目次
1.はじめに
2.方針
3.留意点
4.コードの紹介
5.おわりに
1. はじめに
大きな会社になると、社内ルールは複雑です。
周りの人に聞きたいけど、忙しそうにしているので、聞きにくいなんて感じたりもします。
そんな時を想定して、ChatGPTに社内ルールを読み込ませて、問い合わせに回答させたいです。
今回は、そんな悩みを解決するプログラムです。
架空の休暇申請手続きに関するガイドラインに基づき、休暇申請に係る問い合わせにChatGPTに答えてもらうことにしました。
2. 方針
2-1.LangChain
ChatGPTを使いますが、ChatGPTを有効活用するため、LangChainを使用します。
社内ルールをPDFとして読み込むケースでは、LlamaIndexの利用も併せて、検討した方が良いかもしれません。
LangChainとは
ChatGPTなどの大規模言語モデルの機能を拡張できるライブラリです。
LangChainを利用すれば、長文のプロンプトの送信や、回答する内容に最新の情報を含めることができます。
2-2.Streamlit
ユーザインターフェイスには、Streamlitを使用します。
Streamlitとは
Streamlitは、データサイエンティストや開発者がデータを簡単に可視化するためのPythonベースのオープンソースライブラリです。
Streamlitを使用することで、ウェブアプリケーションを作成し、データの探索、分析、可視化を効果的に行うことができます。
3. 留意点
3-1.Openai API
OpenAIのAPIを使います。無料枠もありますが、基本は有料です。
APIキーは、別ファイル(.env)に保存しています。
3-2.GPT Model
社内ルールをPDFファイルとして読み込んで対応する場合は、GPT-3.5-turboモデルの代わりにGPT-3.5-turbo-16kモデルを使用した方が、良いかもしれません。
GPT-3.5-turboモデルは4,096トークンの制限があり、PDFの内容を完全に処理することができない可能性があります。
GPT-3.5-turbo-16kモデルは16,384トークンまで、OKです。
もちろん、GPT-4の利用もありですが、課金も考慮する必要があります(笑)
4. コードの紹介
最初に、ライブラリのインストールを、お願いします。
各コードの内容については、コメントを参照してください。
import streamlit as st
from streamlit_chat import message
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
)
from dotenv import load_dotenv
# 環境変数の読み込み
load_dotenv()
# チャットの初期テンプレート
template = """
あなたは、社内ルールに精通した専門家です。
以下のガイドラインに基づき、質問者からの問い合わせに、なるべく、優しく、具体的に回答してください。
休暇申請手続きに関するガイドライン
有給休暇:年間15日まで取得可能
特別休暇(慶弔休暇、介護休暇など):年間5日まで取得可能
夏季休暇・冬季休暇:各5日まで取得可能
休暇申請手続き
休暇取得希望日の前日までに申請が必要です。
例外的なケースにおいては、できるだけ早く上長と調整の上、申請してください。
休暇申請手順
休暇希望期間を含む休暇申請書を人事部に提出してください。
休暇の種類(有給休暇、特別休暇など)
休暇希望期間(開始日と終了日)
代わりになる社員(必要な場合)
休暇が承認された場合、人事部より確認通知が送られます。
以上に基づいて、問い合わせに回答してください。
"""
# チャットのプロンプト設定
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(template),
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}"),
])
# 対話のキャッシュをロードする関数
@st.cache_resource
def load_conversation():
llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0
)
memory = ConversationBufferMemory(return_messages=True)
conversation = ConversationChain(
memory=memory,
prompt=prompt,
llm=llm)
return conversation
# Streamlit セッションの初期化
if "generated" not in st.session_state:
st.session_state.generated = []
if "past" not in st.session_state:
st.session_state.past = []
# ユーザーが入力を変更したときの処理
def on_input_change():
user_message = st.session_state.user_message
conversation = load_conversation()
answer = conversation.predict(input=user_message)
# 生成された回答と過去のメッセージを保存
st.session_state.generated.append(answer)
st.session_state.past.append(user_message)
# ユーザーの入力をクリア
st.session_state.user_message = ""
# Streamlit アプリのタイトルと説明文
st.title("お助けロボット")
st.write("休暇申請に対する問い合わせに回答します!")
# チャットの表示エリアの作成
chat_placeholder = st.empty()
with chat_placeholder.container():
# 過去のメッセージと生成された回答を表示
for past, generated in zip(st.session_state.past, st.session_state.generated):
message(past, is_user=True)
message(generated)
# ユーザーからの入力を受け付けるエリア
with st.container():
user_message = st.text_input("問い合わせを入力してください!", key="user_message")
st.button("問い合わせを送る", on_click=on_input_change)
コードを実行するには、ターミナルで、以下のコードを実行します。
streamlit run app.py
5. おわりに
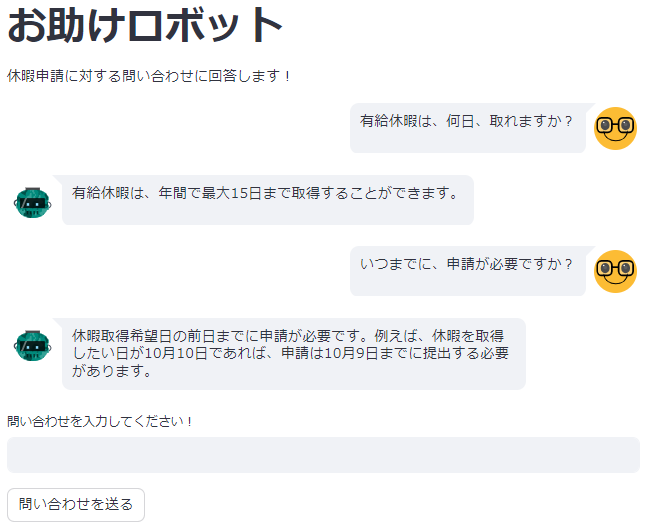
上記を実行し、簡単なQAをした結果は、以下の通りです。
驚くべきは!
驚くべきは、以下の2点です。
1.具体的に、優しく
コードを見てもらえば分かる通り、社内ルールでは、
「休暇取得希望日の前日までに申請が必要です」と定められています。
一方、ChatGPTの回答では、正確な答えを返した上に、
①冒頭に貼り付けた例では、「例えば、休暇を取得したい日が10月10日であれば、申請は10月9日までに提出する必要があります」と、具体例が盛り込まれています。
また、②この直前に付けた例では、「できるだけ早めに申請することをおすすめします」とアドバイスが加えられています。
これはプロンプトに「以下のガイドラインに基づき、質問者からの問い合わせに、なるべく、優しく、具体的に回答してください」と、指示したためであると考えられます。
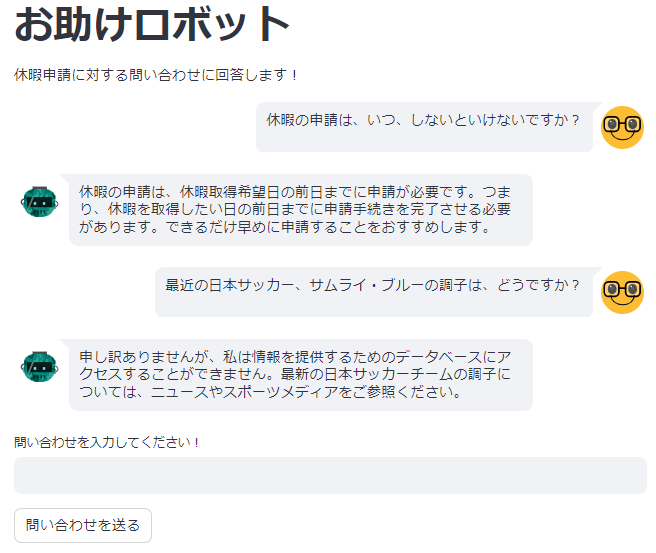
2.関係ないことは答えない
この直前に付けた例では、「最近の日本サッカー、サムライ・ブルーの調子は、どうですか?」と、休暇申請とは関係のないことを聞いてみました。
その結果は、ハルシネーション(Hallucination、人工知能(AI)が事実に基づかない情報を生成する現象)とはならず、「申し訳ありませんが、私は情報を提供するためのデータベースにアクセスすることができません。最新の日本サッカーチームの調子については、ニュースやスポーツメディアをご参照ください。」と、至極まともな結果が返ってきました。
恐るべし、ChatGPTです。
どなたかのご参考になれば、幸いです。