最近、机の上にお人形(sota君)がやって来ました。

(オレンジ色は特殊仕様らしいです?机の上汚くてごめんなさい)
とりあえずお人形と雑談するために、音声認識・音声合成・雑談機能を組み込んでみようと思いました。
今日の記事はその途中までの道のり(作業ログ)を紹介したいと思います (まだ雑談できてない...)
sota君
今回机の上にやって来たsota君は、Intel Edisonの上でLinux(x86)が動いているお人形です。
LinuxなのでALSAで音声の再生が出来ますし、マイクの制御も出来ます。
目や口のLEDはI2Cで制御でき、腕や首のサーボもシリアルデバイス経由で動かすことが出来ます。
(公式ではJavaのSDKが用意されていますが、Javaのビルドとデプロイは面倒なので、strace等でI2C/シリアルデバイスの制御方法を取得し、sota君にデフォルトで入っているPython2で動かすライブラリを用意し、簡単に制御できるようにしました)
お人形と雑談するためには、普通にLinux上で動くプログラムを書くだけで良さそうです。
利用する外部サービス
音声認識・音声合成・雑談は難しい機能ですので、無料で利用できるサービスを使って実現します。
天の方からNTTが提供しているcorevo APIを使うのだという声が聞こえてきたので、音声認識・音声合成はcorevo APIを利用し、雑談機能は用意されていないのでdocomoの雑談対話APIを使うことにしました。
(APIドキュメントすら利用登録&色々利用許諾を承諾しないと見られないので、
もしかしたらAPIの使い方すら公開したらだめなのかな?怒られたらぼやかすかもしれません)
音声合成API
corevoAPIの音声合成APIはNTTテクノクロス株式会社のFutureVoiceCrayonを利用しているようです。
WebAPIで操作できるのでとても簡単で、
curl -H "Accept: application/json" -H "Content-type:application/json" -X POST -d '{"Command": "AP_Synth", "SpeakerID":"000-00-0-001", "TextData": "これは、テストです。"}' https://****/FVC/FutureVoiceCrayon/scripts/TTSWebAPI.cgi?apikey=<APIキー> | base64 -d | aplay
とすれば、音声合成APIより"これはテストです"という音声が記録された RIFF PCM Waveファイル (なぜかbase64でエンコーディングされている) が取得でき、base64コマンドで復号、ALSAで再生 といったことができます。
マニュアル(とても誤記が多い)を読むとSpeakerIDにより話者を変えることができ、例えば
- ひまり(女児)
- ちえ(早口な女性)
- あきひろ(緊迫感)
- しろう(堅い男
- ひとし(中性)
などなど30種類ぐらい用意されている中から選べたり、口調を
- ニュース口調
- メイド口調
- 執事口調
等に変更することもできるようです。
音声合成APIはとても簡単に使え、sota君の上でも簡単に実行できそうです。
音声認識API
corevo APIの音声認識APIはNTTテクノクロス株式会社のSpeechRecのようです。
Linux向けSDKをダウンロードすると...
corevo_ASR_SDK_for_Linux_v1.0.0.0
└── Linux
├── document
├── include
├── libs
│ └── x86_64
│ ├── libcorevo.so
│ ├── libvrgclient.so
│ └── libvrvad.so
(略)
まさかのx86_64専用のバイナリブロブSDKです。これではsota君(x86)では動かせません...
とりあえずsota君と外部PCをネットワークで繋いでやり取りすればいいかな…と思い、
手元のGentooでサンプルプログラムをビルドしてみたところ...
$ tree testDriver
testDriver
├── bin
│ ├── AsrTestDriver.sh
│ └── pcm
│ ├── ja_10speech.pcm
│ └── ja_btec_0007_m001_10_iPhone.pcm
└── src
├── AudioRecorderExternalInput.cpp
├── AudioRecorderExternalInput.h
├── CMakeLists.txt
├── Constants.hpp
├── Main.cpp
├── vrg_client.cpp
└── vrg_client.hpp
$ cd testDriver/src; mkdir build; cd build; cmake ..; make
/usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0/../../../../x86_64-pc-linux-gnu/bin/ld: cannot find -lcorevo
/usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0/../../../../x86_64-pc-linux-gnu/bin/ld: cannot find -lvrgclient
collect2: error: ld returned 1 exit status
make[2]: *** [CMakeFiles/AsrTestDriver.dir/build.make:147: bin/AsrTestDriver] Error 1
make[1]: *** [CMakeFiles/Makefile2:68: CMakeFiles/AsrTestDriver.dir/all] Error 2
make: *** [Makefile:84: all] Error 2
リンクエラー…
$ grep link_directories CMakeLists.txt
link_directories(/home/corevo/image/libs/x86_64)
どうやら、libs/x86_64配下の*.soが固定位置にあることを前提としたCMakeList.txtみたいです。
マニュアルにここを環境に合わせて修正しろって書いてありました。
というわけでここを修正して再度makeすると
CMakeFiles/AsrTestDriver.dir/vrg_client.cpp.o: In function `VRGInnerClient::create()':
vrg_client.cpp:(.text+0x5d1c): undefined reference to `vrgcl::RecognizerCorevo::init(vrgcl::RecognizerVRGIndividualParameter const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)'
collect2: error: ld returned 1 exit status
C++11のstd::string ABI非互換によるリンクエラーが...
gcc7はc++14がデフォルトなのでそのせいかなと思ったらCMakeList.txtには
set(CMAKE_CXX_FLAGS "--std=c++11")
が指定されている… いったいこれを作った人はどんな環境でビルドしたんだろう…と思いつつ、
set(CMAKE_CXX_FLAGS "--std=c++11 -D_GLIBCXX_USE_CXX11_ABI=0")
として再度make。今度はリンクも成功した。
このテストドライバはPCMファイルを指定するとそれを音声認識してテキストを出力してくれるみたいなので、
マニュアル記載の実行例を実行してみた。
$ ./AsrTestDriver
Usage: ./AsrTestDriver <url> <port> <id> <key> [optional]
<url> ... VRG backend URL
<port> ... VRG backend PORT
<id> ... VRG domain ID
<key> ... VRG auth API-KEY
The 6 argument (which optional, from last to first) are
[vad_mode] ... 0(off), 1(clientsize), 2(serverside) (default:0)
[continuous_mode] ... 0(off) or 1(on) (default:0)
[input_rate] ... 8000 or 16000 (default:16000)
[input_file] ... audio file name (default:./pcm/ja_btec_0007_m001_10_iPhone.pcm)
[language] ... (default:ja)
[log_level] ... 0:none - 6:verbose (default:0)
Unknown exception caught
$ ./AsrTestDriver <URL> <PORT> <ID> <KEY> 1 1 16000 ../../../bin/pcm/ja_10speech.pcm ja
zsh: segmentation fault (core dumped) ./AsrTestDriver (略)
とてもつらい。バイナリブロブなのでGentooだとだめなのかな...
(マニュアルによると動作環境はCentOS 6.8のみ。つらい)
仕方がないのでDocker上にCentOS6のユーザランドを起動させ、マニュアルに従って
- devtoolset-3のインストール (マニュアル上はdevtoolset-2だけど無かったので...)
- OpenSSL 1.0.2jをソースからビルド&インストール
- 環境変数の設定
を実施し、上記のリンクエラー修正をくわえたtestDriverをビルドしたところ、無事に音声を認識しテキストを出力してくれるようになりました!
サンプルプログラムすらビルドして動かすのが大変なんですけど!そして規模もなかなかっ...
$ wc -l *.cpp *.h*
165 AudioRecorderExternalInput.cpp
396 Main.cpp
701 vrg_client.cpp
81 AudioRecorderExternalInput.h
136 Constants.hpp
41 vrg_client.hpp
1520 total
でもレスポンスはそこそこいいですし、音声認識面白いですね。
(僕は発音とか滑舌が悪いキモオタなので、あまり正しく認識してくれませんが)
音声認識APIをGentooやLinux(x86)から呼び出せるようにする
しかし音声認識SDKが僕の環境(Gentoo)で動かなかったりsota君(Linux x86)では動かないのが悔しいです。
とりあえずマニュアルを読んでみると、以下のライブラリを使っていますというライセンス文等が載っていました。
- opus: 音声符号
- MessagePack: シリアライザ
- nghttp2: HTTP/2ライブラリ
どうやらサーバとHTTP2で会話をし、音声はopusで符号化、制御文等はMessagePackでシリアライズしているのかなということが想像できたので、その会話を見て、適当なクライアントを作ろうと思います。
まず、testDriverを動かし、そのパケットをwiresharkで見てみます。ここの記事のように、SSLKEYLOGFILE環境変数を指定した状態でtestDriverを動かすとMasterSecretが記録されるので、それを読み取るようにWiresharkを設定すれば、HTTPSの中身が読めるようになります。

どうやらHTTP/2以外にもHTTP1.1の通信があり、APIキーを指定して要求を投げているようですが、レスポンスに有用そうな情報が入っていませんね...そしてHTTP/2の通信は上手く復号してくれません。
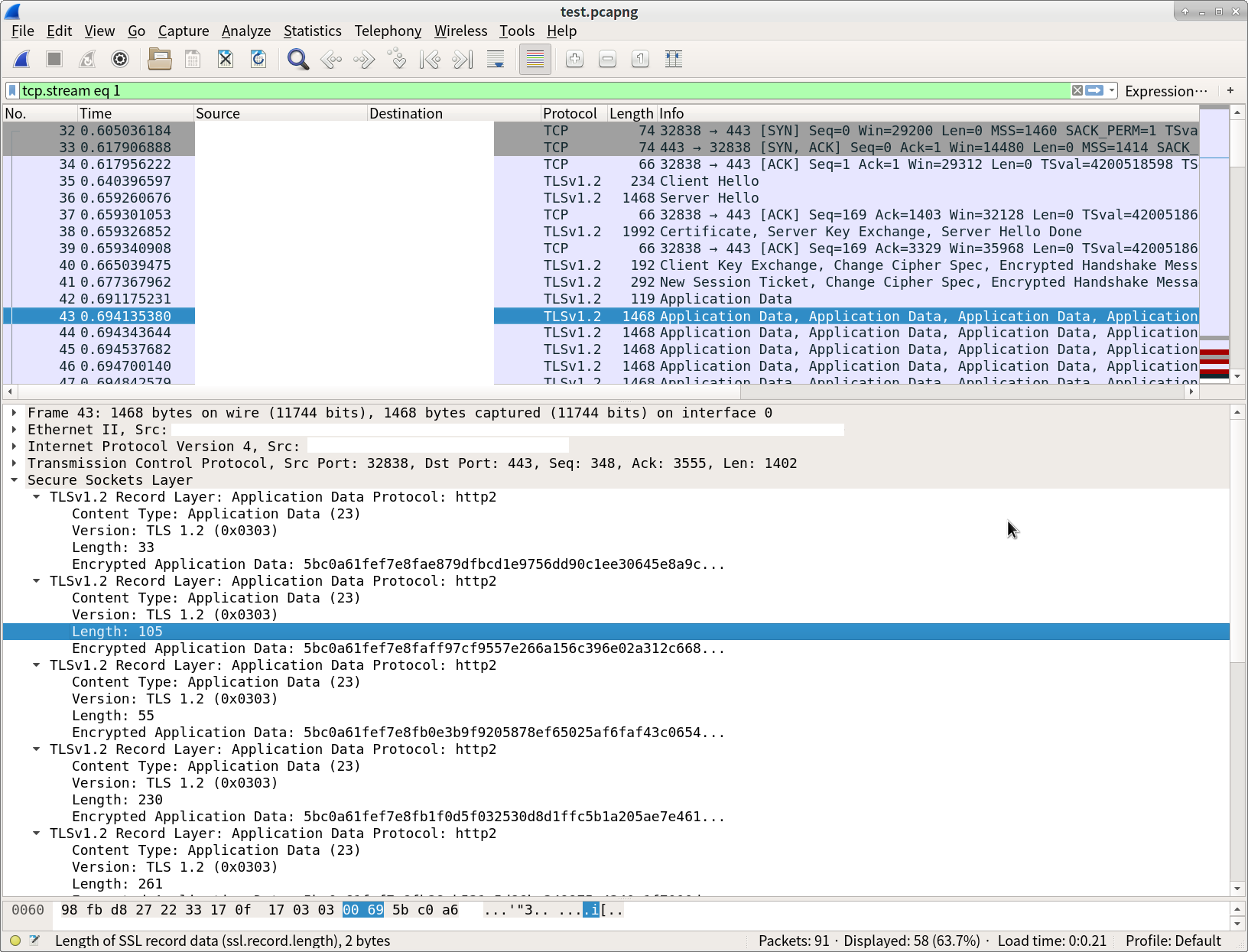
仕方がないので、HTTP/2サーバを設置しそこに向かってリクエストを投げるようにしてみました。
testDriverは任意のドメイン名を指定できるのでそのドメインを指定し、/etc/hostsでローカルを向くようにします。サーバ側はLet's Encryptで取得してある自ドメインのSSL証明書等を設定します。
import socket
from base64 import b64encode
from h2.connection import H2Connection
from h2.config import H2Configuration
from h2.events import DataReceived, RequestReceived
import ssl
import msgpack
ssl_context = ssl.create_default_context(ssl.Purpose.CLIENT_AUTH)
ssl_context.options |= (
ssl.OP_NO_TLSv1 | ssl.OP_NO_TLSv1_1 | ssl.OP_NO_COMPRESSION
)
ssl_context.set_ciphers("ECDHE+AESGCM")
ssl_context.load_cert_chain(certfile="example.com-fullchain.pem", keyfile="example.com-privkey.pem")
ssl_context.set_alpn_protocols(["h2"])
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(('0.0.0.0', 3000))
sock.listen(5)
while True:
client, _ = sock.accept()
tls_conn = ssl_context.wrap_socket(client, server_side=True)
negotiated_protocol = tls_conn.selected_alpn_protocol()
if negotiated_protocol is None:
negotiated_protocol = tls_conn.selected_npn_protocol()
if negotiated_protocol != "h2":
raise RuntimeError("Didn't negotiate HTTP/2!")
conn = H2Connection(config=H2Configuration(
client_side=False,
validate_outbound_headers=False,
validate_inbound_headers=False,
))
conn.initiate_connection()
tls_conn.sendall(conn.data_to_send())
while True:
data = tls_conn.recv(65535)
if not data:
break
print()
for m in conn.receive_data(data):
if isinstance(m, DataReceived):
print('{}: len={}\n\traw={}'.format(m, len(m.data), b64encode(m.data).decode('ascii')))
try:
obj = msgpack.unpackb(m.data, encoding='utf-8')
print('\t{}'.format(obj))
except:
pass
else:
print(m)
すると、MessagePackで設定やOpusバイナリをシリアライズして、それをHTTP/2で送信していることがわかりました。以下のような構造です。
1. チャンネル1で送信 (送信後ch1は閉じる)
{'recognize': {
'userName': '',
'terminalName': '',
'terminalVersion': '',
'terminalId': '',
'appName': '',
'appVersion': '',
'appId': '',
'inputDeviceName': '',
'userId': <ユーザID>,
'sdkName': 'corevo',
'sdkVersion': '1.0.1.0',
'osName': 'CentOS',
'osVersion': '6.8'}
}
2. チャンネル3で設定情報を送信
{'recognize': {
'language': 'ja',
'domainId': <DOMAIN-ID>,
'userAge': 0,
'allowEndDetection': False,
'allowProgress': False,
'maxResults': 1,
'resultLatency': 10000,
'dataType': 'audio/x-voic;codec=opus',
'data': <opusデータ>}
}
3. 発話が終わるまでチャンネル3で音声データを送信
{'recognize': {'data': <opusデータ>}}
ただし、<opusデータ>は以下の情報を順に連結したもの
* 終点フラグ(1バイト. 0x00=終点, 0xff=それ以外)
* '8' (ASCII, 1バイト)
* Opusフレームサイズ + 4 (リトルエンディアン4バイト整数)
* Opusフレームサイズ (リトルエンディアン4バイト整数)
* Opusフレーム (Nバイト)
<ユーザID>を指定するフィールドがありますが、中身はUNIXタイムで、認証っぽい情報は入っていないようですね。
どうやらHTTP/1.1の方でAPI利用数のカウントアップを実施し、
HTTP/2の方は認証なしで音声認識しているようです。こんな作りで大丈夫なのでしょうか...
(TODO: クライアントライブラリをGitHubにあげる)
とりあえず、これで音声認識APIが使えるようになりました。
でもALSAマイクから音声入力するサンプルプログラムを動かしていて気が付きました。
発話している区間がわからないと、このAPIを使ってどこからどこまでの音声を送信していいのかがわからないので、使えないのでは・・・
発話区間を検出する
音声認識APIのSDKがバイナリブロブだけなのは発話区間検出とかそういった処理にきっと特殊な技術が使われていて、秘匿する必要があるからな気がしてきました。音声認識って面倒くさいですね。。。
発話区間検出(VAD: Voice Activity Detection)は、昔から色々な実装がありXiphでも、Speexの取り組みとして、VADの実装を公開しています。
でも最近、MozillaがRNNoiseという取り組みを公開されました。今話題のでぃーぷらーにんぐ(RNN)を使っているやつです。
これを使えば発話区間検出とノイズ除去もできるので、これと組み合わせれば良さそうです。
RNNoiseのPythonバインディングを作り、組み合わせる準備が出来ました。
https://gist.github.com/kazuki/7c7b50ba9df082bfe9f03819201648eb
おしまい
と、ここまでやったのですが、上記を全部組み合わせて雑談対話APIを使って会話するところはまだ手を付けられていません...結構大変ですね...
なんかとても長い割には、いろいろ中途半端な記事になってしまいました…
おしゃべり出来るようになったら、この記事に追記したいと思います。