はじめに
生成AIといえばChatGPTのような対話型AIや、Stable Diffusionのような画像生成AIのイメージがありますが、近年はこのような一般的な用途に留まらず、様々な分野へ応用されています。今回はその中でも、材料開発の分野における応用について焦点を当てます。
この記事では、上海大学などの研究者らによって Journal of Materiomics に発表されたレビュー論文「Generative artificial intelligence and its applications in materials science: Current situation and future perspectives」(Yue Liu et al., 2023) を読み、生成AI(以下、GAI)の材料開発への応用例、直面している課題、そして今後の展望などについて紹介します。
イントロダクション
材料科学におけるデータ駆動型アプローチは、実験・理論・計算に次ぐ「第4のパラダイム」と呼ばれ、様々な試みが行われています。しかし、課題は依然として多いのが現状です。論文では、特に以下の3つの課題がその進展を妨げていると指摘しています。
-
高次元な特徴空間 vs. 少ないサンプル数
→ 材料の特性は多数の因子(特徴量)に依存するが、実験等で得られるサンプル数は限られている -
精度 vs. ユーザビリティ
→ 高度な機械学習モデルは精度が高いが、専門家以外には使いこなすのが難しい -
モデルの出力 vs. ドメイン知識
→ 機械学習が見出した相関関係が、既存の物理法則や化学的知見(ドメイン知識)と必ずしも一致するとは限らない
ここでGAIが登場します。GAIは、データ分布を学習し新しいデータを生成することができます。さらに重要なのは、物理法則などのドメイン知識をモデルに組み込むことで、上記1〜3の課題を解決し、より信頼性が高く、解釈可能なモデルを作ることができる可能性があります。いくつかの先行研究では既に、材料の性能予測や新材料発見に応用され始めています。
近年、大規模言語モデル(LLM)に代表されるように、プロンプトによる指示や人間からのフィードバックによる強化学習(RLHF)を取り入れたGAIは、特定のタスクに留まらない汎用的な能力を獲得しつつあります。この論文は、こうしたGAIの発展状況、材料科学への応用、将来の可能性、そして克服すべき課題とその解決策を体系的にレビューすることを目的としています。

様々なGAI手法と、材料科学への応用
この章では、特定の目的に合わせて改良されてきた「タスク特化型GAI」から、より広範な問題に対応可能な「汎用GAI」まで、様々なGAI手法が解説され、材料科学分野での応用例が紹介されています。

様々なGAI手法と材料開発における応用例。青色はコンピューターサイエンスでの研究が、緑色は材料開発での研究が盛んである分野を示す。論文より引用
生成的敵対ネットワーク(GAN)
モデルの概要
本物そっくりのデータを生成しようとする「生成器 (Generator)」と、本物か偽物かを見抜こうとする「識別器 (Discriminator)」が互いに競い合いながら学習を進める、ゼロサムゲームのような仕組みで学習を行うモデルです。
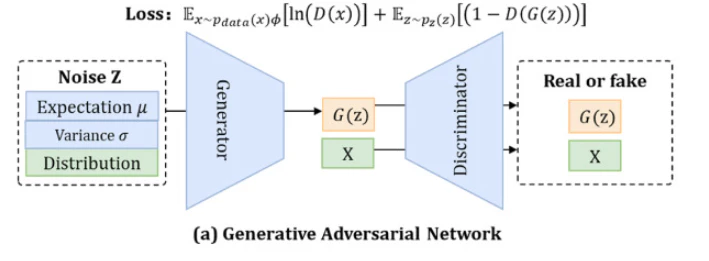
GANの模式図。論文より引用
近年では、初期モデル(Vanilla GAN)の学習不安定性やモード崩壊(生成されるデータが多様性を失う現象)を改善するため、条件情報を付加するCGAN、畳み込み層を用いるDCGAN 、損失関数を改良したWGAN、WGAN-GP、CycleGAN 、表形式データに特化したTabularGAN、TGAN、CTGAN など、多数の派生モデルが開発されています。
材料開発における応用例
材料開発においては、データの拡張(Augmentation)へ応用されることが多いようです。論文中では少量の顕微鏡画像データ(多結晶鉄 )や実験値(超高性能コンクリートの圧縮強度 、高エントロピー合金の硬度 )から学習し、機械学習モデルの訓練データを生成・拡張する先行研究が紹介されています。
また逆設計(目標特性を持つ新材料の候補生成)への応用例もあり、例えば、MatGANと呼ばれるモデルを用いた大規模な無機材料・二次元材料探索、Mg-Mn-O系での光電気化学アノード用結晶構造予測 、特定の結晶構造を生成する「CCDCGAN」などの開発が行われています。
課題としては、生成された材料候補が実際に合成可能か、安定して存在するかの検証が別途必要であり、また、生成品質の客観的な評価指標が確立されていない点が挙げられます 。
変分オートエンコーダ (VAE)
モデルの概要
入力データを低次元の「潜在空間」における確率分布として表現するエンコーダと、潜在空間の点からデータを復元するデコーダから構成されます。潜在変数を確率分布として扱うことで、未知のデータ領域の探索が可能になります。
近年では、生成画像の質を改善するVAE-GAN、VLAE、NVAE 、離散的なデータを扱えるようにするVQ-VAE、JointVAE、VQ-VAE-2、潜在変数の各次元が独立した意味を持つように学習(因子分解)する能力を高めるβ-VAE、FactorVAE、β-TCVAE などが派生モデルとして提案されています。
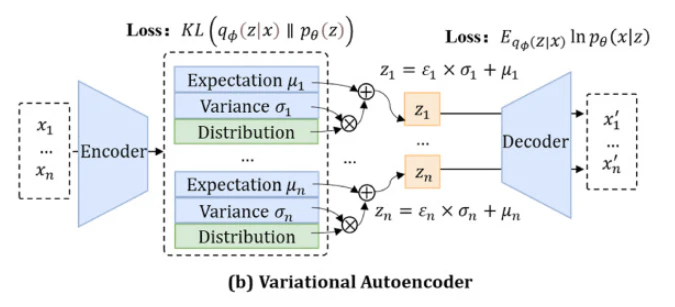
変分オートエンコーダの模式図。論文より引用
材料開発における応用例
材料開発においては、以下のような応用例が挙げられています。
- 薬物様分子を連続的な潜在ベクトルで表現し、そのベクトルを操作することで新しい分子構造を生成・最適化 -> 分子設計
- 既知材料の化学組成空間の分布を学習し、高性能なバナジウム酸化物の発見や、合成可能な範囲(エネルギー的に安定な範囲)にある約40種の新規酸化物を含む約2万種の仮想材料を生成 -> 逆設計
- 材料の微細構造画像から、機械的特性に関わる重要な特徴を解釈可能な形で抽出し、特定の特性を持つ微細構造を生成 -> 微細構造の解釈
一方で課題としては、材料データ特有の複雑さ(結晶構造など)に合わせたモデル構造や目的関数の最適化、高次元データの効率的な取り扱い、生成された材料の物理的・化学的な妥当性の検証などが挙げられています。
拡散モデル (DDPMs)
モデルの概要
以前、こちらの記事で紹介しましたが、元のデータに段階的にノイズを加えていく「拡散過程 (forward process)」と、ノイズ状態から段階的にノイズを除去して元のデータを復元する「逆拡散過程 (reverse process)」を学習します。この逆過程を用いることで新しいデータを生成します。
近年では、オリジナルのDDPMの課題であった生成速度の遅さ(DDIM、DP、DDSS、GENIEなど )、データ汎化能力(LSGM、D3PMs )、尤度最大化(Improved DDPM、VDM、ScoreFlow、Analytic-DPM )などを改善する研究が活発に行われています。
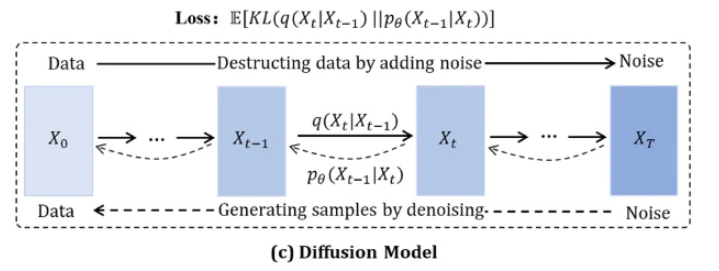
拡散モデルの模式図。論文より引用
材料開発における応用例
材料開発においては、光感度と破壊靭性といった複数の機能を持つ複合材料の微細構造設計への応用が紹介されています。また、タンパク質の3次元構造、アミノ酸配列、側鎖の配向(回転異性体)を非常にリアルに生成するモデル や、分子の対称性(並進・回転・鏡映不変性)を考慮し、特定の標的タンパク質に結合する薬物候補を設計する「DiffSBDD」、タンパク質の配列と構造を同時に設計する「PROTSEED」など、生物学や創薬分野での応用が進んでいるとのことです。
一方で課題としては、学習と推論(データ生成)に要する計算コスト(メモリ、時間)が他のモデルより大きい傾向があり、材料データのような画像以外のデータ形式への適用技術はまだ発展途上となっています。
(以下、筆者補足)
と、論文には書かれていますが、こちらの記事で紹介したように、拡散モデルをベースにした材料生成モデル「MatterGen」が2025年に登場しています。
Flowベース生成モデル (Flow-based Deep Generative Models)
モデルの概要
GANやVAEのようにデータ分布を近似するのではなく、可逆的な(元に戻せる)数学的変換を連ねることで、複雑な実データ分布を単純な基準分布(例:正規分布)へと直接変換する写像 $f$ とその逆写像$f
^{−1}$を学習します。これにより、データの生成確率(尤度)を厳密に計算できるという利点があります。
最近では、初期モデルであるNICEから、より表現力の高いRealNVP、Glow 、さらに微分方程式の考え方を取り入れた連続正規化フロー(CNF)やFFJORD などへと発展しています。

フローモデルの模式図。論文より引用
材料開発における応用例
材料のイオン伝導度に関するデータセットに対し、RealNVPを用いてデータ拡張を行い、予測モデルの訓練データ不足を補った研究例が紹介されています。
課題としては、モデル構造が精緻である一方、パラメータ数が多くなり計算コストが増大する傾向があります。また、材料特有の複雑な構造や物理的制約をどのようにモデルに組み込むか、という点についても今後の課題です。
汎用GAI (General GAI)
汎用GAIはいわゆるChatGPTなど、人間が理解できる言語や多様なモダリティ(テキスト、画像、音声など)を扱い、広範なタスクを実行できる「汎用的な」知能の実現を目指して開発されているモデルを指します。
初期のGAIはTransformerアーキテクチャを基盤とし、GPT(教師なし事前学習+ファインチューニング) → GPT-2(モデル規模拡大、ゼロショット学習) → GPT-3(プロンプトによる少数ショット/ゼロショット学習) へと進化しました。
そして2023年に登場したGPT-4は、前例のない規模の計算とデータで訓練され、マルチモーダル(テキスト+画像など)な入出力に対応し、多くのタスクで人間レベルの性能を示すに至りました。

汎用GAIの歴史。モデルの性能向上に伴いタスク特化型GAIからより汎用的なタスクに対応したGAIへと変化してきたことが示されている。論文より引用
汎用GAIは材料科学の現場で使えるか?
このセクションでは、汎用GAIの代表格であるChatGPTが材料開発にどの程度有効かを検証した結果がいくつか報告されています。
材料データ生成
材料の結晶構造を表すCIFファイルを4種類の固体電解質材料について生成させたところ、ファイル形式は保たれるものの、結晶学的な知識(対称性を示す空間群、原子座標、結合様式など)が不正確でした。しかし、$NaZr_2(PO_4)_3$ の例では、研究者がプロンプトで具体的なルール(例えば、Rule 1: 空間群を'R-3c'に 、Rule 2: 各原子の占有サイトを指定 、Rule 3: $ZrO_6$八面体と$PO_4$四面体の結合様式を指定 )を与えることで、より正しい構造へと修正されました。つまり、対話による改善可能性はありますが、深いドメイン知識がない限りAIが自律的に信頼性の高いCIFを生成することは現状困難であると報告されています。
また、文献からイオン伝導度などの実験データを抽出・整形させるタスクでは、生成された数値や参照文献情報が不正確であるケースが多く、信頼性に欠ける結果となりました。現時点では、関連文献の検索補助程度に留まっているとのことです。

ChatGPTを使ったcifファイル生成例。論文より引用
微分方程式の解法
材料の挙動モデリングに不可欠な微分方程式についてChatGPTの応用例が紹介されています。結果としては、簡単な常微分方程式(例:du/dt+u^2=0)であれば、差分法などの解法ステップを示し、計算結果を可視化するPythonコードを生成できました。しかし、より複雑な偏微分方程式(PDE) については、完全な解法プロセスを示すことができず、現在の能力には限界があることが分かりました。

ChatGPTを使った微分方程式の解法生成例。論文より引用
材料に関するFAQへの応答
材料研究者が日常的に行うタスクの一つである、文献調査に関してChatGPTを応用した例が紹介されています。例として、$Li_{0.5}La_{0.5}(TiO_3)$ (LLTO) のイオン伝導性改善方法について検証を行っています。
このようなプロンプトに対しChatGPTは、ドーピング、合成プロセス最適化、粒径制御など、複数の改善戦略をリストアップし、ドーピングに関しても具体的な元素候補やそのメカニズム(例:イオン導入、酸素空孔生成)を説明できました。しかし、各戦略の長所・短所、具体的な実験条件、最適な選択肢といった研究者が次に取るべきアクションに繋がるより詳細な情報を提供することはできませんでした。
つまり、文献情報を広く集めて集約することはできるが、より専門的なアドバイスができるレベルにはない、という結論となりました。

ChatGPTを使った材料の特性改善案の生成例。論文より引用
材料開発におけるGAI導入の課題
GAIを材料科学分野で真に価値あるツールとするためには、いくつか大きな課題があります。論文では、これらを6つの側面から分析しています。
高品質なデータとドメイン知識 (High-quality data and domain knowledge)
GAIの性能は、学習に用いるデータの「質」と「表現方法」に根本的に依存します。特に、材料データは非構造的であったり、ノイズが多かったりするため、GAIが元のサンプルの本質的な特徴を正確に捉え、再現することが難しい場合があります。
また、低品質なデータを用いて単純な確率分布(例えばガウス分布)でこの関係を近似しようとすると、元のサンプルの欠陥を増幅させたり、物理法則や化学的知見といったドメイン知識と矛盾するような結果を生み出したりする危険性があります。
この課題に対する解決策としては、
- 物理法則や化学的制約などのドメイン知識を記号化し、データ表現手法自体に組み込む -> GAIが基本的な科学原理を学習しながら有効な情報を保持し、不要な情報を排除できるようになる
- ドメイン知識を埋め込んだデータ品質検査手法を用いることで、サンプル中の異常データを特定・除去し、データセット全体の質を向上させる -> GAIが生成する新しいサンプルもドメイン知識に準拠し、元データと生成データが互いに補強し合う好循環が生まれる
といった手法が提案されています。
汎化能力(Generalization ability)
汎化能力とは、GAIが学習データでカバーされていない新しい状況(未知の材料組成や構造)に対しても、妥当な予測や生成を行える能力を指します。特定の材料系に特化して訓練されたGAIモデルは、そのターゲット材料に対しては高い精度を発揮するものの、他の種類の材料への汎化能力は低い傾向があります。逆に、広範なデータを学習した汎用GAIモデル(ChatGPTなど)は、多様な入力に対応できる一方で、生成される内容の科学的な信頼性は低くなる傾向があります。また、GAIモデルの汎化能力を効果的に評価する標準的な手法がまだ確立されていないことも課題となっています。
解決策としては、サンプルデータの質と内容、そしてGAIモデルの特性を総合的に考慮する必要があります。さらに、ドメイン知識や常識的な制約をモデルに組み込むことで、生成されるアウトプットをより正確かつ多様で、制御可能なものにすることが求められます。
解釈可能性と信頼性(Interpretability and credibility)
GAIが材料科学に革命的な変化をもたらす可能性を持つ一方で、その「ブラックボックス」的な性質から、生成結果の信頼性やモデルの解釈可能性に対する懸念は根強く残っています。特に深層学習ベースのモデルは内部の潜在空間の次元が非常に高く、その意味論も複雑であるため、どのように解釈し、説明責任を果たすかが大きな問題となっています。
解決策としては、
- 学習された潜在空間に含まれる意味論的な特徴に焦点を当て、それらを操作することでモデルの内部処理を説明する(実際に研究が行われている)
- GAIの内部メカニズムを完全に理解することに加えて、モデルがどのようにして段階的に結果を得るのか、その生成プロセス自体を検証する。例えば、人間とモデルが継続的に対話し、モデルが自身の出力を説明するようなメカニズムの導入を行う
- ドメイン知識をモデルに組み込み、モデルがどの特徴量(記述子)を重要視しているかを検証する
といったことが提案されています。
ユーザビリティ(Usability)
ユーザビリティとは、GAIモデルを実世界の材料科学の問題解決に適用する際の容易さや効率性を指します。GAIの生成プロセスは複雑で予測不可能な場合があり、大量に生成された候補の中から本当に信頼できる、あるいは有望な結果を注意深く選別する必要があります。論文では、あるGANが26万以上の新規組成候補を生成したものの、DFT計算で安定性が確認されたのはわずか92件であった例や、別のGANが1000万サンプルを生成し、そのうち410万サンプルが下流のスクリーニングに適格とされ、最終的にフォノン分散計算で検証されたのは506件だったという例が引用されています。これはつまり、GAIの出力の「歩留まり」が低いことを示唆しています。
解決策としては、
- 生成プロセスに物理情報(対称性、エネルギー制約など)を組み込み、生成されるサンプルをより妥当なものに誘導する
- 能動学習 (Active Learning) を活用し、GAIが生成したラベルなしサンプルの中からモデル性能向上に最も寄与しそうなものを効率的に選択し、人間による評価(ラベリング)対象を絞り込む -> 候補サンプルの質を高め、候補数を大幅に削減し、人手によるスクリーニングコストを低減する
といった手法が紹介されています。
リソースコスト (Resource cost)
GAIモデルは強力な生成能力を持つ一方で、そのトレーニングと運用には多大なリソースを消費するという問題があります。リソースコストには、モデルが特定の生成能力を獲得するまでに必要なトレーニングコスト(計算能力、高性能な計算機器、訓練時間)と、モデル運用時に必要な運用コスト(主にエネルギー消費)が含まれます。そのため、学習効率を合理的かつ効果的に向上させることが、これらのコストを削減する鍵となります。
論文では、生成品質を損なうことなくGAIモデルを圧縮・最適化する標準的な「プルーニング技術」や、GAIモデルの訓練効率とリソース消費の関係を最適化する研究が紹介されています。
セキュリティ (Security)
GAIモデルの多くがブラックボックスとしての特性を持つため、セキュリティ上の懸念が生じることが指摘されています。一般的に知られているように、GAIを悪用すれば説得力のある偽のテキスト(虚偽のニュース記事、SNS投稿、フィッシングメールなど)を生成することは容易です。また、GAIモデルはデータプライバシーや知的財産に関しても脆弱であり、訓練データやモデルパラメータを盗み出すといった攻撃も考えられます。そのため、GAIが知的財産を含むような情報の生成を行う場合はモデルのセキュリティを強化し、生成されたコンテンツとモデルの内部データの両方を保護する手法の確立が緊急の課題となります。
まとめ
論文の内容については以上になります。本論文では様々なGAI手法のレビューを通じて、GAN、VAE、拡散モデル、フローモデルといった多様なGAI手法が材料科学に応用されていることが明らかになった一方で、より高度で専門的な応用には未開拓な部分も多いことが示唆されました。またChatGPTを用いた検証では、汎用GAIのポテンシャルと同時に、高度なドメイン知識を要するタスクに対しては正しい回答を出すのは難しいという現状も浮き彫りになりました。ただ、これは2023年当時に公開されていたモデルを使用した結果なので、2025年現在の最新モデル(GPT4.5)などを使えばまた違う結果になるかもしれません。生成AI技術の進歩と、人間(科学者)の深いドメイン知識との融合が進めば、これまで不可能と思われた新素材の発見などが可能になる日も近いのかも知れません。以上、ここまで読んでくださりありがとうございました。