背景
最近,armancohan/long-summarizationで公開されている二つのデータセット(pubmed, arxiv)を使用して学術論文要約タスクに取り組んでいます.
モデルはPointer-Generatorを元にしたもの(PyTorch実装)で,訓練はGoogle Colaboratoryで行っています.
Pointer-Generatorの元論文では,下記条件のもとで
- バッチサイズ: 16
- 230,000イテレーション
- Bi-LSTM隠れ層の次元: 256
- 単語埋め込み次元: 128
- カバレッジ機構なし
- Tesla K40m GPU
3日と4時間かかったと記述されていますので,1イテレーションは大体1.2秒であることがわかります.
また,今回のデータセットを作成した論文では,
- バッチサイズ: 16
- 10エポック
- 訓練データは11万件程度なので,1エポック6,875イテレーション程度
- Bi-LSTM隠れ層の次元: 256
- 単語埋め込み次元: 128
- NVIDIA Titan X Pascal GPUs
の条件で,1イテレーション3.2秒とのことでした.Pointer-Generatorより複雑のモデルなので時間がかかっています.
私はatulkum/pointer_summarizerを参考に,元のPointer-Generatorに手を加えた物を実装しました.
元のPointer-Generator(語彙50k)ではパラメタ数は21,499,600+1153個でしたが,私の実装したモデル(語彙30k)のパラメタ数は24,322,354ですので,そんなに変わらないかと思います.
しかし,実際にGoogle Colaboratoryで訓練したところ,1イテレーションに手元の電波時計で10秒程かかってしまいました.単純に比較はできないですが,こんなに遅いことがあるのかと目を疑いました.
原因
タイトルの通りGoogle Driveにアクセスしていたことが原因です.
前提としてarmancohan/long-summarizationで公開されているzipファイルを解凍すると下記のように展開されます(pubmedの場合).
pubmed-dataset
┣ test.txt
┣ train.txt
┣ val.txt
┗ vocab
train.txtは4GBほどのファイルなので,これらをメモリに展開するのは厳しいと思い,1つのデータに対して前処理を施してから,1つのjsonファイルにしてGoogle Driveに保存することにしました.ColaboratoryのFAQによると(強調は筆者によるもの),
drive.mount() が失敗して「タイムアウト」と表示されることがあるのはどうしてですか?また、drive.mount() でマウントしたフォルダでの I/O オペレーションが失敗することがあるのはどうしてですか?
Google ドライブのオペレーションは、***フォルダ内のファイル数やサブフォルダ数が増えすぎるとタイムアウトすることがあります。***数千件ものアイテムが最上位の「マイドライブ」フォルダの直下にあると、ドライブのマウント処理がタイムアウトする可能性が高くなります。マウントを繰り返し試みると最終的に成功することがあります。これは、タイムアウトするまで、失敗するたびに部分的な状態がローカルのキャッシュに保存されるためです。この問題が発生した場合は、「マイドライブ」の直下にあるファイルやフォルダをサブフォルダに移動してみてください。drive.mount() が正常終了した後で他のフォルダから読み取りを行うと、同様の問題が発生することがあります。多くのアイテムが含まれているフォルダ内のアイテムにアクセスすると、OSError: [Errno 5] Input/output error(python 3)または IOError: [Errno 5] Input/output error(python 2)のようなエラーが発生することがあります。この問題も同様に、直下にあるアイテムをサブフォルダに移動することで解決できます。
注: ファイルやサブフォルダをゴミ箱に移動して「削除」するだけでは、この問題を解決できないことがあります。この方法で解決できない場合は、ゴミ箱を空にしてください。
とのことで,実際110,000件程度のデータを1つのディレクトリに配置した際にタイムアウトしたので,下記のように3000件ずつサブディレクトリに配置するようにしました.
pubmed
┣ test
┃ ┣ 0
┃ ┃ ┣ 0.json
┃ ┃ .
┃ ┃ ┗ 2999.json
┃ ┣ 1
┃ .
┣ train
┗ val
atulkum/pointer_summarizerでは,data_util/batcher.pyでQueueやマルチスレッドを使ってファイルを読み込んでいるようですが,よくわからないのでPyTorchのDatasetとDataLoaderを使うことにしました.私の実装したDatasetを簡略化して記載します.
class MyDataset(torch.utils.data.Dataset):
def __init__(self, base_dir):
self.base_dir = base_dir
self.files = self.get_file_paths()
def get_file_paths(self):
# 数字順でファイルをソート
#p = re.compile(r'\d+') # ←Qiitaのシンタックスハイライトで色がおかしくなってしまうのでコメントアウト
data_dirs = sorted(glob.glob(f'{self.base_dir}/*'),
key=lambda s: int(p.findall(s)[-1]))
files = []
for file in data_dirs:
files.extend(sorted(glob.glob(f'{file}/*'),
key=lambda s: int(p.findall(s)[-1])))
return files
def __len__(self):
return len(self.files)
def __getitem__(self, index):
with open(self.files[index]) as f:
article_dict = json.load(f)
return article_dict
このデータセットをDataLoaderで読み込んで
train_iter = DataLoader(MyDataset('./drive/My Drive/pubmed/train'), batch_size=16)
下記のように訓練を回します.
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
print(len(train_iter))
for batch in train_iter:
start.record()
optimizer.zero_grad()
# 省略
optimizer.step()
end.record()
torch.cuda.synchronize()
print(f'process: {start.elapsed_time(end)}')
時間の測り方はこちらを参考にしました.
この実行結果は下記のようになります.
GPUはTesla T4です.

単位はミリ秒ですから,大体2秒程度でしょうか.GPUが新しいだけあって速いですね(K80では4秒程度でした).
問題なのは,1イテレーションは2秒程度なのに現実では10秒弱経過していることです.
「Google Colab is very slow compared to my PC」という記事を見つけまして,どうやらGoogle Driveにアクセスしているのがボトルネックだとわかりました.
ということでMyDatasetクラスの__getitem__メソッドを下記のように変更した際の結果を示します.
def __getitem__(self, index):
start = time.time()
with open(self.files[index]) as f:
article_dict = json.load(f)
end = time.time()
print(f'getitem: {end - start}')
return article_dict

このようにファイル読み込みで大体0.3から0.5秒程かかっていることがわかりました.バッチサイズは16ですので,0.4秒とすればファイル読み込みだけで6.4秒かかっていることになります.
ここで訓練をもう一度行ってみると...

ファイル読み込みが速くなっています.キャッシュされているんですかね.
試しに,Google Driveに保存したデータをcpコマンドでコピーしようとしましたが,ファイル数が多く途方もない時間がかかりそうだったのでやめました.
代わりにjsonファイルの保存先をColabのcontent直下にして再生成し,実行した結果を載せます.
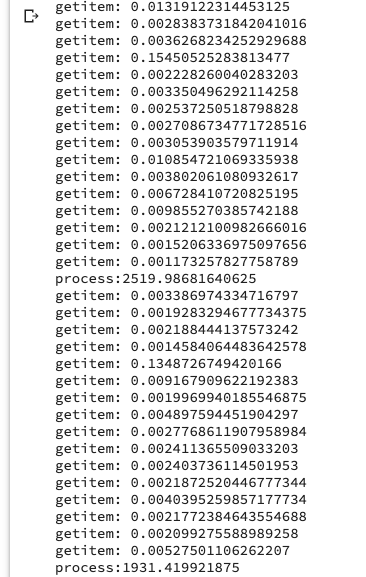
ランタイムをリセットしてから初めての訓練ですが,ファイル読み込みが速くなっているのがわかります.
まとめ
Datasetクラスの__getitem__でGoogle Driveに保存したデータを1つずつ読み込む場合,ランタイムに直接データを保存して読み込む場合に比べて初回は100倍ほど遅いことがわかりました.
ただ,2回目以降の読み込みはキャッシュされて速くなるようなので,2エポック目以降は速くなるはずですし,そもそもGoogle Driveにファイルをおかないようにしたりして工夫すれば影響は少ないはずです.
画像処理なんかだと今回の例のように複数のファイルに保存して扱っているのをみたことがありますが,どのように対処しているんでしょうか.
Google Driveへのアクセスに時間がかかることも,ファイルをいちいち開けるのに時間がかかることもわかりきったことですが,実際にこうなるとびっくりします.
今回おこったことはデータセットのサイズや形式によるところが大きいと思うので,他にこのような事例にでくわす方がいるかわかりませんが,どなたかの参考になれば嬉しいです.
おまけ:別の方法
今回は大きなファイルを,複数のファイルに分割しました.
少し調べてみるとtorch.utils.data.IterableDatasetというものがあり,メモリに乗らないようなデータを扱うのに向いているらしいです.
公式の例がわかりづらく感じたのですが,How to Build a Streaming DataLoader with PyTorchという記事を参考に実装しました.数イテレーション回しましたが,特に問題なく動きました.ただ,理解が足りていないため詳しい説明ができませんので,ソースコードを貼って参考程度にしていただけれればと思います.
私の場合,前処理をして13万のファイルを生成するのに一時間以上かかっていたのですが,このIterableDatasetで同様の前処理(下記process_data)をしても1イテレーションの実行時間にはあまり影響していないように感じました.今回のケースはIterableDatasetを使う場面なのかもしれません.
ただ,Google Driveで大きなファイルを読み込んでいると
OSError: [Errno 5] Input/output error
が出ることがあるので,contentディレクトリ直下にファイルを配置して読み込んだほうがいいと思います.
もう少し勉強して,理解できたら投稿しようかと思います.
class MyIterableDataset(torch.utils.data.IterableDataset):
def __init__(self, file):
self.file = file
def get_one_data(self):
with open(self.file) as lines:
for line in lines:
data = self.process_data(json.loads(line))
yield data
def process_data(self, data):
# 前処理
train_iter = DataLoader(MyIterableDataset('./pubmed-dataset/train.txt'), batch_size=16)
for batch in train_iter:
# モデルの処理