが大変
- 業務上使う技術習得を優先して学習したい
そしてたまたま時間作れたのでやってみようという流れです。
ただし、マネージドサービスとある程度興味を持った部分に限ります。
また、これ以降の引用部分はすべて下記のworkshopからのもので、画面は個人で作業したものです。
作成する AWS リソースはこちらのようです。

まとめ
書いてて、これはさすがに最後まで読む人いないだろうということで先に書きます。
社外で話を聞くとCloudwatchをガンガンに使っている人もたまに聞きますが、
監視にマンパワーをあまりかけたくないからSaaSを使うという意見の方を多く見かけます。
なので、このworkshopもすべてをやるというよりは"こういう監視が欲しいんだけどできるのか?"ということに具体性をもって狙ったものを取り組めることにメリットを感じそうです。
また、私は14時間くらいで終わりました。
これ説明もう少し欲しいなと調べていると本当に時間かかります。
Cloud9で構築で躓いて確認で30分、CDKの実行で環境が立ち上げるまで30分という感じでした。
また、以下は体験できませんでした。
- ログの設計する
- X-rayのAgentを仕込む
そして終わってAWSリソースで使った利用料を確認したら12ドル!
セットアップ
セットアップはやってみたときに躓いたら記載するスタンスでいきます。次やる方のストレスが減ることを祈ってます。
2023/10/29 にやった時の話です。
リージョンの勘違い
cloudshellでCloud9を立ち上げる際に東京リージョンで実行してうまくいかず、バージニア北部で実行してうまくいきました。
jaの有効化
自分のAWS アカウントで利用する→アプリケーションのデプロイ→AWS CLI に現在の AWS リージョンをデフォルトとして設定するの部分でjaが効かなかったので以下で解決しました。
sudo snap install jq
バケットエラー
これも東京リージョンでやってしまったからバケットがないことを指摘されました。
とりあえず、このバケット名でその他はデフォルト設定で作成して進めてます。
(本来は CDK が作るものなのでいい加減な対応ですが、ひとまず進めたいのでこれでやっているだけです。)
Applications: fail: No bucket named 'cdk-hnb659fds-assets-446531955624-us-east-1'. Is account 446531955624 bootstrapped?
アプリケーションのデプロイ完了
ここまで1時間近くかかりました。
画面も確認できたので続きをやります。
一部エラーが起きていたような気もするのですが、リソース作成のコマンドだけで30分ほどかかり、
途中で離席していたこともありエラー文がterminalに残っていない。。
ひとまず立ち上がったようなので続きを。
Logs
CloudWatch Logs を使用すると、使用するすべてのシステム、アプリケーション、AWS サービスのログを、スケーラブルな 1 つのサービスに一元化できます。その後、簡単に表示したり、特定のエラーコードやパターンを検索したり、特定のフィールドに基づいてフィルタリングしたり、将来の分析のために安全にアーカイブしたりできます。CloudWatch Logs では、ソースに関係なく、すべてのログを一貫したイベントフローとして時間順に並べ替えたり、クエリを実行したり、他のディメンションに基づいて並べ替えたり、特定のフィールドでグループ化したり、強力なクエリ言語を使用してカスタム計算を作成したり、ダッシュボードでログデータを視覚化したりできます。
Logs Insights
CloudWatch Logs Insightsを使用すると、Amazon CloudWatch Logs のログデータを対話的に検索および分析できます。クエリを実行することで、運用上の問題に対してより効率的かつ効果的に対応できます。問題が発生した場合は、CloudWatch Logs Insights を使用して潜在的な原因を特定し、デプロイされた修正を検証できます。
CloudWatch Logs インサイトを見に行った結果です。
@がつくものはCloudwatchが自動で作成するものです。
抜粋ですが説明は以下のようです。
- fields コマンドを使用してタイムスタンプとメッセージを表示し、
- sort コマンドでタイムスタンプの降順(desc)にソートし、
- limit コマンドで最後の 20 件の結果を表示します。

クエリの保存も可能な様子。

保存すると、右側に作成したSample1というクエリが作成される。

クエリの履歴もクエリの実行の右側にある履歴から作成可能。

画面を見ての通りですが、ダッシュボードに追加ボタンがあるので実行するとそのまま配置されますね。

ログテーブル化

円グラフ化
Live Tail
Live Tailは、ログをリアルタイムでインタラクティブに表示する分析機能であり、アプリケーションのライフサイクル全体にわたって問題を迅速に検出してタイムリーに解決できます。Live Tailは、ログのストリーミングビューをフィルタリングし、関連するコンテンツを強調表示してさらに調査できるようにすることで、エンジニアがインシデントのトラブルシューティングを迅速に行えるようにします。CloudWatch Logs で Live Tail を使用することで、DevOps チームはプロセスが正しく開始されたかどうか、または新しいデプロイがスムーズに進んだかどうかを迅速に検証できます。
テーリングを開始を押すと

フィルター機能の設定に移ります。

- ロググループを選択
→デフォルトで選択されてました。少なくとも一つ選択のようです。 - ログストリームを選択
→? - フィルターパターンの追加
→petsite コンテナからログのみを取得したいので設定。(大文字小文字区別)
ログストリームの選択というのがぴんと来なかったので調べました。
https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/CloudWatchLogs_LiveTail.html
(オプション) ログ グループを 1 つだけ選択した場合は、ログ イベントを表示する 1 つ以上のログ ストリームを選択することで、Live Tail セッションをさらにフィルタリングできます。これを行うには、 [ログ ストリームの選択]で、ドロップダウン リストからログ ストリームの名前を選択します。あるいは、 [ログ ストリームの選択]の下の 2 番目のボックスを使用して ログ ストリーム名のプレフィックスを入力すると、そのプレフィックスと一致する名前を持つすべてのログ ストリームが選択されます。
例としてはこちらが出てきました。
ip-11-0-133-195.ec2.internal-application.var.log.containers.cwagent-prometheus-7954855c94-dmmn2_amazon-cloudwatch_cloudwatch-agent-df607d3cb7008380f04330f8b2cc220cae77e537fb931bcb118f2100c6d13511.log
そして実際にLivetail して見れるのがこちら。

5つまでの用語の強調表示が可能。(画像を加工したわけではないです)

Metrics
メトリクスはシステムのパフォーマンスに関するデータです。デフォルトでは、いくつかのサービスはリソース(Amazon EC2 インスタンス、Amazon EBS ボリューム、Amazon RDS DB インスタンスなど)に対して、無料のメトリクスが提供されます。また、Amazon EC2 インスタンスなどの一部のリソースの詳細モニタリングを有効にしたり、独自のアプリケーションメトリクスを公開することもできます。
Metricsの表示
メトリクスくらい知ってるよーって思ってたんですが"グラフ化したメトリクス"のタブから表示期間を1秒から15分置きで変えることができるのは忘れてました。
Metric Math
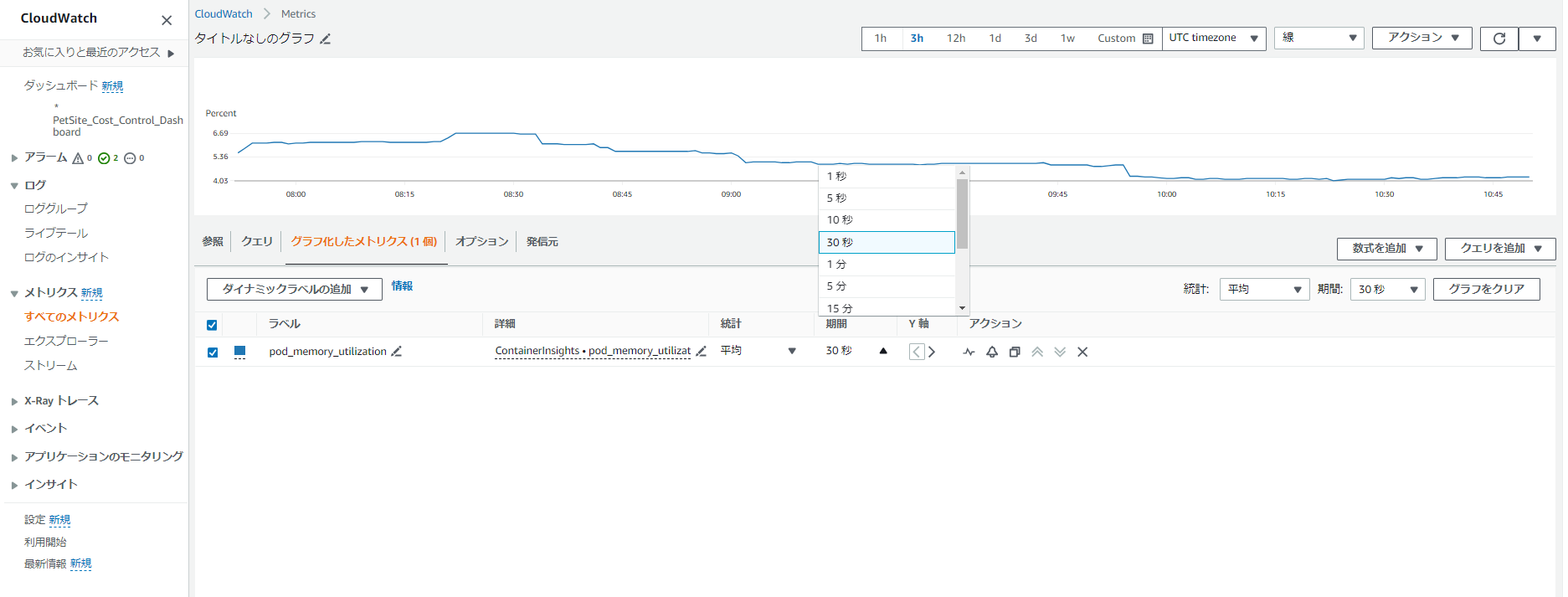
Metric Math を使用すると、複数の CloudWatch メトリクスをクエリし、数式を使用してこれらのメトリクスに基づいて新しい時系列を作成できます。結果の時系列を CloudWatch コンソールで視覚化し、ダッシュボードに追加できます。AWS Lambda のメトリクスを例にとると、 Errors メトリクスを Invocations メトリクスで割ると、エラー率を求めることができます。その後、結果の時系列を CloudWatch ダッシュボードのグラフに追加できます。
下の図が各項目の合計値SUMをグラフ化したもの
検索式
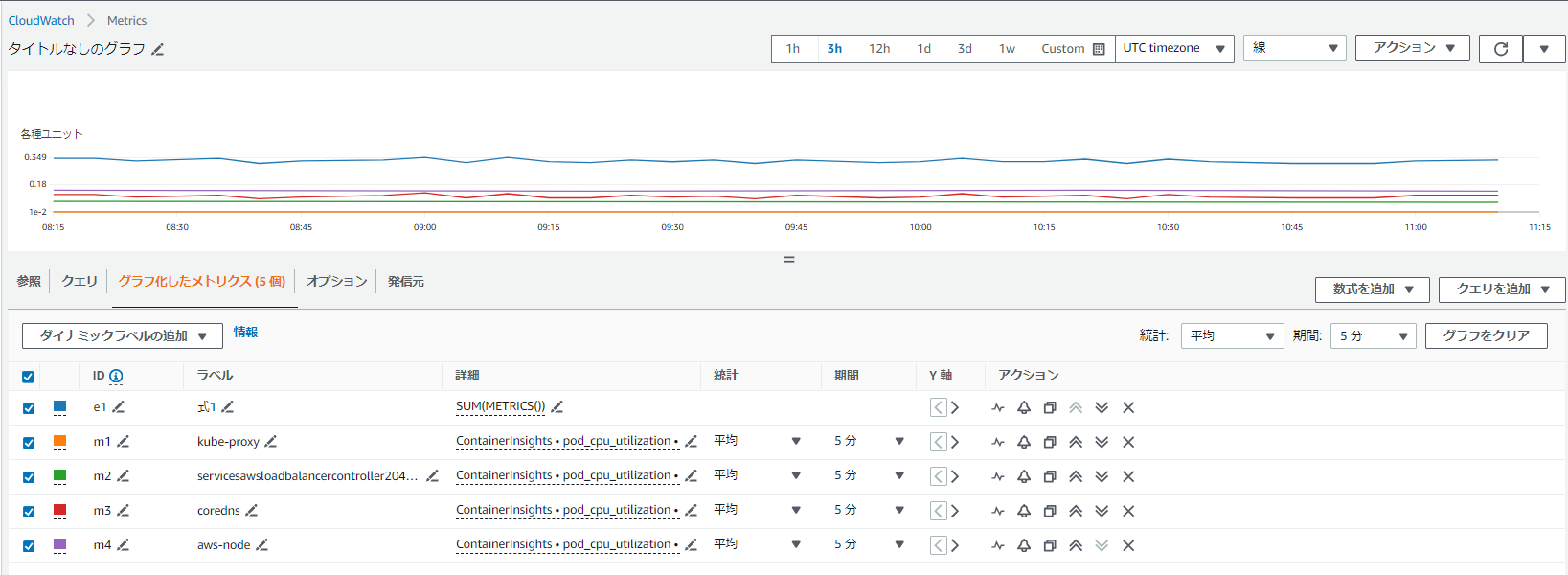
検索式は、CloudWatch グラフに追加できる数式の一種です。検索式を使用すると、複数の関連メトリクスをグラフにすばやく追加できます。また、グラフを初めて作成したときにそのメトリクスが存在していなくても、適切なメトリクスが自動的に表示に追加される動的なグラフを作成することもできます。
SEARCH(' {Namespace, DimensionName1, DimensionName2, ...} SearchTerm', 'Statistic')
SUM(SEARCH('{ECS/ContainerInsights,ClusterName} MetricName="TaskCount"', 'Average', 300))
上記の式はTaskCount名前空間のECS/ContainerInsightsメトリクスを示す。

Metrics Explorer
Metrics Explorer は、タグおよびリソースプロパティ別にメトリクスをフィルター、集計、視覚化できるタグベースのツールです。これにより、サービスのオブザーバビリティを高めることができます。Metrics Explorer の視覚化は動的であるため、Metrics Explorer ウィジェットを作成して CloudWatch ダッシュボードに追加した後に一致するリソースを作成すると、新しいリソースがエクスプローラーウィジェットに自動的に表示されます。
たとえば、リージョン内のすべてのインスタンスの AWS/EC2 の CPUUtilization メトリクスを表示する検索式を作成できます。後で新しいインスタンスを起動すると、新しいインスタンスの CPUUtilization が自動的にグラフに追加されます。
空のエクスプローラー→タイプ別のインスタンスこれだけでインスタンス別にメトリクスが一気に現れる。

同様にランタイム別のLambdaにした結果がこちら。
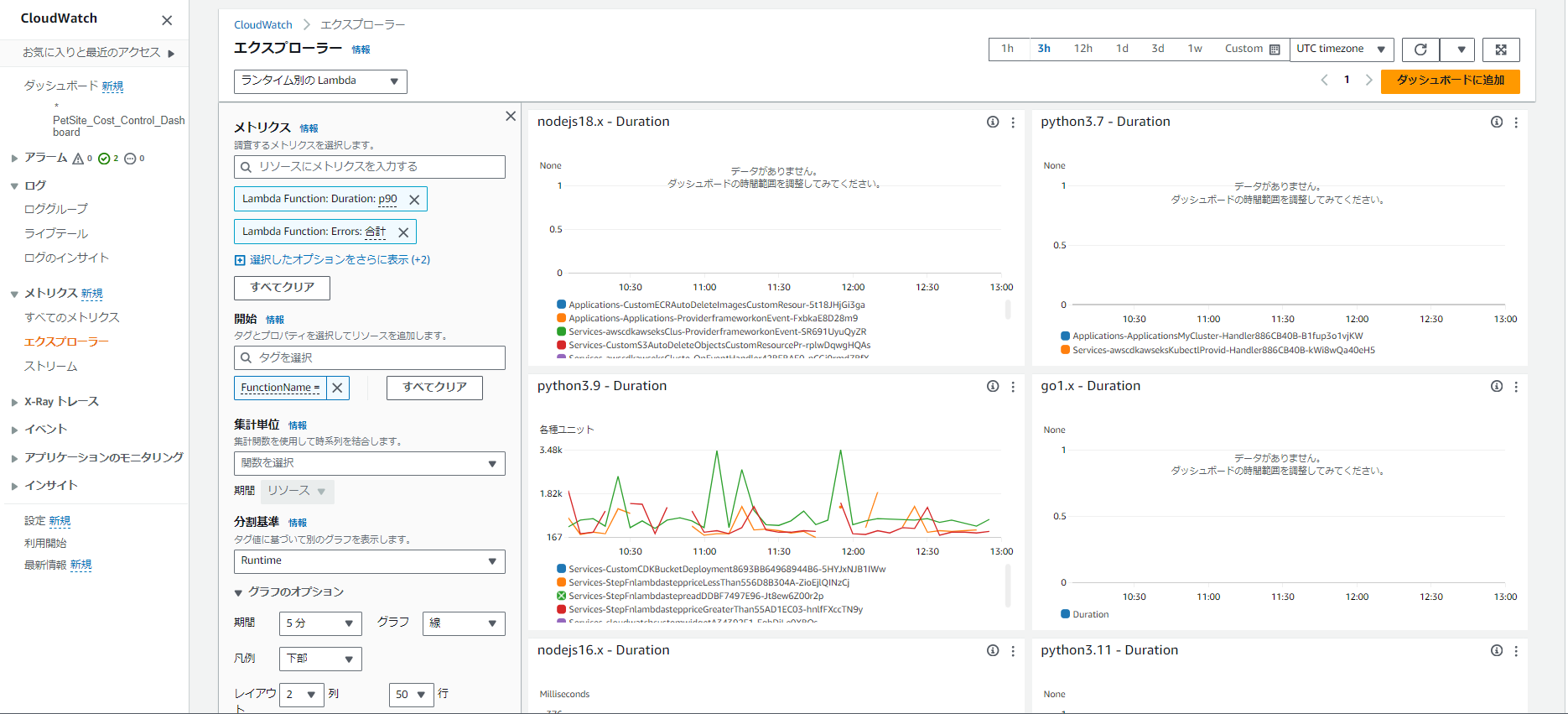
Metrics Insights
CloudWatch Metrics Insights は、大規模なメトリクスのクエリに使用できる高性能な SQL クエリエンジンです。1 つのクエリで最大 10,000 のメトリクスを処理できます。これまでは、CloudWatch メトリクスの傾向やパターンをリアルタイムで大規模に特定することが顧客にとって障害となっていました。
Metrics Insights クエリは CloudWatch コンソールを使用して実行することも、AWS CLI または AWS SDK から GetMetricData を使用して実行することもできます。また、お客様は Metrics Insights クエリから AWS CLI または AWS SDK を使用して PutDashboard API を使用してダッシュボードを作成することもできます。ダッシュボードは、新しいリソースがアカウントにプロビジョニングまたはプロビジョニング解除されても、最新の状態に保たれます。これにより、リソースがプロビジョニングまたはプロビジョニング解除されるたびにダッシュボードを手動で更新する手間が省けます。
ロードバランサーのRequestCountメトリクスを見た結果がこちら。

Metrics Insightsは数式よりも優れた点がある模様。
同様の例を取り上げて、Metric Insights が数式に比べていかに簡単かつ迅速にインサイトを提供できるかを検証してみましょう
たとえば、AWS アプリケーションロードバランサーは LoadBalancer, AvailabilityZone and TargetGroup ごとに RequestCount メトリクスを公開します。ロードバランサーのアベイラビリティーゾーンとターゲットグループ全体でリクエスト数がどのように分散されているかをさらに詳しく調べるためです。
数式を使用すると、検索、ソート、制限を行うことができます。ただし、メトリクスのグループ化機能はサポートしていません。その代わりに、さまざまな SEARCH 関数と SUM 関数を一緒に使用する必要があり、これはお勧めできません。
Metric Math(数式)フル活用例
SORT(SEARCH(' {AWS/ApplicationELB, AvailabilityZone, LoadBalancer, TargetGroup} MetricName="RequestCount" ', 'Sum', 300),SUM, DESC,5)

確かに、これをぱっと見た時の「えっとこれは何をやっているんだ?」って感じはありますね。
それに対して、
Metric Insights を使用すると、以下に示すように、さまざまなメトリクスを簡単にソート、グループ化、フィルタリング、制限することができます。

とのことです。
個人的には入力箇所が決められていてわかりやすく感じますね。
ただ、実現したいことが複雑になってくるとどうしても設定項目や条件が増えて複雑になっていってしまうのは仕方ないように見えますね。
ちなみに参考が載ってました。
SELECT SUM(RequestCount) FROM SCHEMA("AWS/ApplicationELB", AvailabilityZone,LoadBalancer,TargetGroup) GROUP BY LoadBalancer ORDER BY SUM() DESC LIMIT 5
SELECT SUM(RequestCount) FROM SCHEMA("AWS/ApplicationELB", AvailabilityZone,LoadBalancer,TargetGroup) GROUP BY AvailabilityZone, LoadBalancer ORDER BY SUM() DESC LIMIT 5
SELECT SUM(RequestCount) FROM SCHEMA("AWS/ApplicationELB", AvailabilityZone,LoadBalancer,TargetGroup) GROUP BY LoadBalancer, TargetGroup ORDER BY SUM() DESC LIMIT 5
Alarm
CloudWatch ダッシュボードにアラームを追加し、視覚的に監視できます。ダッシュボードにアラームがあると、アラームは ALARM 状態になると赤に変わり、ステータスをプロアクティブに監視しやすくなります。
アラームは持続的な状態変更に対してのみアクションを呼び出します。特定の状態にあり、状態が変更され、指定された期間維持されている場合のみ、CloudWatch アラームはアクションを呼び出します。
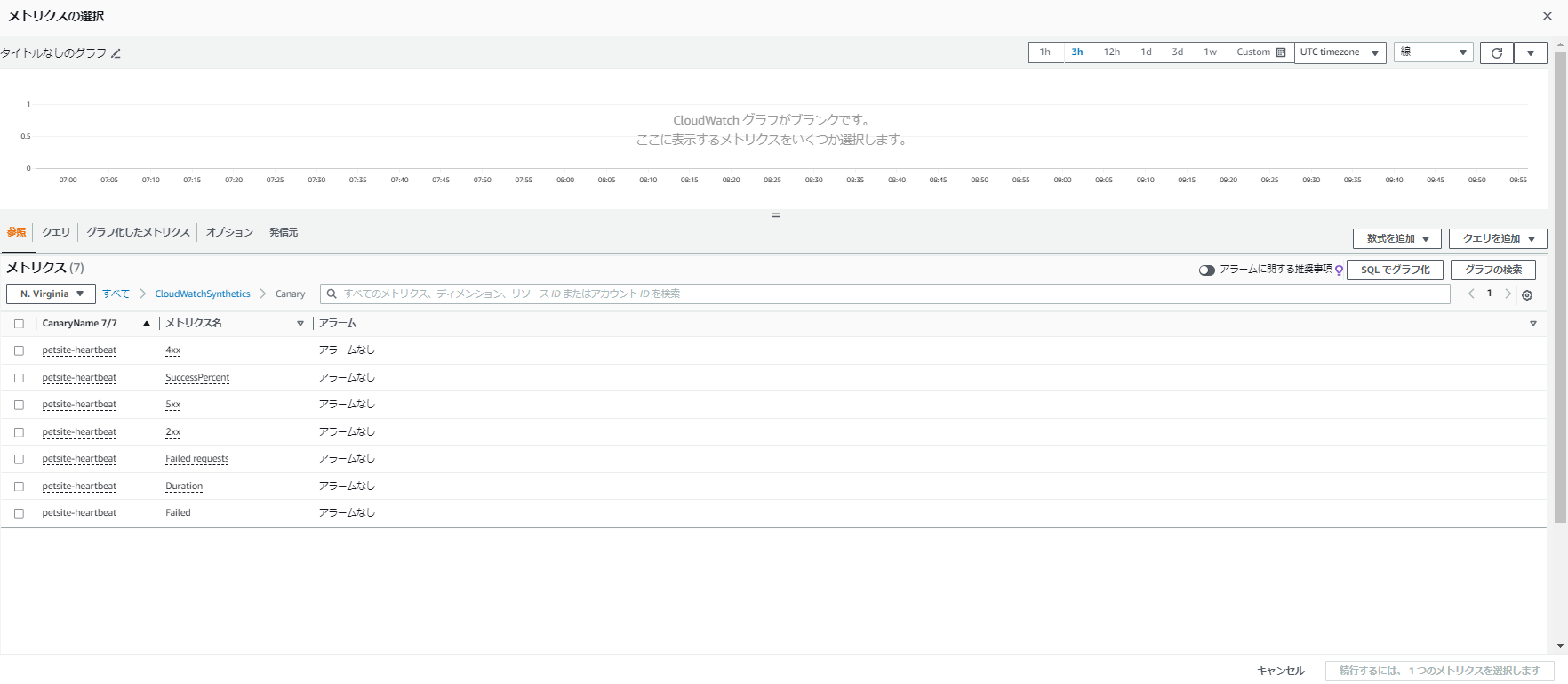
実際にメトリクスアラームを作成してみます。
メトリクスを選択し、

閾値等の詳細条件を加えます。
"アラームを実行するデータポイント"は下記の設定だと5回の評価期間のうち2回閾値を超えるとアラートすることになります。
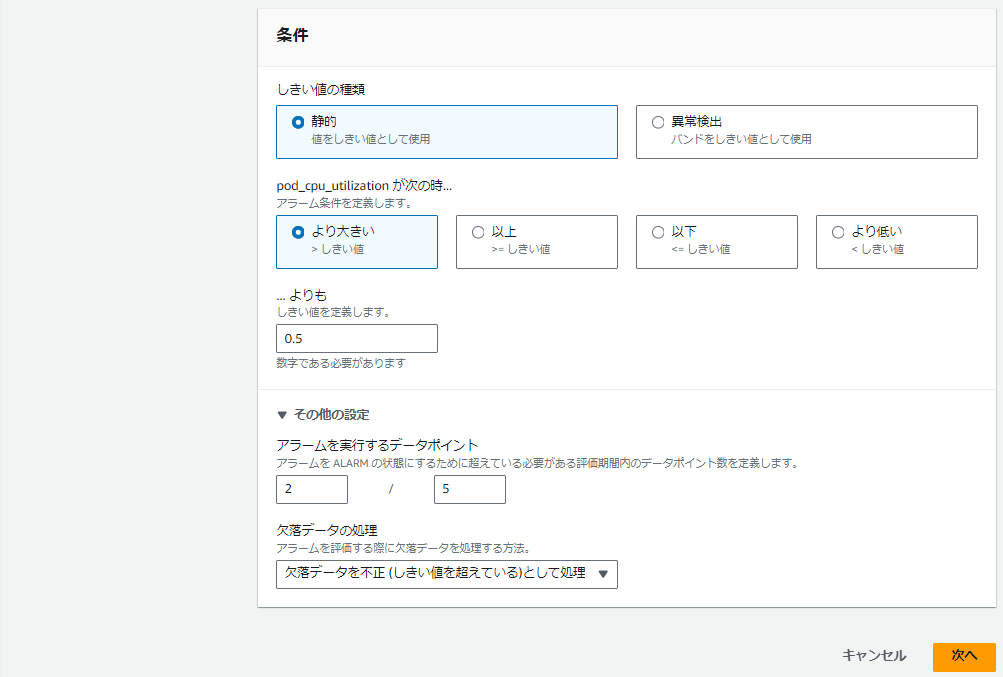
あとは下の図の設定でアラームが次にどの状態になった時にどのアクションを設定するかです。
アラート状態から復帰して復帰した通知が欲しいとかで使いそうですね。]
画面が切れてますが、アラート時にSystems Managerを実行もできるみたいです。

作成すると


アラームが来ていました。ちなみにメールも来ていました。

Trace
AWS X-Ray は、開発者がマイクロサービスアーキテクチャなどを使用して構築された分散アプリケーションを、本番環境において分析およびデバッグするのに役立ちます。X-Rayを使用すると、アプリケーションとその基盤となるサービスのパフォーマンスを把握して、パフォーマンスの問題やエラーの根本原因を特定し、トラブルシューティングできます。X-Rayは、アプリケーションを通過するリクエストのエンドツーエンドのビューを提供し、アプリケーションの基礎となるコンポーネントのマップを表示します。X-Ray を使用すると、シンプルな 3 層アプリケーションから、数千のサービスで構成される複雑なマイクロサービスアプリケーションまで、開発および本番環境の両方のアプリケーションを分析できます。
Service map on X-Ray
サービスマップを立ち上げ、色々見てみます。
全体感

拡大

アイコン表示からメトリクス表示に切り替え

ノードを選択すると各ノードのメトリクスや処理したリクエストの応答時間分布などが表示されます。


X-Ray Annotations
ノードを選択したまま、トレースを表示を選択すると下記のような画面になりました。
(workshop手順とは挙動が違いましたね。)

このままどれかのトレースIDを選択するとトランザクションを追うことができます。
下の図は上の図から選んだものではなく、エラーになっていそうなトレースIDを探して表示したものです。
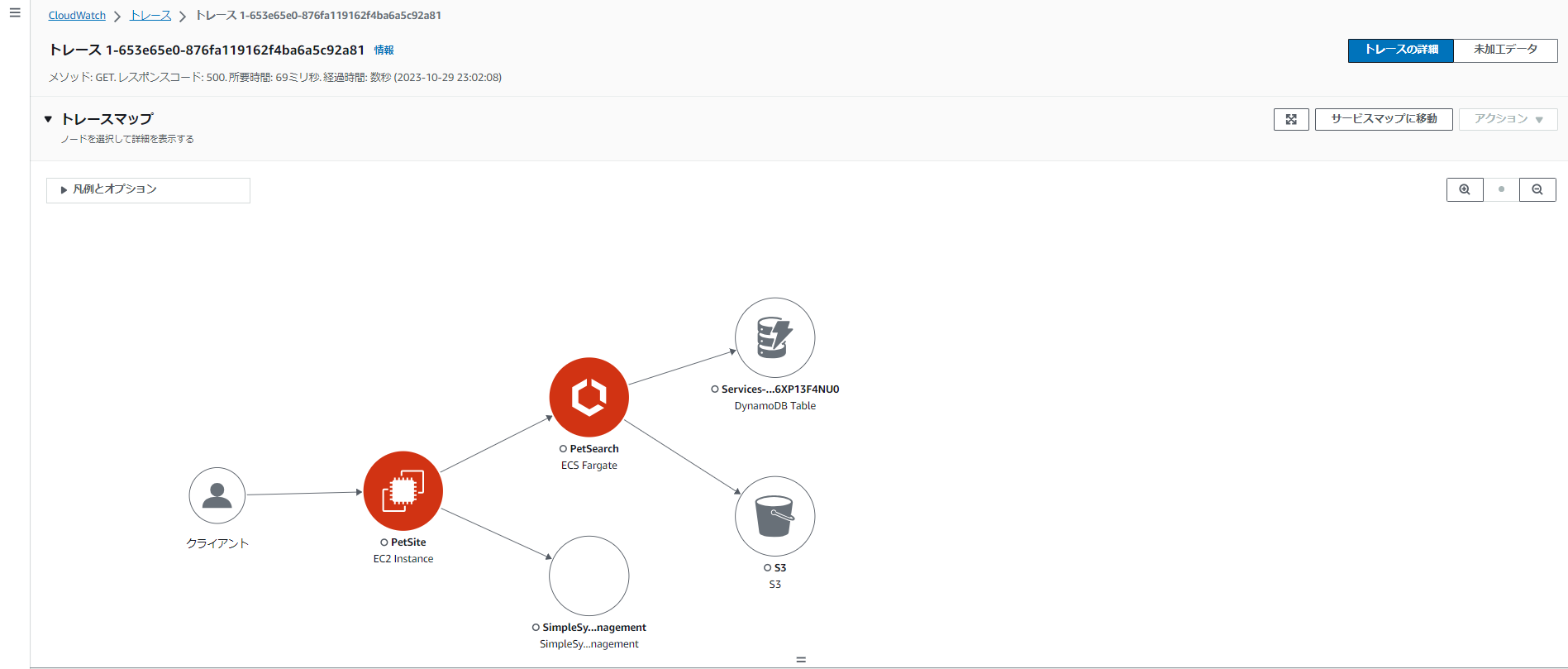



こうして、何のリソースに問題があるのかを可視化してくれます。
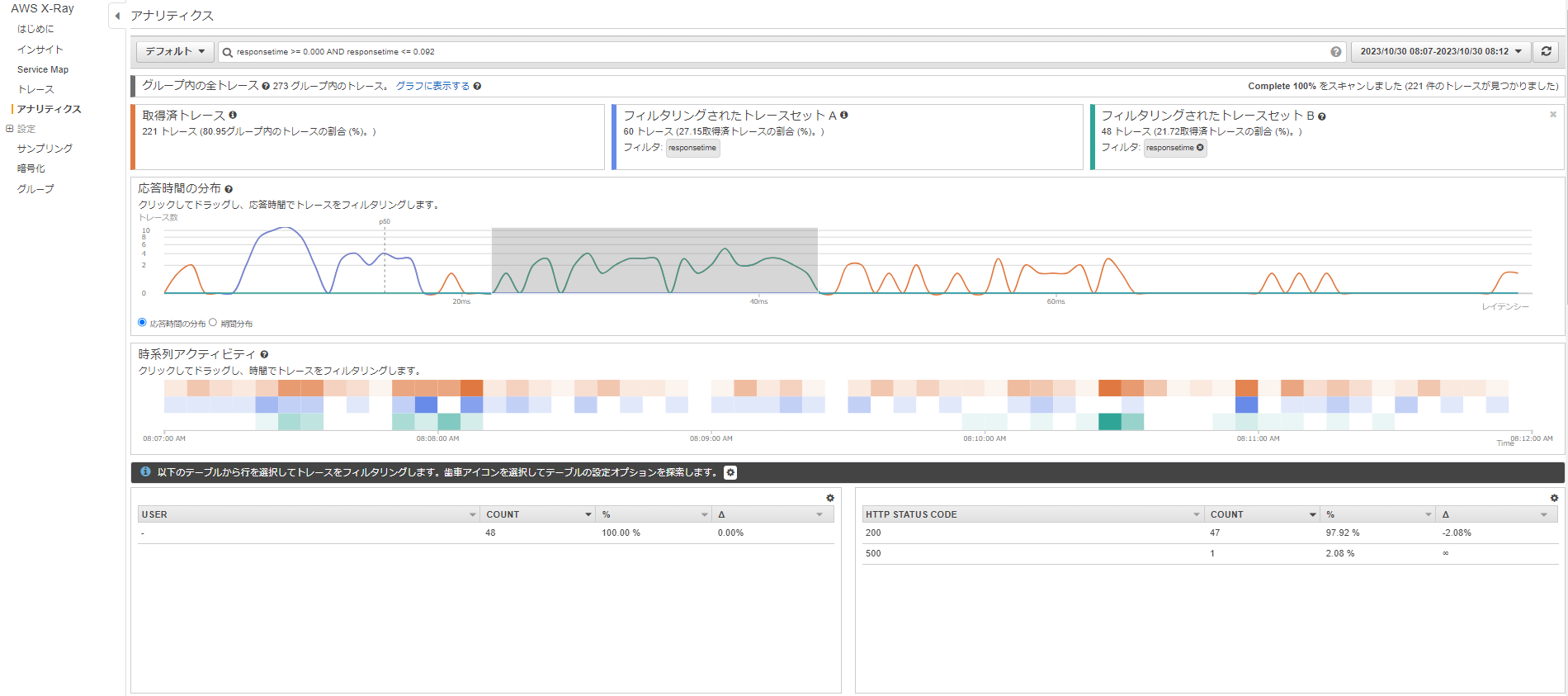
X-Ray Analytics
AWS X-Ray Analytics コンソールは、トレースデータを解釈してアプリケーションやその基盤となるサービスのパフォーマンスをすばやく理解するためのインタラクティブなツールです。このコンソールを使用すると、インタラクティブな応答時間グラフと時系列グラフを使用して、トレースを調査、分析、および視覚化できます。
https://docs.aws.amazon.com/ja_jp/xray/latest/devguide/xray-console-analytics.html
下の画面に行くのにX-rayとサービスを検索してもCloudWatchに戻されてしまいました。
CloudWatchとX-rayを統合しようとしている過渡期なんですかね。
サービスマップからノードを選択して、トレースの分析を選択するとこちらの画面に移動しました。

レイテンシの高そうな部分をドラッグで選択します。
するとHTTPステータスなどが表示されます。
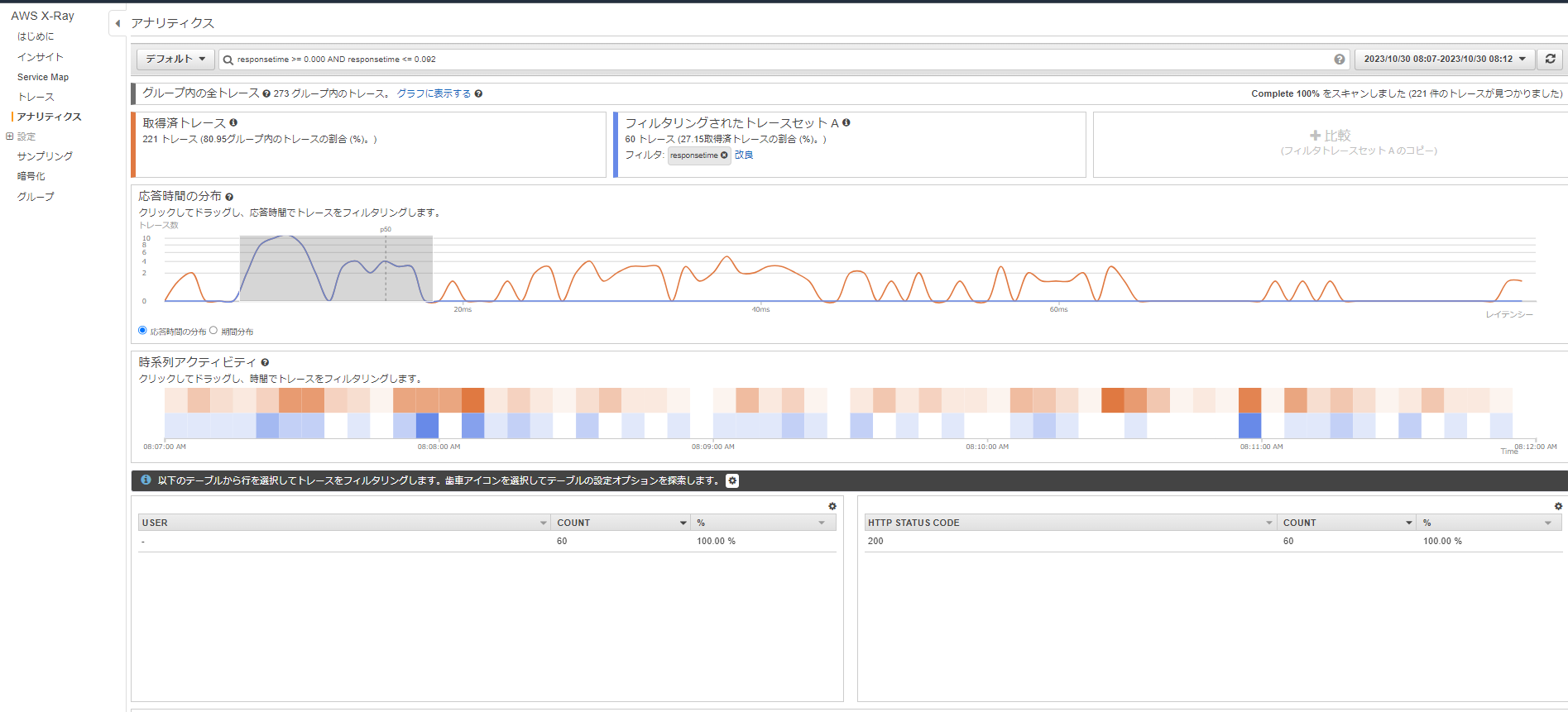
下の画面にRESPONSE TIME ROOT CAUSEという項目があり、これでレイテンシの根本原因が自動で特定されます。


また、比較機能を用いることもできます。
ユースケースが正直ぴんと来ていないのですが以下だそうです。
Analytics コンソールを使用して、根本原因分析の目的で異なる条件を持つ 2 つのトレースのセットを比較することもできます。
アプリケーションモニタリング
CloudWatch ServiceLens
CloudWatch ServiceLens は、トレース、メトリクス、ログ、アラームを 1 か所に統合できるようにすることで、サービスとアプリケーションの可観測性を高めます。ServiceLens は CloudWatch と AWS X-Ray を統合し、アプリケーションのエンドツーエンドのビューを提供し、パフォーマンスのボトルネックをより効率的に特定し、影響を受けたユーザーを特定するのに役立ちます。サービスマップは、サービスエンドポイントとリソースを「ノード」として表示し、各ノードとその接続のトラフィック、レイテンシー、エラーをハイライト表示します。ノードを選択して、サービスのその部分に関連付けられている相関メトリクス、ログ、トレースに関する詳細情報を表示できます。これにより、問題とそのアプリケーションへの影響を調査できます。
CloudWatch ServiceLensを開くとX-rayと同様のサービスマップが開きます。
petlistadoptionsを選択すると下の画面が出てきます。
そのままContainer Insightsで表示もできます。

一か所にまとまってるから使いやすい、これに尽きる立ち位置に感じました。
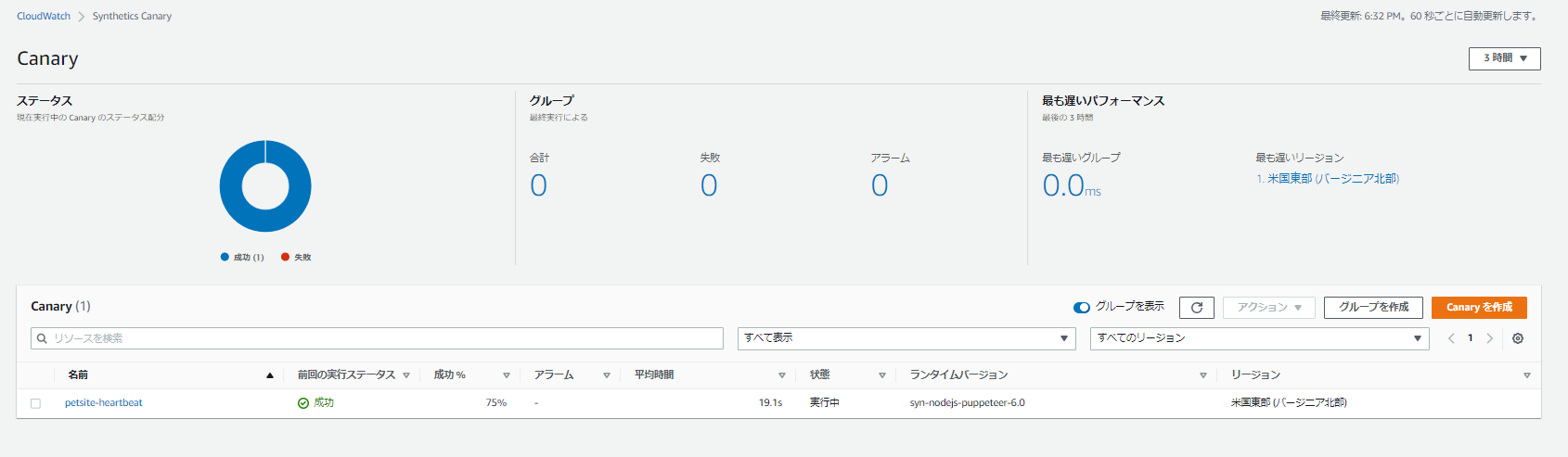
CloudWatch Synthetics
Amazon CloudWatch Syntheticsを使用して、エンドポイントやAPIを監視するためのCanary(スケジュールに従って実行される設定可能なスクリプト)を作成することができます。Canaryは、お客様と同じ通信経路をたどり、同じアクションを実行します。これにより、アプリケーションにお客様による通信がない場合でも、お客様体験を継続的に検証することができます。Canaryを使用することで、お客様よりも先に問題を発見することができます。
Heartbeat Canary
CloudWatch SyntheticsでCanaryを作成する際、ブループリントを使用を選択することができます。 ブループリントは、特定のユースケースのためにあらかじめビルドされたコードを提供します。 ブループリントは、コーディングの経験がなくてもSyntheticsを使用するための優れたエントリーポイントを提供します。
作成したページへのアクセスが上手くいくかを設定します。
URLもサイトURLです。また、1分間隔での監視にしています。

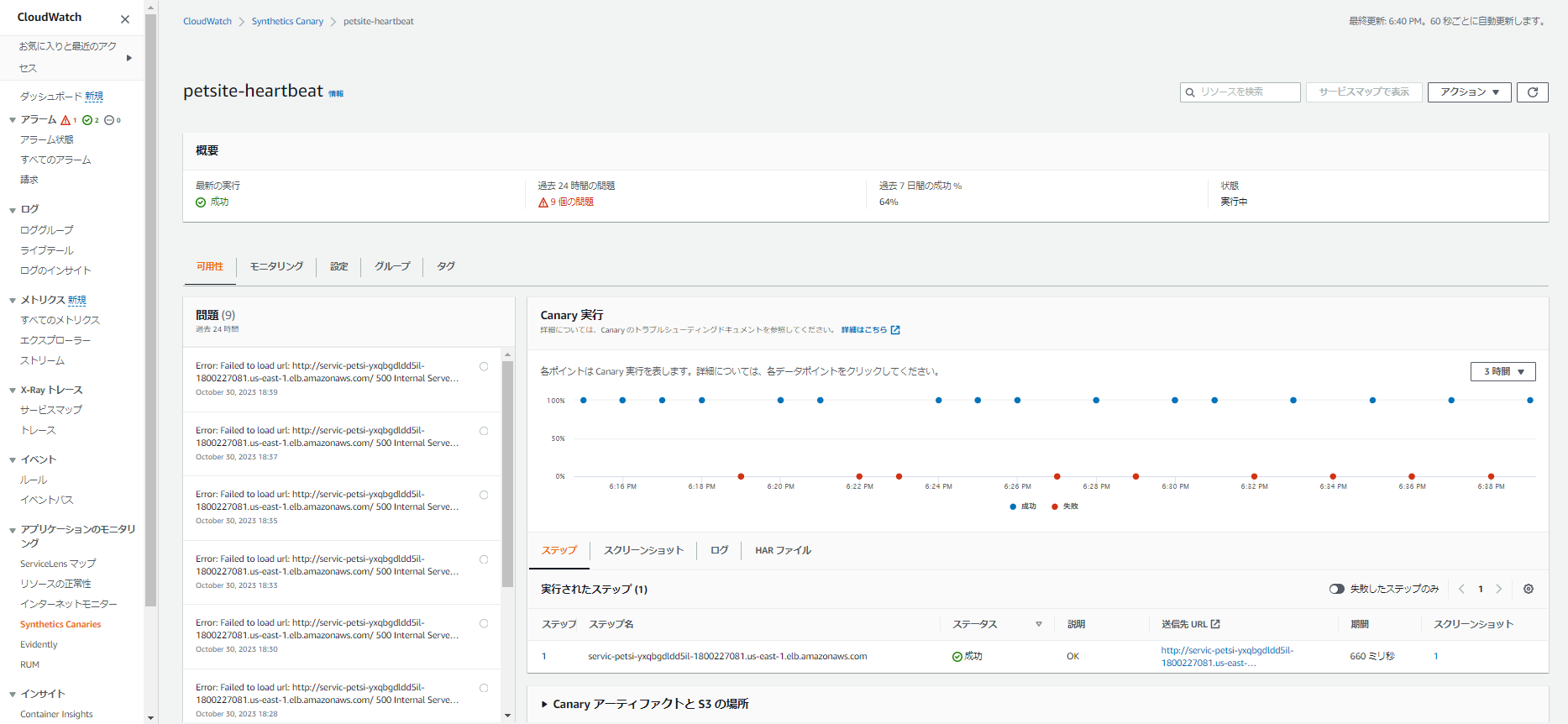
失敗した時



失敗時のログもありますね。
2023-10-30T09:37:10.719Z ERROR: 1 step failed while executing the canary
2023-10-30T09:37:10.719Z ERROR: Canary error:
Error: Failed to load url: http://servic-petsi-yxqbgdldd5il-1800227081.us-east-1.elb.amazonaws.com/ 500 Internal Server Error Stack: Error: Failed to load url: http://servic-petsi-yxqbgdldd5il-1800227081.us-east-1.elb.amazonaws.com/ 500 Internal Server Error at /opt/nodejs/node_modules/pageLoadBlueprint.js:81:23 at process.processTicksAndRejections (node:internal/process/task_queues:95:5) at async Synthetics.executeStep (/opt/nodejs/node_modules/Synthetics.js:446:31) at async loadUrl (/opt/nodejs/node_modules/pageLoadBlueprint.js:63:5) at async loadBlueprint (/opt/nodejs/node_modules/pageLoadBlueprint.js:32:9) at async exports.handler (/opt/nodejs/node_modules/pageLoadBlueprint.js:100:12) at async exports.handler (/var/task/index.js:87:24) for step: servic-petsi-yxqbgdldd5il-1800227081.us-east-1.elb.amazonaws.com

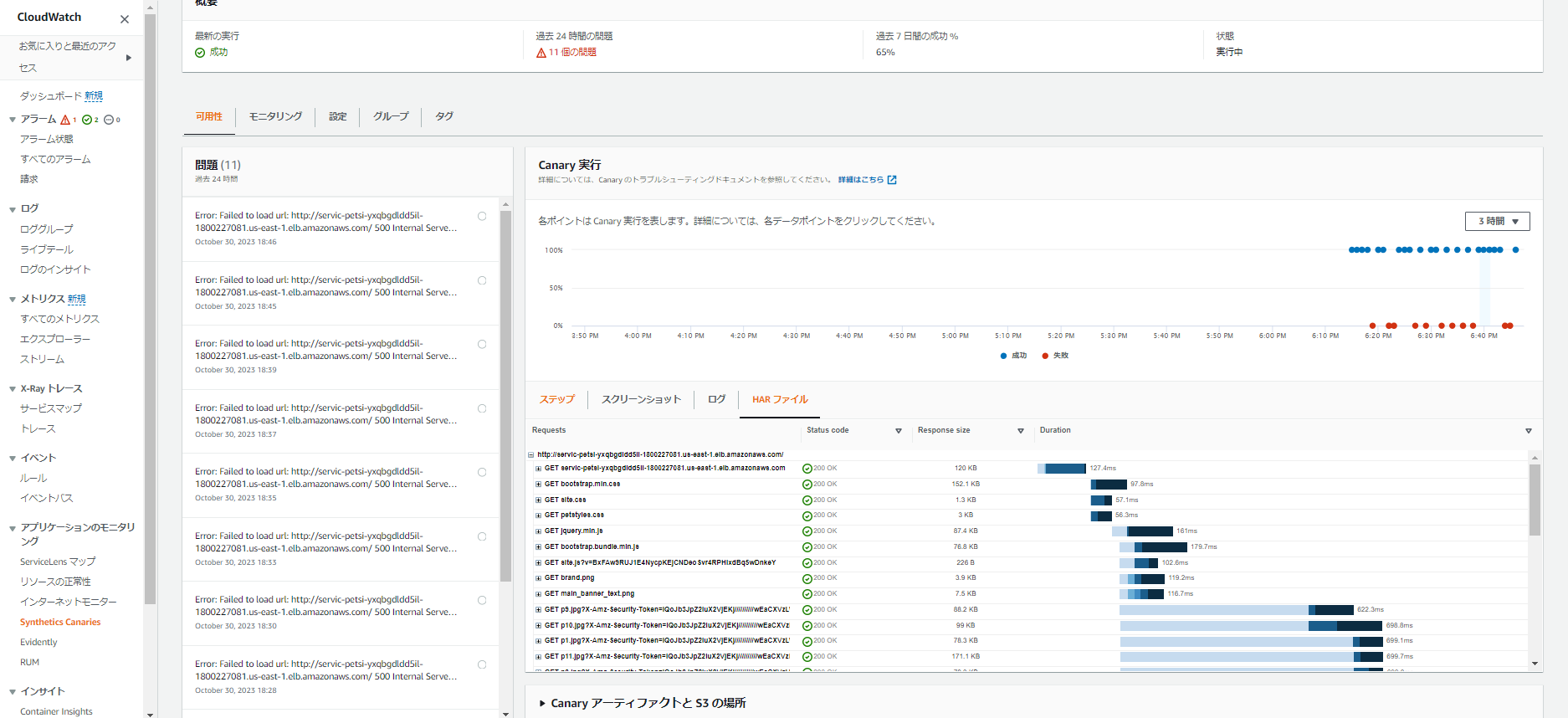
HAR ファイルには、実行された HTTP リクエストとそのサイズと期間が表示されます。
このデータから、時間がかかる、または非常に大きいアセットを調査することができます。 可能であれば、これらを削減または削除することで、ユーザーの全体的な体験を向上させることができます。
また、各リクエストを展開し、レスポンスヘッダーやリクエストヘッダーを確認することもできます。
成功した時

Canaryメトリクス
より詳細な結果を確認したい場合、 このセクションでは、Canaryチェックの実行時間、失敗、成功、選択したHTTPコード範囲などの主要なメトリクスの平均値やタイムチャートが表示されます。
また、これらのMetricsはCloudWatch Metricsコンソール上のCloudWatch Syntheticsのカスタム名前空間でも確認することができます。


Lambdaメトリクス
各Canaryの裏側には、Lambda関数が実行されています。 ここでのメトリクスは、Lambda関数のパフォーマンスを理解するのに役立ちます。
ここでは、Lambda関数の実行時間、エラー、スロットルなどのタイムチャートを確認できます。
また、これらのメトリクスは、CloudWatch Metricsコンソール上のLambdaのAWS名前空間で確認することができます。
文字つぶれてますが。。
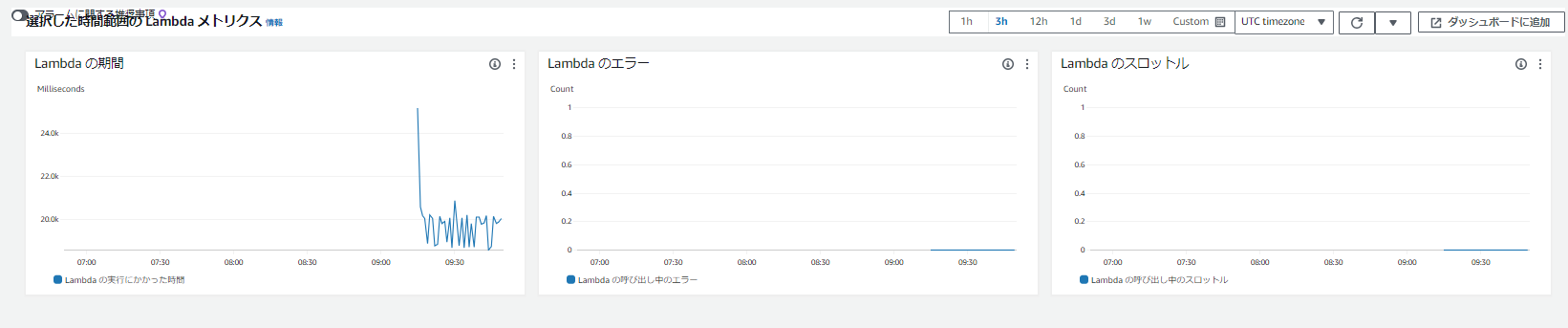
アラームも作れそうですね。
CloudWatch RUM
CloudWatch RUM(Real User Monitoring)は、クライアント側のパフォーマンスの問題を特定し、より迅速な解決を可能にすることで、アプリケーション開発者やDevOpsエンジニアがエンドユーザーエクスペリエンスを最適化するのに役立ちます。 CloudWatch RUMは、Webアプリケーションのパフォーマンスに関するクライアントサイドのデータをリアルタイムで収集して問題を特定およびデバッグすることにより、リアルユーザーモニタリングを提供します。
CloudWatch RUMは、パフォーマンスの異常を視覚化し、エラーメッセージ、スタックトレース、ユーザーセッションなどの関連するデバッグデータを提供して、JavaScriptエラー、クラッシュ、レイテンシーなどのパフォーマンスの問題を診断することができます。ユーザー数、地理的位置、ブラウザーなど、エンドユーザーへの影響の範囲も把握できます。 バウンスされたユーザーセッションを比較するなどの方法で、ユーザーの行動とクリックストリームパスを分析することにより、RUMは開発者が機能追加とバグ修正に優先順位を付けるのに役立ちます。
基本設定の上、
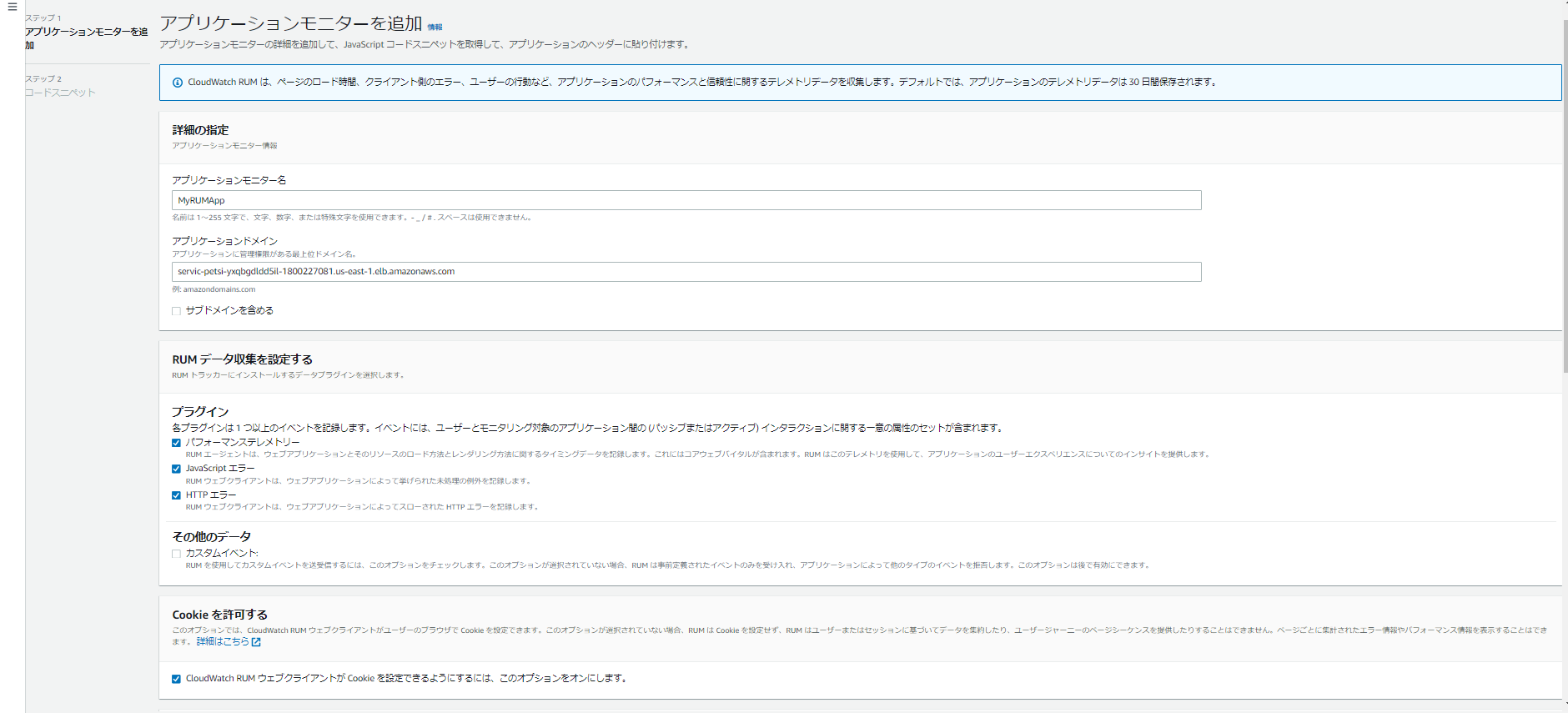

埋め込んでほしいコードが出てきます。

これを埋め込むためにSSM Parameter Storeを修正するとアプリへ反映される?ようです。
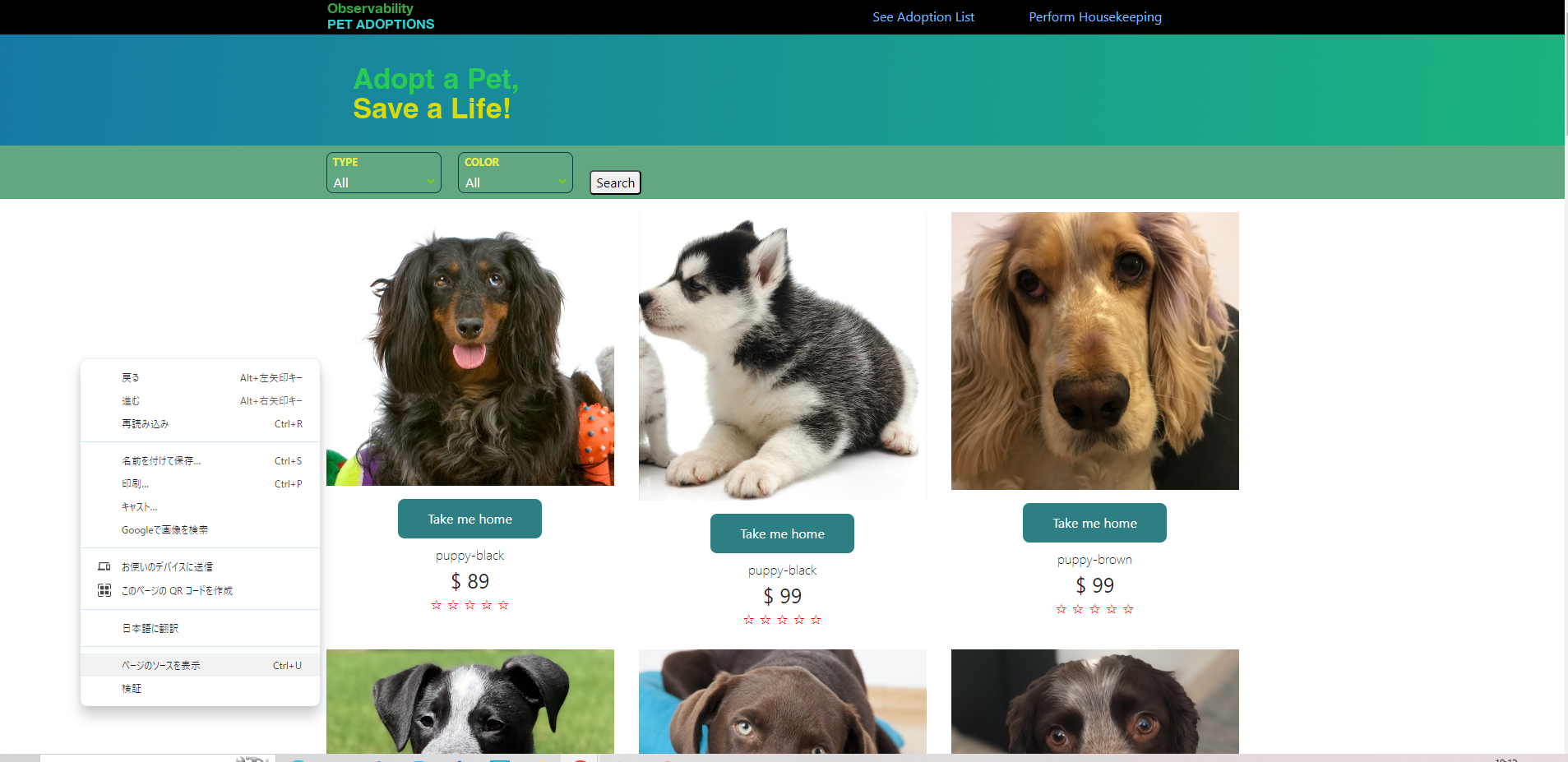
webページから"ページのソースを表示"をやってみると
確かに埋め込んだコードが入ってますね。

RUMの画面を見に行くと見えました。

この先、見れるものが多い。。
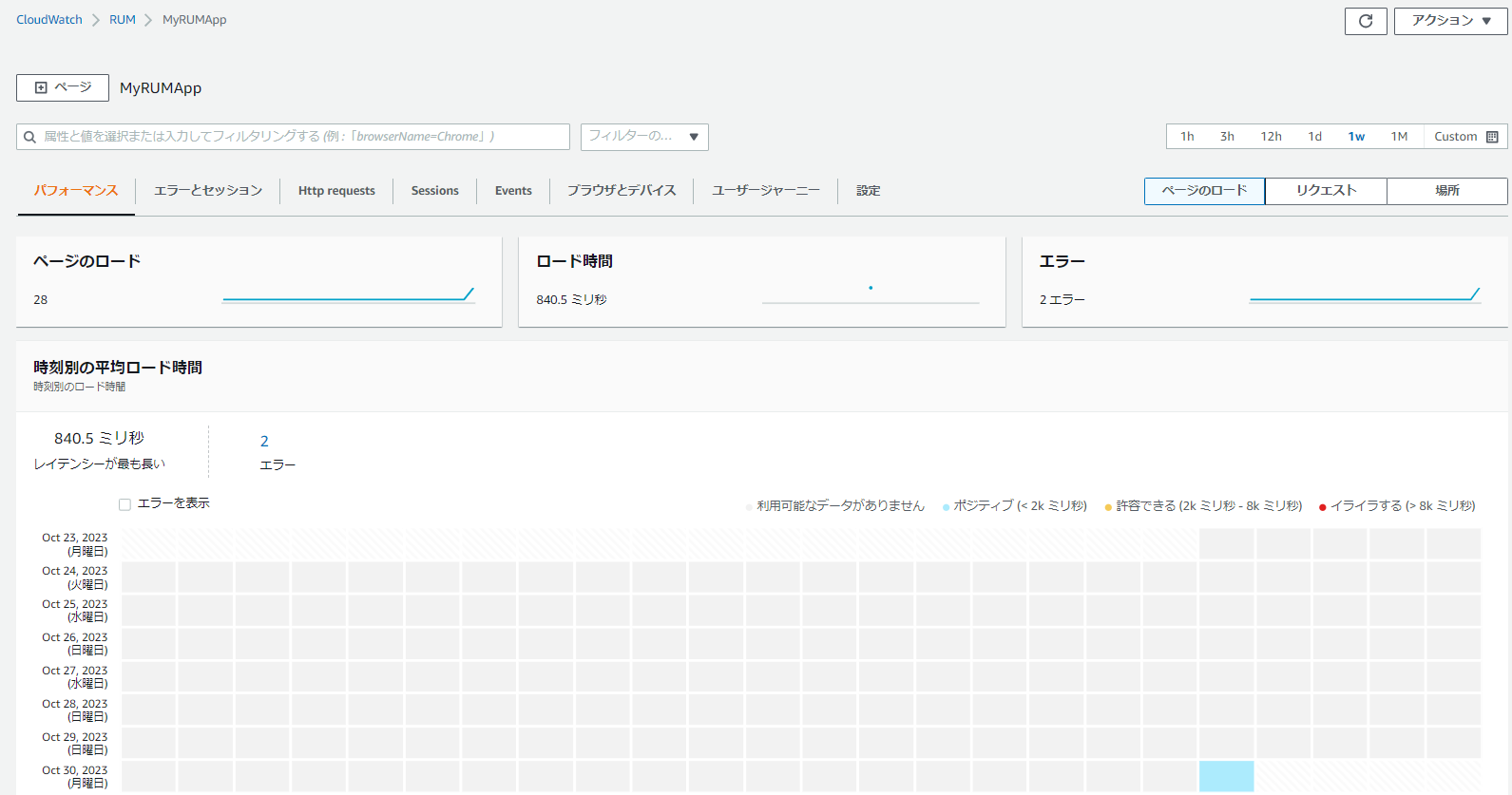
パフォーマンス
時刻別の平均ロード時間
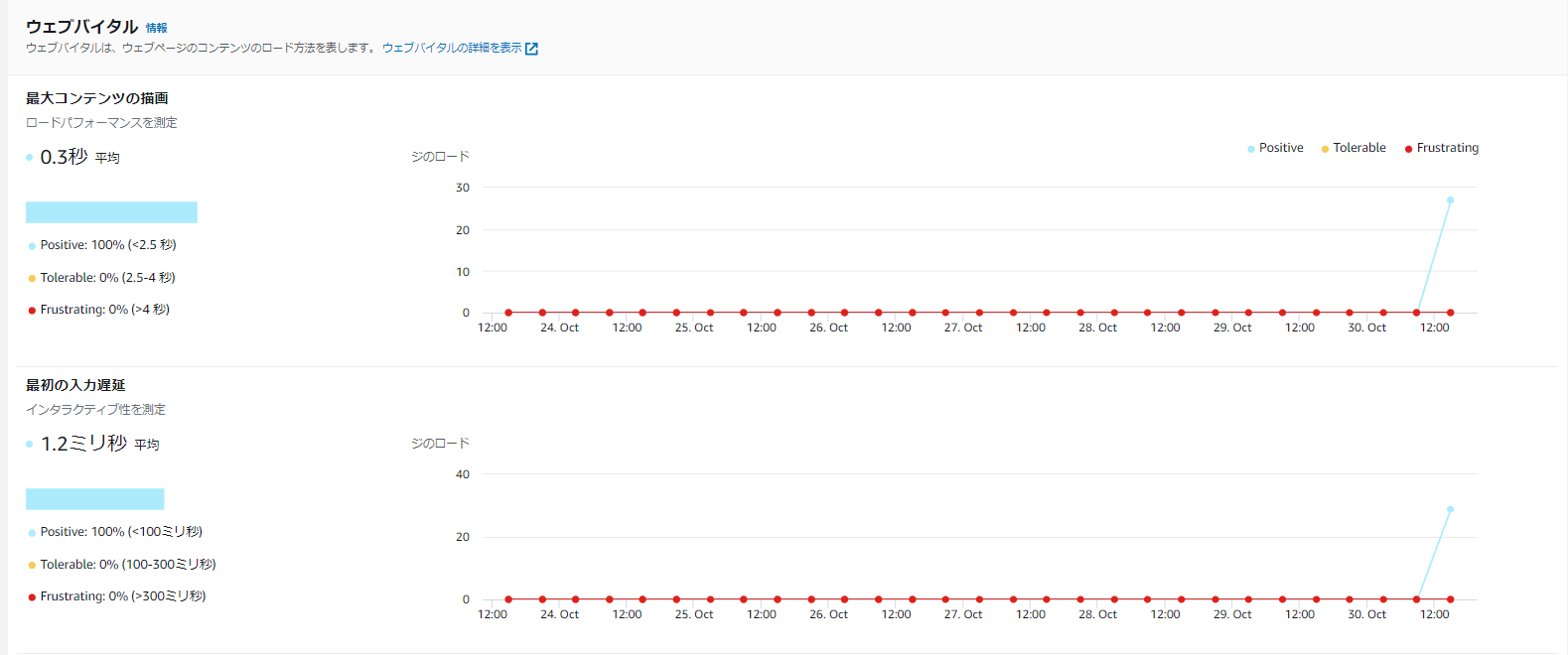
ウェブバイタル
ウェブバイタルは、ページロード全体のユーザーエクスペリエンスの品質を示すパフォーマンス測定値です。

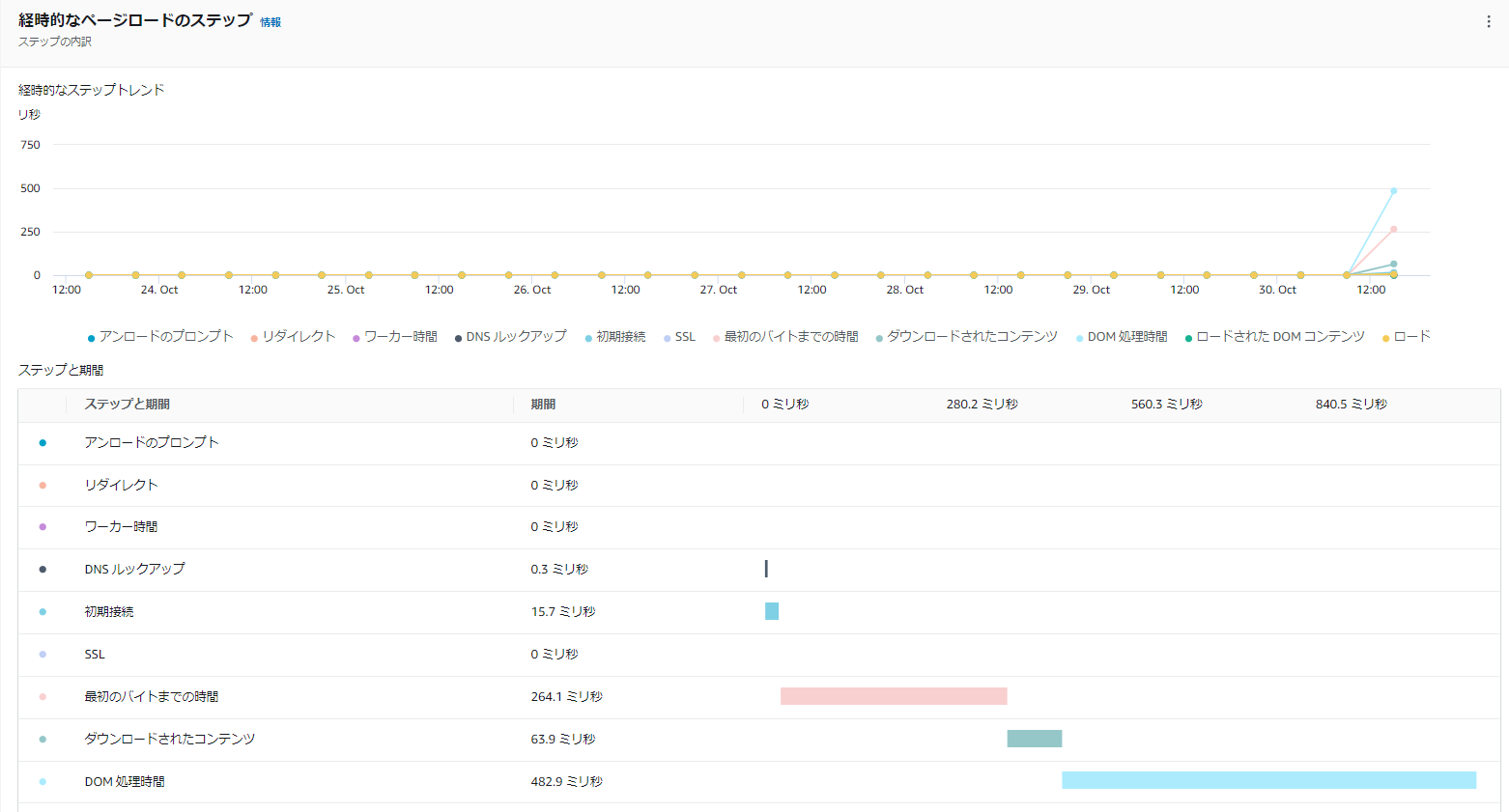
経時的なページロードのステップ
このセクションには、グラフに表示される期間について、ページのロードプロセスの各ステップにかかった平均時間が表示されます。
リクエスト

リソースリクエスト


場所

HTTP リクエスト
エラーが2件あることが確認できます。

セッション情報
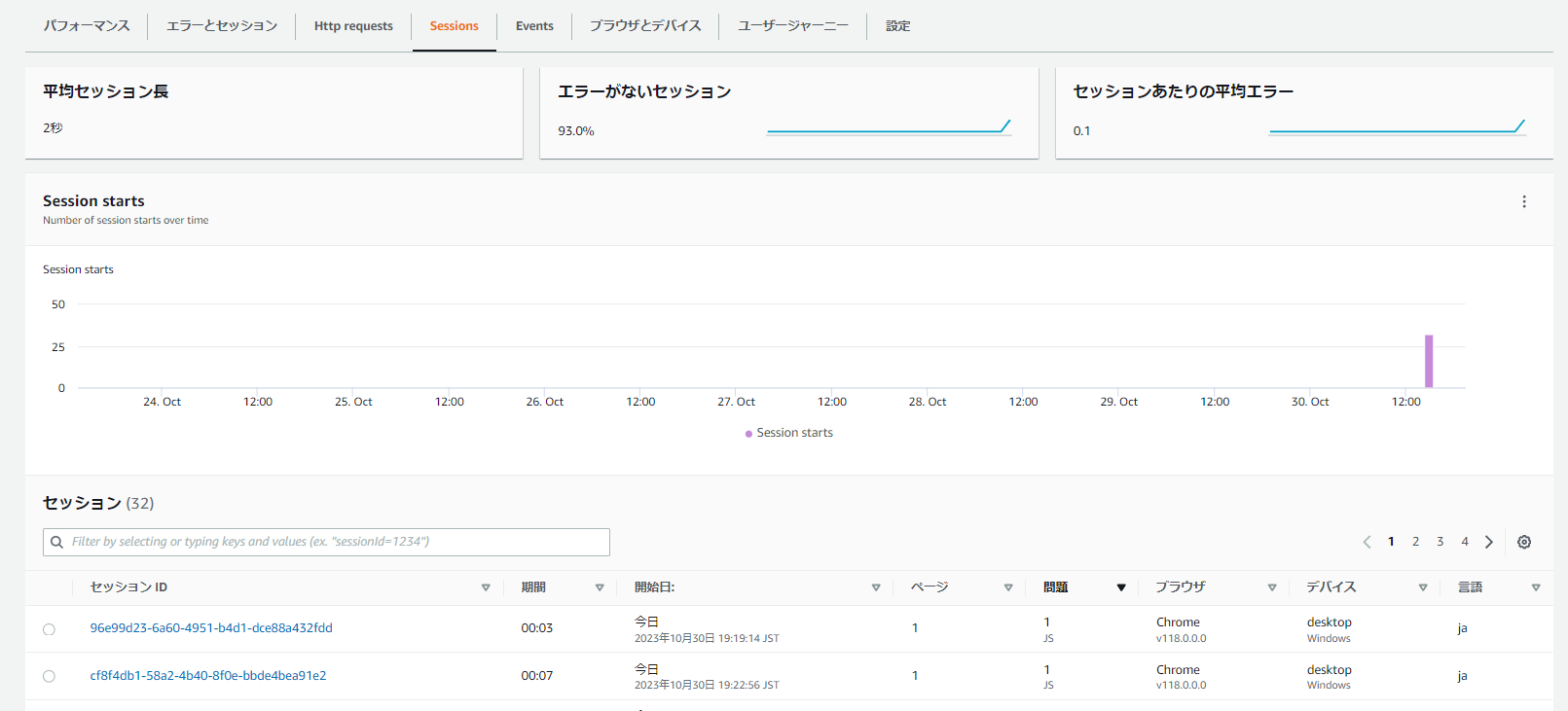
ブラウザ、デバイス情報



終わりに
本当に構築への手間なし監視サービスを触れるいいワークショップだと思います。
X-rayのサービスマップは特に規模が大きくなるとこうなるのかというイメージが湧きました。
オープンソース編はまた時間かけていつかやるかな。。
あと、stack削除で消えていないのはロードバランサー、ECR?、CloudWatchの自分で作った部分、VPC、Lambda(外形監視に使用していたもの)、S3あたりは手で削除しました。