この記事は Jubatus Advent Calendar 2016の12日目の記事です.
この記事では,Jubatusの線形回帰アルゴリズムを使って,私の出社時間を予測できるか試してみたいと思います.
はじめに
私は裁量労働制という勤務体系のため,4月〜11月の出社時間をプロットすると,下のグラフの様に出社時間は安定していません.
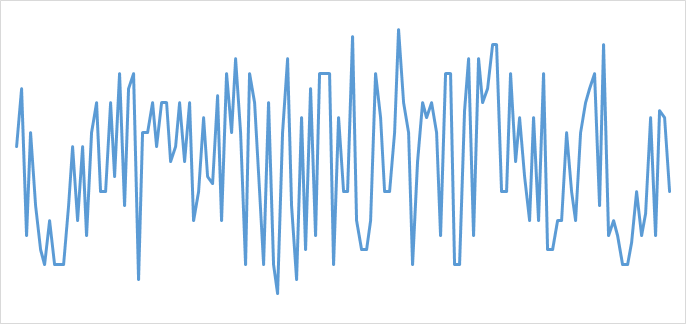
縦軸の詳細は秘密ですが,平均出社時間は11:59,中央値は12:00,標準偏差は2:22なので,如何に分散が大きいかがわかると思います.
そのため周囲から,明日はいつくるの?とかよく聞かれるので,
Jubatusの線形回帰モデルを使って私の出社時間を予測出来ないか試してみました.
利用する特徴量
今回は時間の都合上,利用する特徴量として以下を選びました
- 前日の出社時間
- 前日の退社時間
- 曜日
- 月
予測を行う際は,予測したい日の曜日と月,その前日の出社・退社時間を入力するイメージです.
実装
同じフォルダに data.csv という名前で以下のように過去の勤務時間を保存します.
左から順番に,月,曜日,出社時間,退社時間です.
12,月,10:00,18:30
12,火,10:30,20:00
12,水,12:00,22:00
12,木,13:00,22:00
12,金,13:00,22:00
使い方は,以下のように引数に予測したい日の月,曜日,前日の出社時間,退社時間を入れる感じです.
$ python ./predict.py 12 月 10:00 18:00
MAE=1.6367228031158447, RMSE=1.6974569645511817
9.472633361816406
すると教師データで検証した時の誤差と,予測値が出力されます.
今回の実行例だと予測結果は9.47時なのでおおよそ9:30に出社するということになります.
結果
では実際に僕の4〜11月の勤務簿データを入れて実験してみました.
12/2[金]は8:30〜18:30の勤務でした(珍しく朝早い!).
そして12/5[月]は11:00〜22:00の勤務でした.
では,2日の結果から5日が予測できるでしょうか?
$ python ./predict.py 12 月 8:30 18:30
MAE=2.1355858870915005, RMSE=2.408218719846542
11.384930610656738
ほぼあっているような気がします!
でも,ちょっと待ってください.私の平均出社時間は11:59です.
単に平均に近い値を常に返すモデルになっているような気もします.
いろいろ入力を変えて試してみました.
$ python ./predict.py 12 月 11:00 22:00
MAE=2.135585914339338, RMSE=2.408218736056041
13.2208890914917
$ python ./predict.py 12 火 10:00 22:00
MAE=2.1355858870915005, RMSE=2.408218719846542
11.842284202575684
$ python ./predict.py 12 火 11:00 22:00
MAE=2.1355858870915005, RMSE=2.408218719846542
12.008857727050781
常に平均を返すモデルというわけでは無さそうです.
ただ精度が高いかというと,教師データを使ったテストでも平均誤差が2時間以上ありますので,
平均出社時間を常に返却するモデルとあまり変わら無さそうです…
モデルを見てみる
今回は線形回帰なので,モデルをダンプすることで,どの特徴量が朝早く出社することに貢献しているのか,とか,逆に午後出社となるような原因となる特徴量が分かるかもしれません.
さっそく jubadumpを使ってダンプしてみました.
なおJubatus1.0のモデルは現バージョンのjubadumpではダンプできないので,developブランチのコードを使っています.
(※曜日の日本語はUnicodeのコードポイントで出力されますが,判りづらいためここでは元の文字で置換えています)
$ jubadump -i ./model.jubatus
{
"weights": {
"version_number": 0,
"group_total_lengths": {
},
"document_frequencies": {
},
"group_frequencies": {
},
"document_count": 0
},
"storage": {
"storage": {
"weight": {
"day$水@space#bin\/bin": {
"+": {
"v2": 0.239077375781,
"v1": -0.0731339180192,
"v3": 0
}
},
"day$木@space#bin\/bin": {
"+": {
"v2": 0.287297827964,
"v1": -0.0238389948448,
"v3": 0
}
},
"prev_left@num": {
"+": {
"v2": 0.00017368916633,
"v1": 0.405579139436,
"v3": 0
}
},
"day$火@space#bin\/bin": {
"+": {
"v2": 0.269917546752,
"v1": -0.503465357971,
"v3": 0
}
},
"day$金@space#bin\/bin": {
"+": {
"v2": 0.313711985006,
"v1": -0.337026585546,
"v3": 0
}
},
"day$月@space#bin\/bin": {
"+": {
"v2": 0.232196334218,
"v1": 0.708566693295,
"v3": 0
}
},
"month@num": {
"+": {
"v2": 0.00108040980257,
"v1": 0.146439980475,
"v3": 0
}
},
"prev_target@num": {
"+": {
"v2": 0.000513740491491,
"v1": 0.166572917996,
"v3": 0
}
}
}
}
}
}
"v1"のところに入っているのが重みです.
+方向に大きな値が入っている特徴量は,午後出社に貢献していて,
-方向に大きな値が入っている特徴量は,午前出社に貢献しています.
曜日を見ると月曜日だけが+0.7と大きな値になっており,
休日明けは大抵の場合午後出社になるようです.
また前日の退社時間も+0.4と大きな値となっており,
前日の退社時間が遅ければ遅いほど次の日の出社時間が遅れる傾向にあることが解ります.
おわりに
JubatusのRegressionを使って私の出社時間を予測してみましたが,
今回利用した簡単な特徴量だけでは,精度の高い予測は出来ませんでした.
ただ,jubadumpを使って重みを見ることで,
どういった場合に出社が遅くなる傾向があるのか掴むことは出来ました.
精度を上げるためには天気・気温・気圧といった情報や,
Twitterの最終投稿時間などの他の公開情報と組み合わせる必要があるかもしれません.
明日は @rimms さんがJubatusの分散モードについて書かれるようです.楽しみですね!