目次
0.結論
1.はじめに
2.前提
3.ホームラン
4.得点圏打率
5.おわりに
大谷選手のホームラン王、本当に嬉しいですね。
怪我さえなければ、大谷選手は来年も活躍してくれると思います。
なぜなら、ホームランは、偶然ではなく、必然だからです。
その当たりのことを、データ分析で考えたいと思います。
なお、データは、選手名に馴染みがある日本のプロ野球のデータを用いました。
0. 結論
ホームランは、ボールを遠くに飛ばす「技術」の結果なので、毎年、似ています。
一方、得点圏打率は、ライナーの有無という「運」の結果なので、毎年、違います。
これらのことを、相関係数を見ることで、データに基づいて考えてみたのが、今回のお題です。
可視化しましたので、グラフで、ホームランと得点圏打率の違いを実感してください。
1. はじめに
「得点圏打率なんて、意味がない」という話を聞いたことがあります。
得点圏打率が良いのは、ヒットを打った時の、ランナーの有無がポイントで、ランナーの有無は、バッターには、関係ない問題だ、ということのようです。
一方、ホームランは、球を遠くに飛ばす技術の結果なので、大谷選手のように、コンスタントにホームランを打てるホームラン・バッターはいるようです。
この当たりの話を、お話として語るのではなく、データ分析して、明らかにしたいと思います。
2. 前提
使用したのは、2022年度と2023年度の日本のプロ野球、セリーグ、パリーグのデータです。
仮説としては「ホームラン・バッターには年度間に相関がある一方、得点圏打率には相関が見られない」と言えるか否かです。
どんな結果になるか、皆さんも考えてみてくださいね。
3. ホームラン
まずは、ホームランから行きましょう。
最初に、セリーグ。
分析に使ったコードは以下の通りです。
import pandas as pd
from adjustText import adjust_text
import matplotlib.pyplot as plt
import japanize_matplotlib
# CSVファイルからデータを読み込む
df_HR_se22 = pd.read_csv('HR_se22.csv')
df_HR_se23 = pd.read_csv('HR_se23.csv')
# データを"Name"列をキーとして左結合する
df = df_HR_se22.merge(df_HR_se23, on=['Name'], how='left')
# 散布図をプロット
fig, ax = plt.subplots()
df.plot.scatter(x='HR_se22', y='HR_se23', ax=ax)
# 各要素にラベルを表示
for k, v in df.iterrows():
ax.annotate(v['Name'], xy=(v['HR_se22'], v['HR_se23']), size=10)
# ラベルの調整
texts = [ax.texts[i] for i in range(len(df))]
adjust_text(texts, arrowprops=dict(arrowstyle='->', color='red'))
# 相関関係を表す線を追加
correlation = df['HR_se22'].corr(df['HR_se23'])
# HR_se22とHR_se23の相関係数を計算
line_x = df['HR_se22']
line_y = correlation * df['HR_se22']
ax.plot(line_x, line_y, color='blue', linestyle='--', label=f'Correlation: {correlation:.2f}')
ax.legend()
# グラフを表示
plt.show()
お待ちかねの結果は、以下の通りです。
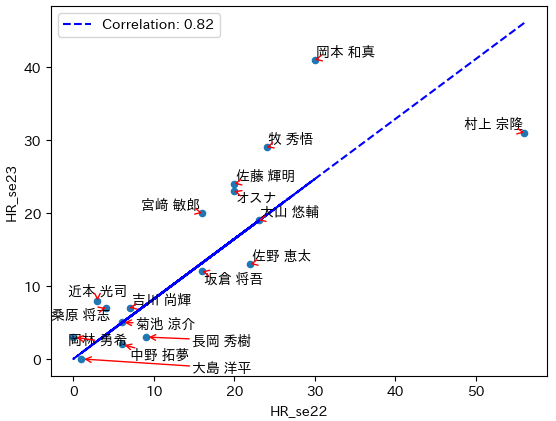
見事なまでに、相関がありますね。相関係数は、0.82。
2022年に三冠王に輝いた村上選手は、2023年は不振と言われましたが、2022年度が良すぎただけで、最終的には30本を超えて、素晴らしい成績だと思います。
次に、パリーグでも見てみましょう。
コードは、先ほどと同じですが、参考までに、載せておきます。
import pandas as pd
from adjustText import adjust_text
import matplotlib.pyplot as plt
import japanize_matplotlib
# CSVファイルからデータを読み込む
df_HR_pa22 = pd.read_csv('HR_pa22.csv')
df_HR_pa23 = pd.read_csv('HR_pa23.csv')
# データを"Name"列をキーとして左結合する
df = df_HR_pa22.merge(df_HR_pa23, on=['Name'], how='left')
# 散布図をプロット
fig, ax = plt.subplots()
df.plot.scatter(x='HR_pa22', y='HR_pa23', ax=ax)
# 各要素にラベルを表示
for k, v in df.iterrows():
ax.annotate(v['Name'], xy=(v['HR_pa22'], v['HR_pa23']), size=10)
# ラベルの調整
texts = [ax.texts[i] for i in range(len(df))]
adjust_text(texts, arrowprops=dict(arrowstyle='->', color='red'))
# 相関関係を表す線を追加
correlation = df['HR_pa22'].corr(df['HR_pa23'])
# HR_pa22とHR_pa23の相関係数を計算
line_x = df['HR_pa22']
line_y = correlation * df['HR_pa22']
ax.plot(line_x, line_y, color='blue', linestyle='--', label=f'Correlation: {correlation:.2f}')
ax.legend()
# 軸の範囲を設定
ax.set_xlim(0, 30)
ax.set_ylim(0, 30)
# グラフを表示
plt.show()
お待ちかねの結果は、以下の通りです。
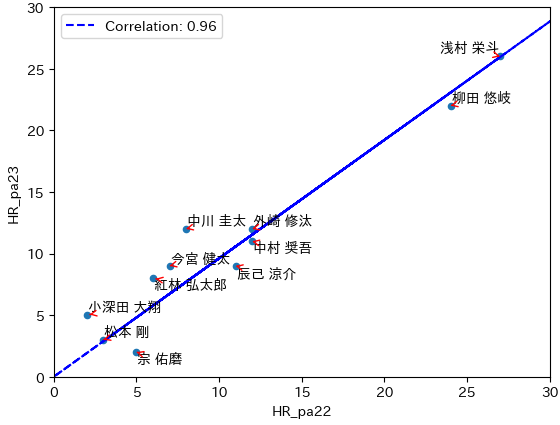
相関係数は、脅威の0.96。正直、こんなに、高いんだと、ビックリ。
ホームランバッターは、毎年、ホームランを打てるんですね、、、(笑)
4. 得点圏打率
それでは、本題の得点圏打率に進みましょう。
まずは、セリーグのデータで見てみましょう。
コードは、以下の通りです。
import pandas as pd
from adjustText import adjust_text
import matplotlib.pyplot as plt
import japanize_matplotlib
# CSVファイルからデータを読み込む
df_CH_se22 = pd.read_csv('CH_se22.csv')
df_CH_se23 = pd.read_csv('CH_se23.csv')
# データを"Name"列をキーとして左結合する
df = df_CH_se22.merge(df_CH_se23, on=['Name'], how='left')
# 散布図をプロット
fig, ax = plt.subplots()
df.plot.scatter(x='CH_se22', y='CH_se23', ax=ax)
# 各要素にラベルを表示
for k, v in df.iterrows():
ax.annotate(v['Name'], xy=(v['CH_se22'], v['CH_se23']), size=10)
# ラベルの調整
texts = [ax.texts[i] for i in range(len(df))]
adjust_text(texts, arrowprops=dict(arrowstyle='->', color='red'))
# 相関関係を表す線を追加
correlation = df['CH_se22'].corr(df['CH_se23'])
# CH_se22とCH_se23の相関係数を計算
line_x = df['CH_se22']
line_y = correlation * df['CH_se22']
ax.plot(line_x, line_y, color='blue', linestyle='--', label=f'Correlation: {correlation:.2f}')
# 横軸と縦軸の範囲を設定
ax.set_xlim(0.17, ax.get_xlim()[1]) # 横軸の範囲を設定
ax.set_ylim(0.17, ax.get_ylim()[1]) # 縦軸の範囲を設定
# 凡例の位置を左上に設定
ax.legend(loc='upper left')
# グラフを表示
plt.show()
相関が有るのでしょうか?無いのでしょうか?
結果は、以下の通りです。
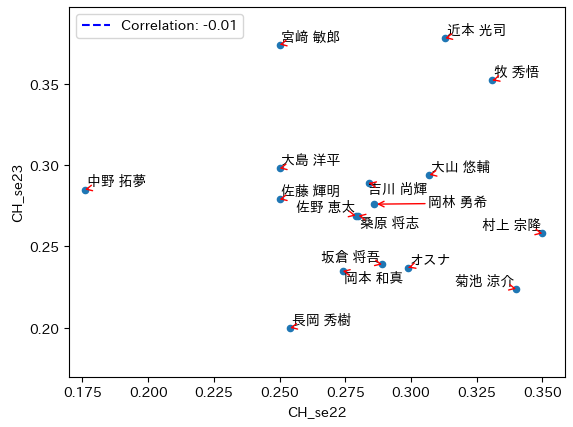
相関係数は、-0.01。まったく、相関は無いですね!
ホームランと違って、相関の線は引けません。悪しからず、ご容赦ください(笑)
念のため、パリーグのデータでも、見てみましょう。
コードは、基本、同じですが、参考までに、載せておきます。
import pandas as pd
from adjustText import adjust_text
import matplotlib.pyplot as plt
import japanize_matplotlib
# CSVファイルからデータを読み込む
df_CH_pa22 = pd.read_csv('CH_pa22.csv')
df_CH_pa23 = pd.read_csv('CH_pa23.csv')
# データを"Name"列をキーとして左結合する
df = df_CH_pa22.merge(df_CH_pa23, on=['Name'], how='left')
# 散布図をプロット
fig, ax = plt.subplots()
df.plot.scatter(x='CH_pa22', y='CH_pa23', ax=ax)
# 各要素にラベルを表示
for k, v in df.iterrows():
ax.annotate(v['Name'], xy=(v['CH_pa22'], v['CH_pa23']), size=10)
# ラベルの調整
texts = [ax.texts[i] for i in range(len(df))]
adjust_text(texts, arrowprops=dict(arrowstyle='->', color='red'))
# 相関関係を表す線を追加
correlation = df['CH_pa22'].corr(df['CH_pa23'])
# CH_pa22とCH_pa23の相関係数を計算
line_x = df['CH_pa22']
line_y = correlation * df['CH_pa22']
ax.plot(line_x, line_y, color='blue', linestyle='--', label=f'Correlation: {correlation:.2f}')
# 横軸と縦軸の範囲を設定
ax.set_xlim(0.2, ax.get_xlim()[1]) # 横軸の範囲を設定
ax.set_ylim(0.2, ax.get_ylim()[1]) # 縦軸の範囲を設定
# 凡例の位置を左上に設定
ax.legend(loc='upper right')
# グラフを表示
plt.show()
パリーグでも、相関は無いのでしょうか?
結果は、以下の通りです。
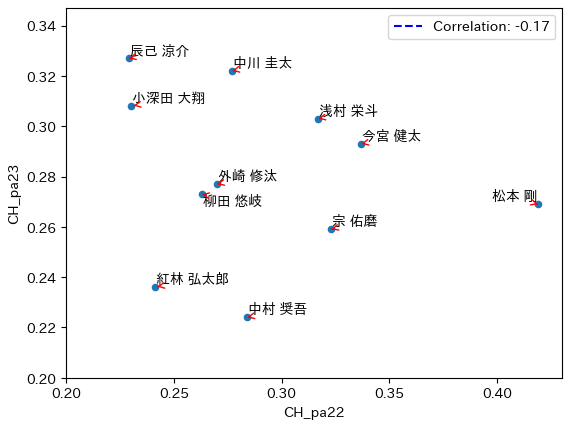
相関係数は、-0.17。やはり、相関関係は、見られないですね。
5. おわりに
ということで、やっぱり、得点圏打率は運次第ということのようですね(笑)
そのことを、データを使って、ちゃんと証明できて良かったと思います。
この手の分析は、やはり、野球の本場のアメリカが進んでいます。
セイバーメトリクスという分野が確立しています。
セイバーメトリクス
セイバーメトリクス(Sabermetrics)は、野球の統計データを用いて選手やチームのパフォーマンスを評価・分析する方法論やアプローチを指します。セイバーメトリクスは主にアメリカの野球解析者ビル・ジェームズによって提唱され、以後に他の研究者やアナリストによって発展・拡充されてきました。
以下に、セイバーメトリクスの主要な要点を説明します。
-
伝統的な統計との違い
- 伝統的な野球の統計(例: 打率、勝利数、打点など)に対し、セイバーメトリクスはより詳細な情報を扱います。
- 例えば、得点圏打率、OPS(出塁率+長打率)、WAR(勝利のための代表的な指標)などがセイバーメトリクスの代表的な指標です。
-
プレーの詳細な分析
- セイバーメトリクスは、個々のプレーを詳細に分析します。例えば、打者の球種ごとの対応、守備位置の選手の移動パターンなどを考慮します。
-
運の要素の排除
- 一つの例は「運」の要素をできるだけ排除しようとする点です。例えば、ヒットが出るかどうかは時折運の要素も含みますが、選手の打球の傾向や質を分析することで、その影響を最小限に抑えようとします。今回の分析は、この分野に関係します。
-
チーム戦略の最適化
- セイバーメトリクスは、チームの戦略や戦術の最適化を目指します。例えば、どの打順に選手を配置するか、どのような投手を起用するかなどをデータに基づいて考えます。
-
進化と継続的な研究
- セイバーメトリクスは進化する分野であり、新しい統計指標やアプローチが継続的に開発されています。新たな技術やデータ解析の手法が取り入れられています。
セイバーメトリクスは、野球の分析や戦術において非常に重要な役割を果たしており、プロチームやアマチュアチーム、アナリストなどが活用しています。
最後に、この記事が野球好きの方の参考になれば、嬉しいです!