こんにちは、k_ukiです。
「AWSではじめるクラウド開発入門」の10章と11章を進めていきました。
そこでは、サーバーレスクラウドに関連する技術が取り上げられており、「Lambda」「DynamoDB」「S3」の3つの技術をハンズオン形式で学習しました。
その中でも、今回は「DynamoDB」について学んだことをまとめていきます。
「DynamoDB」とは?
DynamoDBはAWSが提供するサーバーレスなデータベースのことです。
こちらの記事ではサーバーレスコンピューティングについての説明を行いました。データベースにもこの概念を適用することができます。"DynamoDB"を使用することで、データベース用の仮想インスタンス等を構築せずとも、データの書き込み、読み出し等が行えます。
DynamoDBとの通信はAPIを通じて行われます。また、保存領域の上限は設定されていないため、データを格納した分だけ領域も拡張されていきます。
DynamoDBを触ってみた
今回のハンズオンではSTEP1,STEP2の二つを実施しました。それぞれの内容は以下の通りです。
- STEP1: AWS CDKを使用し、DynamoDBの初期化、デプロイを行う。
- STEP2: APIを使用して、データの書き込み、読み出し、削除を行ってみる
STEP1
STEP1ではPythonのコードをLambdaに登録する作業を行いました。
まず、プロジェクトのディレクトリに移動し以下のコマンドを実行しました。
# venvを作成し、依存ライブラリのインストール
$ python3 -m venv .env
$ source .env/bin/activate
$ pip install -r requirements.txt
# デプロイの実行
$ cdk deploy
実行後、以下の文字列が返されました。正しくデプロイできたことがわかります。

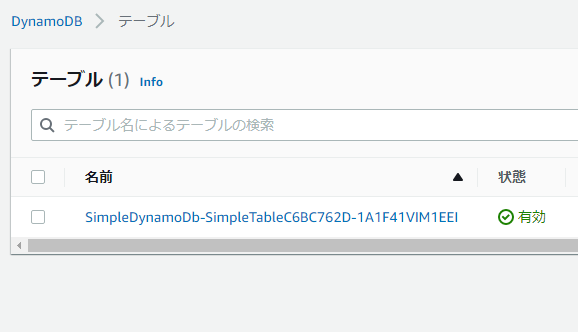
AWSコンソールにアクセスし、DynamoDb>テーブルの順に遷移していくと、テーブルが正しく生成されたことが確認できました。
STEP2
STEP2ではSTEP1で作ったテーブルにデータの書きこみ、読み出しを行ってみます。
データの書き込み
まずは、データの書き込みを実践してみます。ここではハンズオンで用意されていた"simple_write.py"を使用します。コードは以下の通りです。
# boto3をインポートしdynamodbを呼び出す
import boto3
from uuid import uuid4
ddb = boto3.resource('dynamodb')
def write_item(table_name):
table = ddb.Table(table_name)
table.put_item(
Item={
'item_id': str(uuid4()),
'first_name': 'John',
'last_name' : 'Doe',
'age':25,
}
)
上から3行は、boto3(AWSをpythonで操作するためのライブラリ)をインポートしDynamoDBを呼び出しています。
write_item関数ではデプロイしたテーブルの名前を引数として受け取りput_item()メソッドを使用することで新しいタプルをDBに書き込みます。
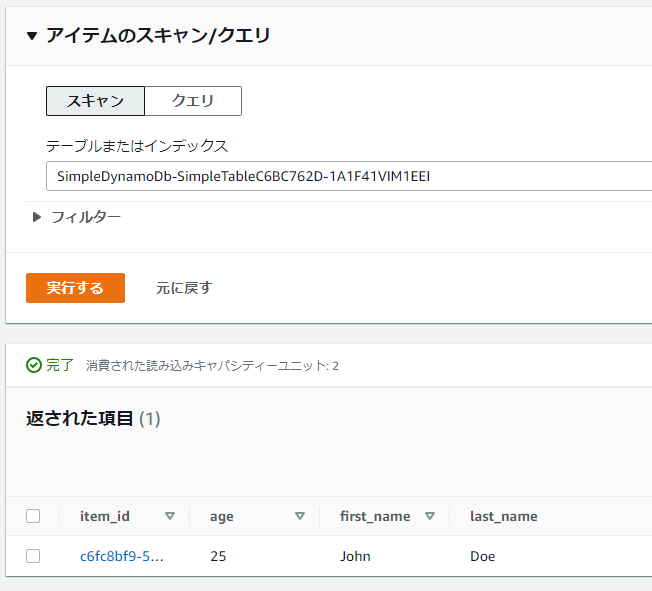
このファイルを実行後コンソールを確認してみると先ほど登録した情報が保存されたことが確認できました。
データの読み込み
次にDBにあるデータの読み出しを行います。読み出しのために使用するファイルのコードは以下の通りです。
import boto3
ddb = boto3.resource('dynamodb')
def scan_table(table_name):
table = ddb.Table(table_name)
items = table.scan().get("Items")
print(items)
table.scan().get("items")でテーブルの中身を全て呼び出します。
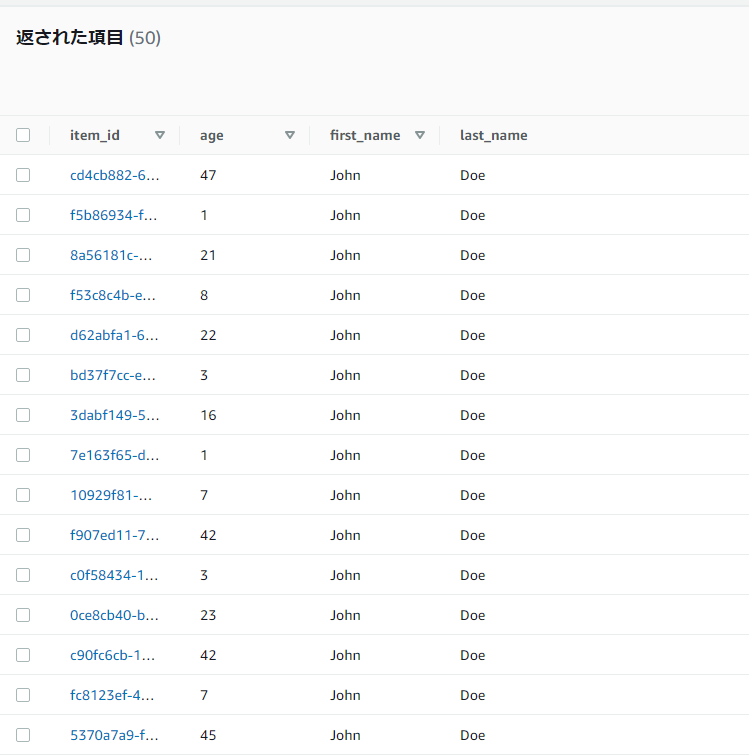
ファイルの実行後以下の結果が得られました。先ほど登録したデータが読みだされたことが分かります。

大量のファイルの読み書き
用意されているbatch_rw.pyを実行します。今回は1000個のデータを書き込んでみます。
python batch_rw.py テーブル名 write 1000
実行後コンソール確認したところデータがきちんと複数書き込まれていました。
スタックの削除
演習は完了なので以下のコマンドでスタックを削除しました
$ cdk destroy
最後に
今回はDynamoDBを用いたデータの読み書きを実践しました。今回の学習でDynamoDBが何か、実際にどう読み書きを行うのかを体験し学ぶことができました。