目次
1.はじめに
2.分析の流れ
3.コード例
4.クラスタリング結果
5.おわりに
1. はじめに
K平均法は、データを似ているもの同士でグループ分けする手法です。
今回は、英語と数学の点数を使って、生徒たちをクラスタリングする例を考えてみましょう。
名前の由来
K平均法(K-means clustering)の名前は、このクラスタリングアルゴリズムの基本的な動作に由来しています。
「K」はクラスタの数を表し、事前に指定されるパラメータです。アルゴリズムは、与えられたデータをK個のクラスタに分割することを目的としています。
「平均法(means)」は、各クラスタの中心を計算する方法を指します。具体的には、各データ点とクラスタの中心点との間の距離を計算し、各データ点を最も近い中心点に割り当てます。その後、各クラスタの中心を再計算します。このプロセスは、各データ点が最も近い中心に所属するまで繰り返されます。
このようにして、クラスタの中心が最適化され、データが効果的にクラスタに分割されます。
K平均法は、データをクラスタに分割する際に「平均」を用いることからこの名前が付けられました。
2. 分析の流れ
-
データの準備:
最初に、各生徒の英語と数学の点数を集めます。例えば、A君が英語で80点、数学で70点、B君が英語で60点、数学で75点、というように。 -
クラスター数の選定:
K平均法では、最初にいくつかのクラスター(グループ)を決める必要があります。例えば、3つのクラスターに分ける場合、K=3とします。 -
ランダムなクラスターの設定:
最初はランダムに各生徒を3つのクラスターに割り当てます。 -
各生徒を最も近いクラスターに割り当てる:
各生徒ごとに、英語と数学の点数から最も近いクラスターを選びます。例えば、A君が所属するクラスターが1番、B君が所属するクラスターが2番、というように。 -
クラスターの中心を再計算:
各クラスター内の生徒の平均点数を計算し、それを新しいクラスターの中心とします。 -
繰り返し:
ステップ4と5を繰り返します。つまり、各生徒を最も近いクラスターに割り当て、クラスターの中心を更新します。 -
クラスターが変わらなくなるまで繰り返す:
クラスターの中心が変わらなくなるまで、ステップ4と5を繰り返します。 -
最終的なクラスタリングの確認:
最終的に、各生徒がどのクラスターに属するかが決まります。
例えば、3つのクラスターに分けた場合、それぞれのクラスターが、例えば「英語が得意、数学が苦手」「英語も数学もバランスが取れている」「英語は苦手、数学が得意」といったようになるかもしれません。
3. コード例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# 15人分のダミーデータを作成
np.random.seed(0)
english_scores = np.random.randint(0, 101, 15)
math_scores = np.random.randint(0, 101, 15)
# データを合体させる
data = np.column_stack((english_scores, math_scores))
# K平均法を用いてクラスタリング
kmeans = KMeans(n_clusters=3, random_state=0).fit(data)
# クラスタリングの結果をプロット
plt.figure(figsize=(8, 6))
# クラスターごとに色を指定
colors = ['red', 'blue', 'green']
for i in range(3):
plt.scatter(data[kmeans.labels_ == i, 0], data[kmeans.labels_ == i, 1], c=colors[i], label=f'Cluster {i+1}')
# プロットの設定
plt.xlabel('English Score')
plt.ylabel('Math Score')
plt.title('Clustering of Students based on English and Math Scores')
plt.legend()
plt.grid(True)
# プロットを表示
plt.show()
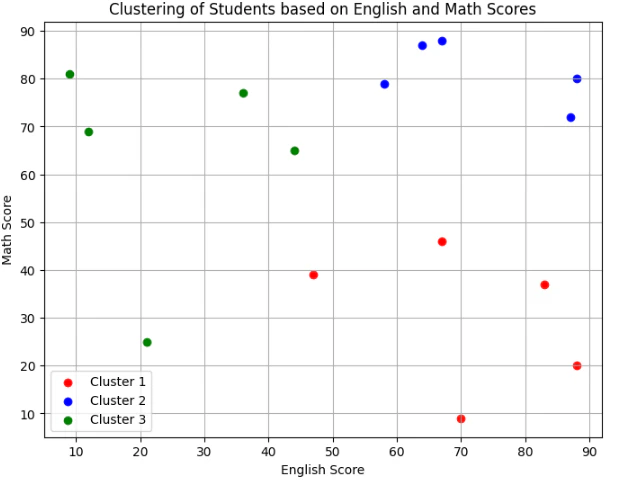
4. クラスタリング結果
5. おわりに
いかがでしたか?
クラスタリングを見ると、右上に、英語も数学も出来る「医学部コース」に相応しいような生徒がプロットされます。
右下には、数学は、イマイチだけど、英語が出来る「文系コース」が相応しいような生徒がプロットされます。
そして、左側には、数学が良くできる「理系コース」が相応しい生徒がプロットされます。
本人の意欲が、一番、大切だと思いますが、客観的に可視化できるのが、K平均法の良い点ですね。
K平均法とK近傍法
K平均法(K-means clustering)と似た名前の手法に、K近傍法(K-nearest neighbors)があります。
K平均法はクラスタリングの手法であり、K近傍法は分類の手法です。
K平均法は与えられたデータをグループに分けるのに対し、K近傍法は新しいデータポイントを既知のクラスに分類します。
両方とも機械学習やデータマイニングの分野で使われる手法ですが、それぞれ異なる目的とアプローチを持っています。
-
目的:
-
K平均法は、与えられたデータをK個のクラスタに分割することを目的とします。各クラスタは類似した特性を持つデータポイントの集まりで、クラスタの中心点が最適化されます。
-
K近傍法は、与えられたデータポイントを分類する際に、その周囲の最も近いK個の隣接データポイントの多数決で分類を決定します。主に分類問題に使用されます。
-
-
利用される場面:
-
K平均法は、クラスタリングやセグメンテーションのために使用されます。例えば、顧客を購買傾向に基づいてグループ分けしたり、画像のセグメンテーション(物体を検出する)に使われます。
-
K近傍法は、主に分類問題に適用されます。例えば、手書き数字の認識やスパムメールのフィルタリングなどがあります。
-
-
アプローチ:
-
K平均法では、事前にクラスタの数Kを指定し、データポイントをK個のクラスタに割り当てます。これは反復的なプロセスで、各反復ごとにクラスタの中心が再計算されます。
-
K近傍法では、新しいデータポイントが与えられた際に、それに最も近いK個のトレーニングデータポイントを見つけ、多数決でそのデータポイントを分類します。
-
-
適用範囲:
-
K平均法は数値データや特徴量が数値で表現できる場合に使われます。例えば、数値データを持つ顧客セグメンテーションや画像ピクセルのクラスタリングなどがあります。
-
K近傍法は、主に分類問題に使われ、特徴量の種類に制約はありません。例えば、テキスト分類や画像分類などがあります。
-