こんにちは、k_ukiです。現在「AWSではじめるクラウド開発入門」という書籍の13章を進めています。
この章では、PythonからAWS APIを操作するためのライブラリ「boto3」の理解を「S3,DynamoDB」のハンズオンで深めていくということを行いました。その中でも今回は「DynamoDB」のハンズオンで学んだことをまとめていきます。
概要
- 空のテーブルをDynamoDBに作成
- 【LEVEL1】基本的なデータの読み書きを実践してみる。
- 【LEVEL2】QueryとScanを使ってみる。
- 【LEVEL3】テーブルのバックアップを取る。
空のテーブルをDynamoDBに作成
まずはプロジェクトのディレクトリに移動し依存ライブラリのインストールを行います。
以下のコマンドを入力します。また、インストール完了後デプロイも同時に実行します。
$ cd handson/dojo/dynamodb
$ python3 -m venv .env
$ source .env/bin/activate
$ pip install -r requirements.txt
$ cdk deploy
以下のような文字列が表示されたらデプロイは完了です。

【LEVEL1】基本的なデータの読み書きを実践してみる。
デプロイが完了したら早速コードの方を入力していきます。今回も統合開発環境である "Jupyter NoteBook"を使用していきます。
venvの仮想環境内にいる状態で以下のコマンドを入力し Jupyter にアクセスします。
$jupyter notebook
起動後、新規ファイルを作成し、コードを入力していきます。まずは、
今回使用するライブラリをインポートし、Session()オブジェクトを経由して DynamoDBを呼び出します。
import boto3
from pprint import pprint
from datetime import datetime
session = boto3.Session(profile_name="default")
ddb = session.resource("dynamodb")
コードの解説に移ります。boto3についてや、Session()オブジェクトについては前編のLevel1で解説済みなのでそちらを参照してください。
今回新出のpprintは配列や辞書型の要素を、成形して出力したり、文字列型に変換したりするライブラリです。
なくても問題ないライブラリですが、pprintを使用することで通常のprint を使用するより整っており、分かりやすい出力結果を得ることができます。
【参考】https://www.gis-py.com/entry/pprint
次に読み込んでいる datetime はPythonの標準ライブラリで、日時の取得や変換を行ってくれます。
次に、テーブル名を先ほど呼び出したdynamodbに定義します。(変数ddb)
table_name = "デプロイ時に表示されたテーブル名"
table = ddb.Table(table_name)
これで、演習を行う準備が整いました。
今回のDynamoDBの演習は、新型コロナウイルスのワクチン接種予約システムのデータベースを構築することを想定し進めていきます。
テーブルの仕様は以下の通りです。
| 属性 | データ型 | 説明 |
|---|---|---|
| username | string | ユーザ名を記憶(主キー) |
| dose | number | ユーザ名を記憶(主キー) |
| age | number | ユーザ名を記憶(主キー) |
| prefecture | string | ユーザ名を記憶(主キー) |
| last_name | string | ユーザ名を記憶(主キー) |
| first_name | string | ユーザ名を記憶(主キー) |
| status | string | ユーザ名を記憶(主キー) |
| date | string | ユーザ名を記憶(主キー) |
resp = table.put_item(
Item={
"username": "sazae_huguta",
"firstname": "Sazae",
"last_name": "Huguta",
"age": 24,
"prefecture": "Tokyo",
"dose": 1,
"status": "reserved",
"date": datetime(2021,7,20,hour=10,minute=0).isoformat(timespec="seconds"),
}
)
put_item()メソッドを使用することでテーブルにデータを書き込むことができます。
次に、データが正しく登録されたか確認するためにget_item()を使用します。
resp = table.get_item(
Key={"username": "sazae_huguta", "dose": 1}
)
pprint(resp["Item"])
画像のように、登録した情報が出力されたら成功です。

次に、保存されているデータの書き換え(更新)を行ってみます。
ここではupdate_item()メソッドを使用することで内容を更新します。
resp = table.update_item(
Key={"username": "sazae_huguta", "dose": 1},
UpdateExpression="SET prefecture = :val1",
ExpressionAttributeValues={
":val1": "Aomori",
}
)
update_item()メソッドについて、詳しく解説します。
まず、第一引数の"Key"では、記述した内容で更新する対象の特定を行っています。今回の場合、氏名が"sazae_huguta" かつ、doseが1のデータを特定していることになります。
第二引数の"UpdateExpression"では、どのような内容に書き換えるかを指定しています。指定には、SQL文のような更新式を使用します。ここではSETコマンドを使用することで"prefecture"を変数の:val1というものに書き換えるという指定をしています。
第三引数の"ExpressionAttributeValues"で、第二引数で記述した変数"val1" の内容を記述しています。
実行後、正しく更新が行えたか確認するために再度 get_item()メソッドを使用します。
resp = table.get_item(
Key={"username": "sazae_huguta", "dose": 1}
)
pprint(resp["Item"]["prefecture"])
実行後、'Aomori'という文字列が出力されたため、正しく更新が実行されたことが分かりました。

次に、ワクチンの接種状況を更新してみます。具体的にはテーブルの"status"を"completed"に書き換えます。
resp = table.update_item(
Key={"username": "sazae_huguta", "dose": 1},
UpdateExpression="SET #at1 = :val1",
ExpressionAttributeNames={
'#at1': 'status'
},
ExpressionAttributeValues={
":val1": "completed",
}
)
引数の中に、ExpressionAttributeNamesというパラメータを新たに記述しました。これは、文字列 #at1とstatusを対応づけています。
なぜ、このような引数が必要であるかというと、statusという文字列がDynamoDBの予約語であるためです。そのため、直に記述することは不可能であるため、それを回避する手段としてExpressionAttributeNamesが存在します。
Level1の最後は、登録済みの要素を削除してみます。delete_item()メソッドを使用することで要素を削除することができます。
resp = table.delete_item(
Key={"username": "sazae_huguta", "dose": 1},
)
正しく要素が削除されたかの確認を行います。
if resp.get("Item"):
print(item.get("Item"))
else:
print("The item with the given ID was not found!")
要素が存在していれば、その要素名を、存在していないことを示す文字列を返します。
実行後、存在していないことを示す文字列が返されたため、正しく要素が削除されたことが分かりました。

【LEVEL2】QueryとScanを使ってみる。
Level2では、複数のデータが保存されているデータベースから特定のデータを検索し取得する方法について見ていきます。そのためにはBatch writerという概念について知る必要があります。
Batch writerは複数の要素をまとめて書き込む際の効率を上げてくれる機構です。with table.batch_writer() as batch:でBatch writerを起動し、put_item()を呼び出すだけで使用することができます。
今回は"data.json"に用意し仮想的なワクチン予約のデータをまとめて保存します。それではコードを入力します。
import json
with open("data.json","r") as f:
data = json.load(f)
with table.batch_writer() as batch:
for d in data:
batch.put_item(Item=d)
まずはjsonファイルをロードし、ロードしたデータを繰り返し処理でテーブルに順に書き込んでいます。
Batch writerでは、データをローカルのメモリにキャッシュし、ある程度データが溜まった段階でDynamoDBに送信するため通信の効率をあげることができます。
次に、データの検索方法であるQueryとScanについて見ていきます。
Queryとは、特定の値のpartition keyを探す検索方法になります。DynamoDBではpartition keyを基準に物理的なストレージにデータを書き込むことから、ストレージ上の全てのデータを走査する必要がなく効率的にデータを見つけ出すことができます。
それに対し、Scanはデータベースの全てのデータを走査し検索を行います。その仕様上Queryよりも検索時間はかかってしまうが、データにpartition keyを設定していないデータに検索をかける場合などに有用です。
コードを入力していきます。
resp = table.query(
KeyConditionExpression=Key('username').eq('namihei_isono')
)
pprint(resp.get("Items"))
ここでは、KeyConditionExpressionというパラメータに検索する情報を渡しています。ここでは、partition keyであるusernameが'namihei_isono'である要素を探せというような記述になっています。
実行すると、以下のように、usernameが'namihei_isono'である要素が取り出されています。
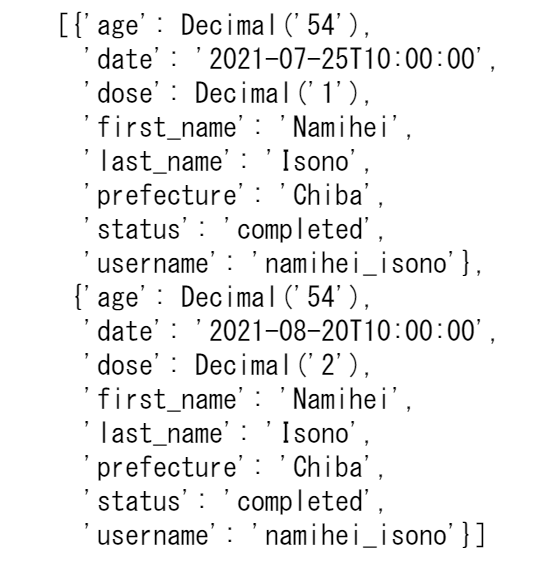
先ほどは検索する条件としてusernameのみを指定していました。次は、usernameに加えワクチンの接種回数も条件に加えてみます。
resp = table.query(
KeyConditionExpression=Key("username").eq("namihei_isono")& Key('dose').eq(1)
)
pprint(resp.get("Items"))
先ほどの条件に'dose'が1である値を探すという条件を追加しました。&をつけることによって、条件の論理積を表現することができます。実行するとdoseが1になっているデータが絞られて検索できました。
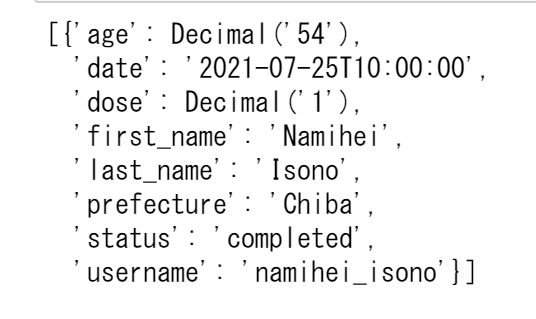
次に、Scanを使用してみます。
resp = table.scan()
items = resp.get("Items")
print("Number of items",len(items))
実行すると"Number of items:8"と返される。

Scanは一回の操作で検索できるデータ量が1MBまでと決められており、1MB以上のデータを検索したい場合は検索内容の続きから検索を再実行する必要があります。そのため、以下のコードを実行します。
resp = table.scan()
items = resp.get("Items")
while resp.get("LastEvaluatedKey"):
resp = table.scan(ExclusiveStartKey=r["LastEvaluatedKey"])
items.extend(resp["Items"])
print("Number of items",len(items))
scan()メソッドから返される情報にはLastEvaluetedKeyという要素が含まれています。情報の走査が全て完了した場合には空文字が、まだ完了していない場合には最後に読んだ要素の主キーが返されます。この仕様を利用しデータベースの走査が全て完了するまでscanを繰り返します。
次にScanで条件を絞った検索を行う方法について見てきます。
resp = table.scan(
FilterExpression=Attr('age').lt(27)
)
print("Number of items",len(resp.get("Items")))
上記のコードでは年齢が27歳以下の要素を取り出しています。
FilterExpressionというパラメータに条件を入れることで条件を指定することができます。
実行すると以下のような結果が得られました。年齢を表す'age'が27以下の要素のみが取得できたことが分かります。
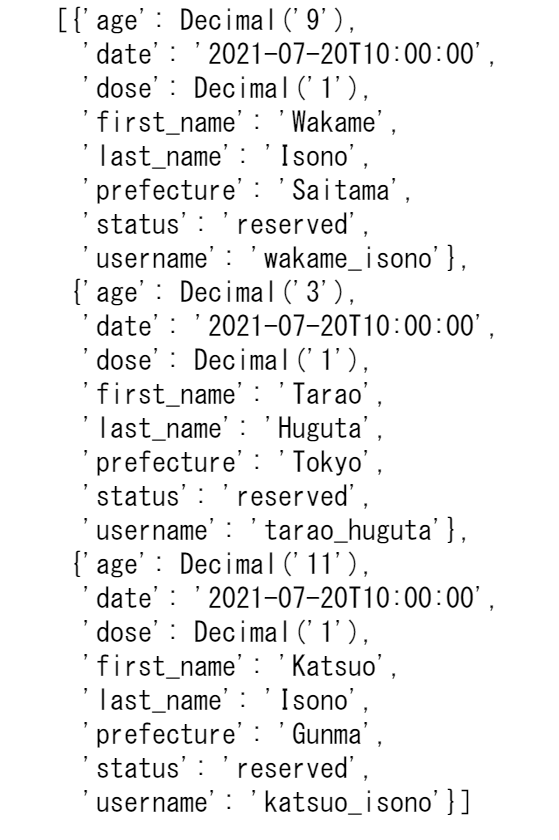
次にScanを利用して要素の一部の属性を取り出す方法について見ていきます。現実でデータベースを利用する場合、氏名や年齢といった必要な情報だけ欲しいケースが多々あります。ProjecttionExpressionパラメータを使用することで欲しい属性のみを返すことができます。
resp = table.scan(
ProjecttionExpression="first_name, prefecture"
)
print(resp.get("Items"))
実行結果は以下の通りです。"first_name"と"prefecture"のみが返されていることが分かります。

【LEVEL3】テーブルのバックアップを取る。
webアプリなどで実際にデータベースを運用する際はデータのバックアップが必須です。データの消失は信用問題に関わります。Level3ではDynamoDBでバックアップを作成する方法とバックアップを復元する方法を見ていきます。まずは、DynamoDBのclient()オブジェクトを作成します。
client = session.client("dynamodb")
バックアップはcreate_backup()メソッドを呼びだすだけで実行できます。
resp = client.create_backup(
TableName=table_name,
BackupName=table_name + "-Backup"
)
backup_arn = resp["BackupDetails"]["BackupArn"]
print(backup_arn)
create_backup()メソッドの引数にはバックアップを取るテーブル名とバックアップの名前を指定します。返り値にはBackupArnというパラメータが含まれており、これを基にバックアップの情報を取得します。
resp = client.describe_backup(BackupArn=backup_arn)
pprint(resp["BackupDescription"]["BackupDetails"])
実行すると以下のようなリストが出力されます。

次に、基のデータベースで要素を書き換えます。"huguta_tarao"というusernameの方の'age'を3から4に変更します。
resp = table.update_item(
Key={"username":"tarao_huguta","dose":1},
UpdateExpression="SET age = :val1",
ExpressionAttributeValues={
":val1":4
}
)
resp = table.get_item(
Key={"username":"tarao_huguta","dose":1},
)
pprint(resp["Item"]["age"]
実行するとDecimal('4')という結果が得られました。
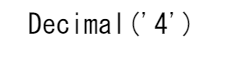
書き換えが完了したら作成していたバックアップを基のデータベースに復元します。
restored_table_name = table_name + "-restored"
resp = client.restore_table_from_backup(
TargetTableName=restored_table_name,
BackupArn=backup_arn,
)
restore_table_from_backup()を呼び出すことでバックアップを復元することができます。
復元されたテーブルの状態を確認します。
resp = client.describe_table(TableName=table_name + "-restored")
pprint(resp["Table"]["TableStatus"])
初回実行直後だと'CREATING'と返されバックアップを復元中であることが分かります。しばらく待つと'Active'に出力結果が変わります。Activeの状態だとテーブルへの読み書きができるようになります。


バックアップが復元できたか確認します。
restored_table = ddb.Table(restored_table_name)
resp = restored_table.get_item(
Key={"username":"tarao_huguta","dose":1},
)
pprint(resp["Item"]["age"])
実行すると"Decimal('3')という出力が得られました。正しくバックアップが復元されたことが分かります。
今回の演習は異常なので復元されたテーブルとバックアップのデータは削除しておきます。
restored_table.delete()
resp = client.delete_backup(BackupArn=backup_arn)
スタックの削除
今回の演習は以上なのでスタックを削除しておきます。
$ cdk destroy
最後に
今回はboto3を利用した DynamoDBの操作方法について学びました。Level1では基本的なテーブル操作について、Level2では、QueryやScanを使った検索方法について、Level3ではテーブルのバックアップを取る方法について学びました。