はじめに
本記事はNI+C Advent Calendar 2021の15日目の記事となります。
今年度から、Google Cloudを担当しています。
次回携わる予定の案件で、Compute Engineのマネージドインスタンスグループを使用するため、実機で動作確認のため、オートスケーリングを体験してみました。
マネージドインスタンスグループとは
マネージドインスタンスグループ(MIG)では、複数の同一 VM でのアプリケーション操作が可能です。自動スケーリング、自動修復、リージョン(マルチゾーン)デプロイメント、自動更新などの自動化 MIG サービスを活用することで、スケーラブルで可用性に優れたワークロード処理を実現します。
検証
検証内容
検証環境にCPU負荷をかけ、設定した自動スケーリングが機能するか確認する。
また、CPU負荷低減された際に、スケールダウンするか確認する。
検証環境
1.インスタンステンプレート作成
・OS:Cent OS7
・マシン(n1-standard-1:vCPU x 1、メモリ 3.75 GB)
※検証目的のため費用を抑える構成
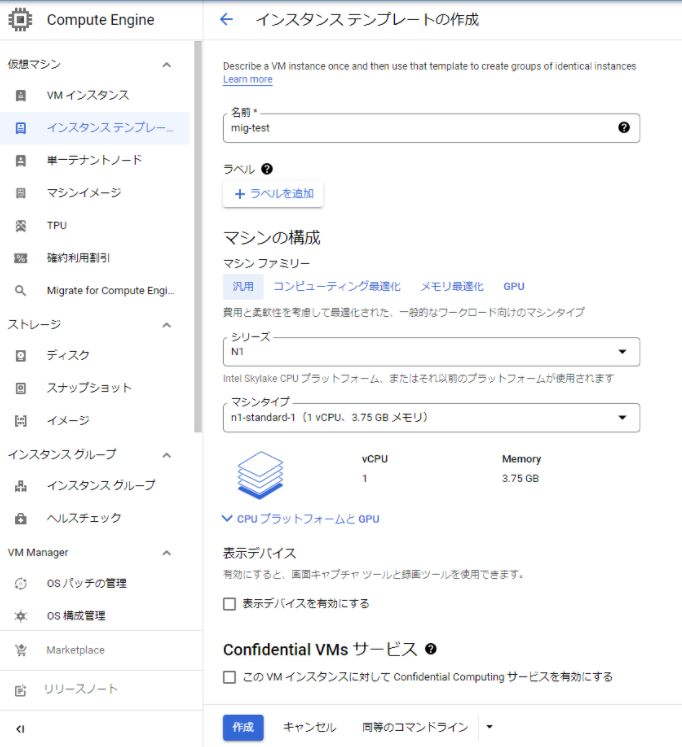
↓作成を押下すると、インスタンステンプレートが作成できます。

(今回は、自動スケーリングのための検証のため、真っさらなOSで実施していますが、事前に準備した環境でインスタンステンプレートを作成することも可能)
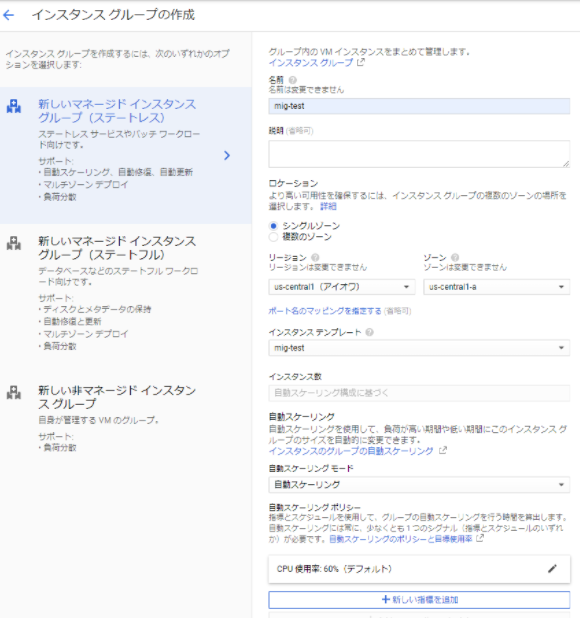
2.インスタンスグループ作成
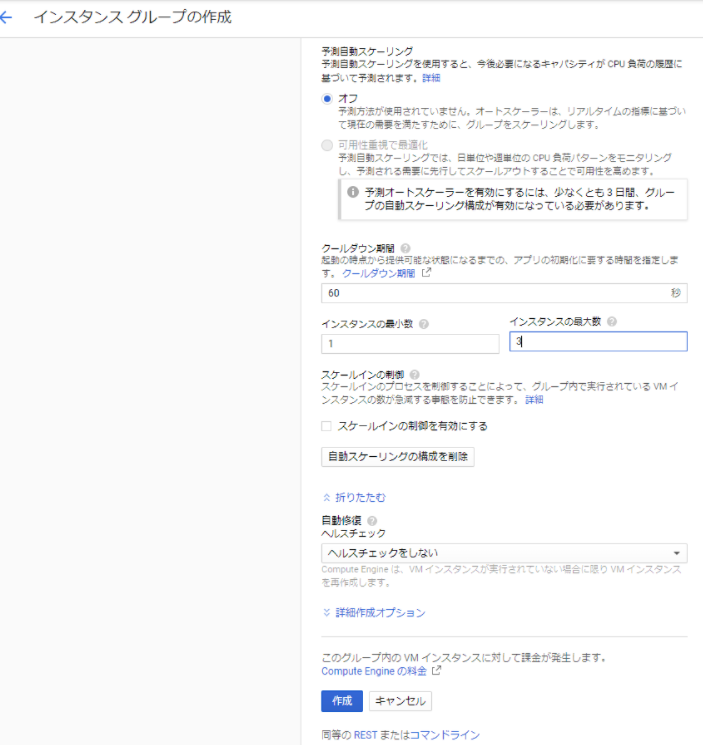
基本的にはデフォルト値にて作成しましたが、自動スケーリングに関する項目は、以下としました。
| 設定項目 | 設定値 |
|---|---|
| 自動スケーリングポリシー(CPU使用率) | 60% |
| クールダウン期間 | 60秒 |
| インスタンス数 最小数 | 1台 |
| インスタンス数 最大数 | 3台 |
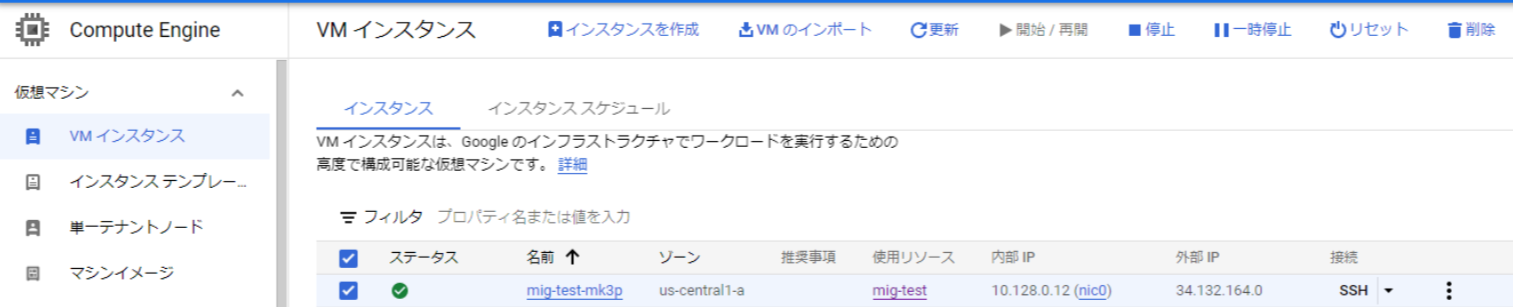
↓まずは、最小インスタンスで1台起動
3.自動スケーリング
1)CPUを負荷をかけるために、stressコマンドインストール
yum install stress
2)CPU1コアに対して1分間負荷をかける
stress --cpu 1 --timeout 1m
3)2)により、CPU負荷が上がり、自動スケーリング稼働
あっという間に、追加で2台立ち上がりました!(早い。)
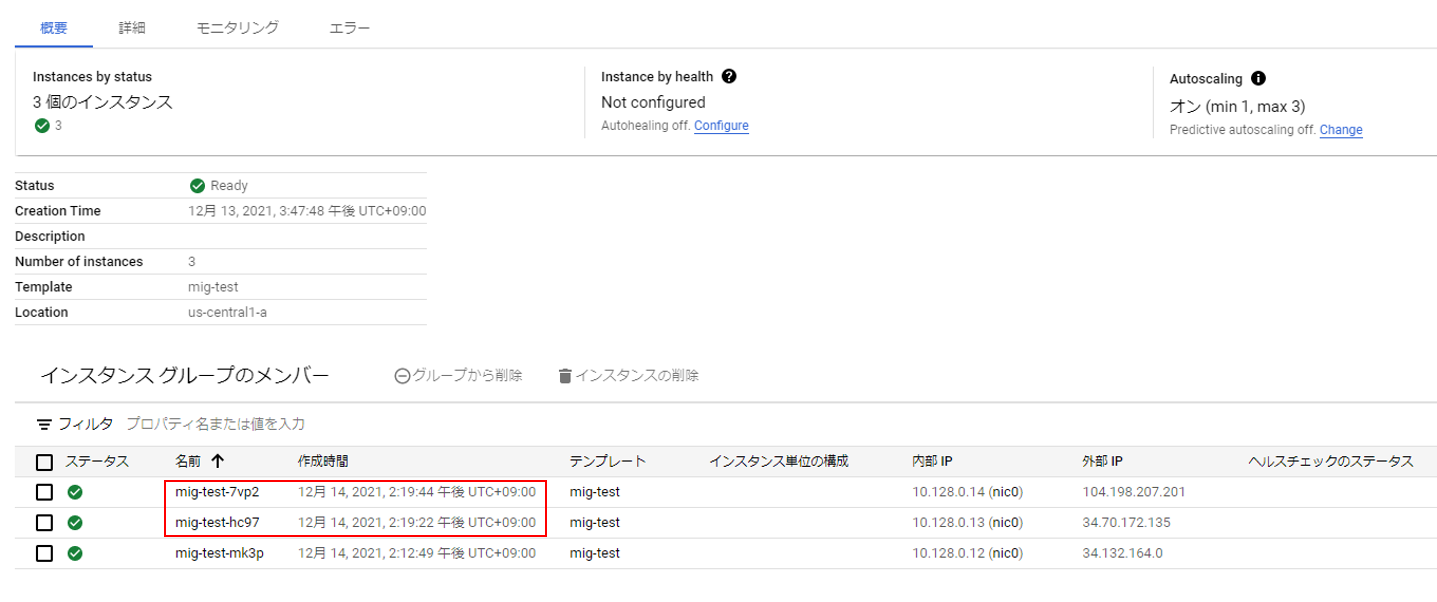
4)CPU負荷が下がり、インスタンス最小値へ
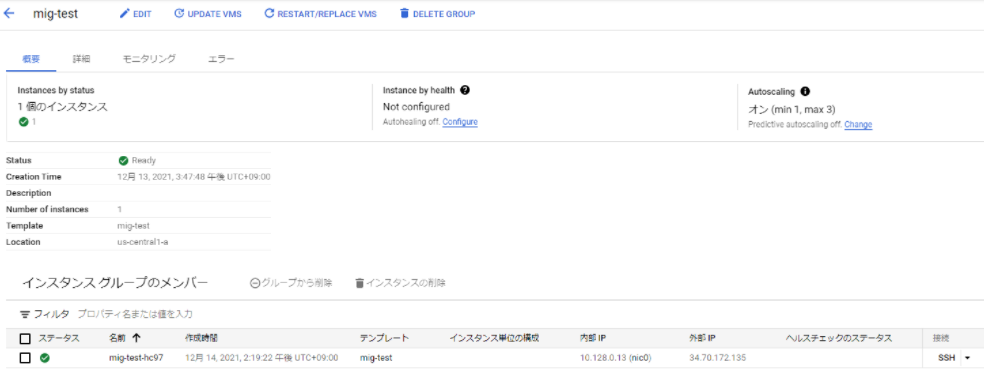
クールダウン期間(今回はデフォルト値の60秒)後に、自動スケーリングポリシーの確認が行われます。CPU負荷は、コマンド終了後に、少しずつ低減していき、インスタンスは自動的に、停止していきました。
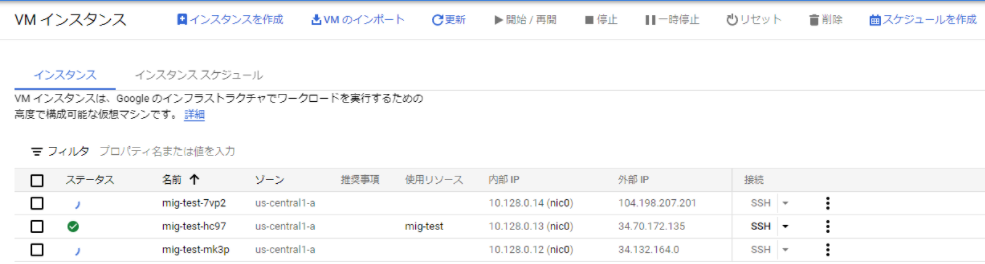
↓インスタンス最小値の1台へ
モニタリングを見てみよう
検証内容が確認できました。
最後に、今回実施した内容のモニタリングを見てみたいと思います。
14時20分頃に、負荷コマンドを実行し、その直後CPU使用率が上がり、インスタンス数が1台から3台に増えたことが分かります。その後、CPU使用率が下がり、インスタンス数が3台から1台に減ったことも分かります。
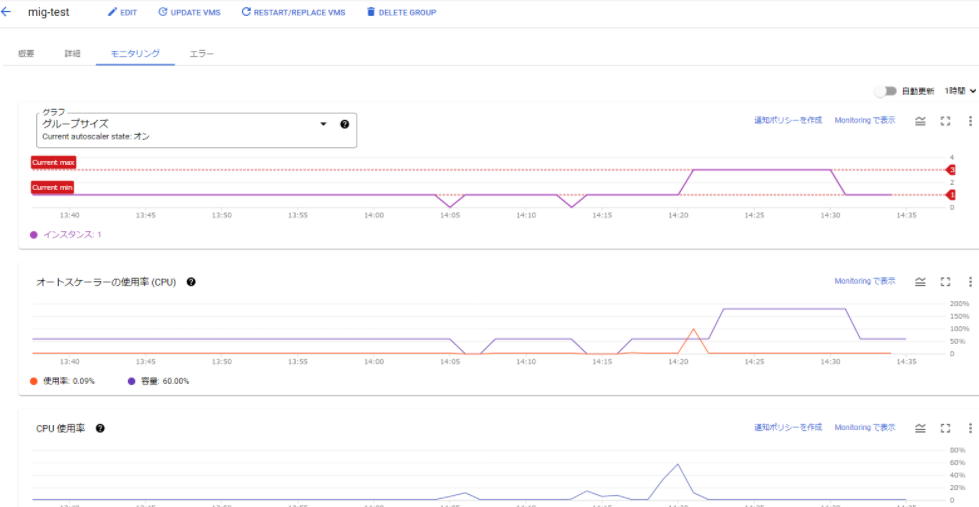
特にカスタマイズしたモニタリングでもないですが、これがすぐに見れるのはいいですね。
最後に
今回は、簡易的にマネージドインスタンスグループの自動スケーリングを検証しましたが、GUIの簡単な操作でできるなんて便利ですね。Compute Engineの耐障害性として、検討してみてはいかがでしょうか。