はじめに
Googleが提供するライブラリを使ってクローラを作りましたので、その紹介をします。
PuppeteerはGoogleが提供するNode.jsのライブラリで、ChromeまたはChromium(以下、Chrome)を自動で操作することができます。
公式ドキュメント:https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md
注意事項
岡崎市立中央図書館事件のようなクローラが関係する事件が国内で起こっているので、クローリングする際は対象サーバの負荷などに十分配慮し、自己責任で行ってください。
また、対象ページがクローリングを禁止している対象ページが、クローラのアクセスを禁止しているかはrobots.txtで調べられます。
今回クローリングする対象では https://read.amazon.co.jp/robots.txt にアクセスしようとすると404が返ってきたので問題なさそうです。
参考:https://creasys.org/rambo/articles/84fc91dd1071f59e83e3
使ったもの
使用したNodeとPuppeteerのバージョンは以下の通りです。OSはUbuntu(18.04.1 LTS)。
| version | |
|---|---|
| Node | 8.10.0 |
| Puppeteer | 1.11.0 |
ソースコード
それではクローラのソースコードを順に見ていきましょう。まずは導入部分から。
(※投稿しやすくするために実際に動かしたものから若干変更を入れています。ソースコードの全量はここで公開しています。)
const puppeteer = require('puppeteer');
const SELECTORS = require('./constants').SELECTORS
const KINDLE_SIGN_IN_URL = 'ハイライト情報を見るためにログインするURL'
const MAIL_ADDRESS = 'ログイン用のアドレス';
const PASSWORD = 'ログインするアドレスのパスワード';
const WAITING_TIME = 5000;
!(async() => {
try {
// 1. ブラウザを起動
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
'Accept-Language': 'ja,en-US;q=0.9,en;q=0.8'
})
// 2. ログイン
await signInByAmazonAccount(page);
// 3. ハイライトを取得
let result = await getAllBooksInformation(page);
// 4. ブラウザを閉じる
browser.close();
// 5. 取得したハイライトを表示
console.log(JSON.stringify(result, null, ' '));
return;
} catch(e) {
console.error(e);
}
})()
おおまかな処理の流れはソースコード中のコメントのとおりですが、注意点としてDOMを指定するためのセレクタ群をSELECTORSに定義しています。
module.exports.SELECTORS = {
SIGN_IN: {
// querySelector()と同じようにDOMを指定可能
EMAIL: '#ap_email',
︙
}
︙
}
1. ブラウザを起動
ログイン画面に遷移するための準備をします。
const browser = await puppeteer.launch();
- puppeteerが操作するブラウザを起動します。
※PCにChromeがインストールされていなくても、puppeteerインストール時にChrome(正確にはChromium)がダウンロードされるのでpuppeteerは動作します。 - 引数に起動時のオプションを指定できます。
- 他のオプションとしてはブラウザの縦横の長さを指定できたり、自動操作を遅くしたり、開発ツールを開いたり、(備え付けでない)PCにインストールされたChromeを使うようにするものなど多数用意されています。
const page = await browser.newPage();
- newPage()というメソッド名ですが、Chromeのタブを追加する動作に等しいです。newPage()を呼ぶたびに新しくタブが追加されます。
await page.setExtraHTTPHeaders({
'Accept-Language': 'ja,en-US;q=0.9,en;q=0.8'
})
- ヘッドレスモードではAccept-Languageが自動で設定されないので、明示的に設定する必要があります。
参考:https://github.com/GoogleChrome/puppeteer/issues/665#issuecomment-356634721
2. ログイン
ハイライトを見るためにAmazonアカウントでログインしなければなりません。(※通常のAmazonログイン用URLとは違うので注意してください)
また、Puppeteerが操作するChromeではユーザー情報を保持してくれないようなので、クローリングする度にログインする必要があります。
async function signInByAmazonAccount(page){
// === ログイン画面(その1) ===
// ページ遷移
// オプションはDOMContentLoadedイベントが発火してから次の処理に入るためのものです。
await page.goto(KINDLE_SIGN_IN_URL, {waitUntil: "domcontentloaded"});
// アドレスとパスワードを入力
await page.type(SELECTORS.SIGN_IN.EMAIL, MAIL_ADDRESS);
await page.type(SELECTORS.SIGN_IN.PASSWORD, PASSWORD);
// ログインボタンをクリック
await page.click(SELECTORS.SIGN_IN.SUBMIT);
// クリックしてから次の画面のDOMContentLoadedイベントが発火するまで待機
// イベント発火まで6秒以上かかる場合はタイムアウトとみなします。
await page.waitForNavigation({timeout: 60000, waitUntil: "domcontentloaded"});
// === ログイン画面(その2) ===
await page.type(SELECTORS.SIGN_IN.PASSWORD, PASSWORD);
await page.click(SELECTORS.SIGN_IN.SUBMIT);
// ここでもDOMContentLoadedイベントが発火するまで待機するべきですが、
// DOMContentLoadedイベントをうまく検知できないので一定時間待つことで対応します。
await page.waitFor(WAITING_TIME);
}
GUIのブラウザで普段行っていることをプログラム化しただけですので、していることをイメージするのは容易だと思います。
アドレスとパスワードを入力してログインした直後の画面で、もう一度パスワードを入力してログインをしているのは、なぜか2回パスワードを入力しないとログインさせてもらえない不思議なUIに因るものです。
3. ハイライトを取得
ログインが済むとキャプチャのような画面に遷移します。右上の★★にはユーザー名が表示されています。
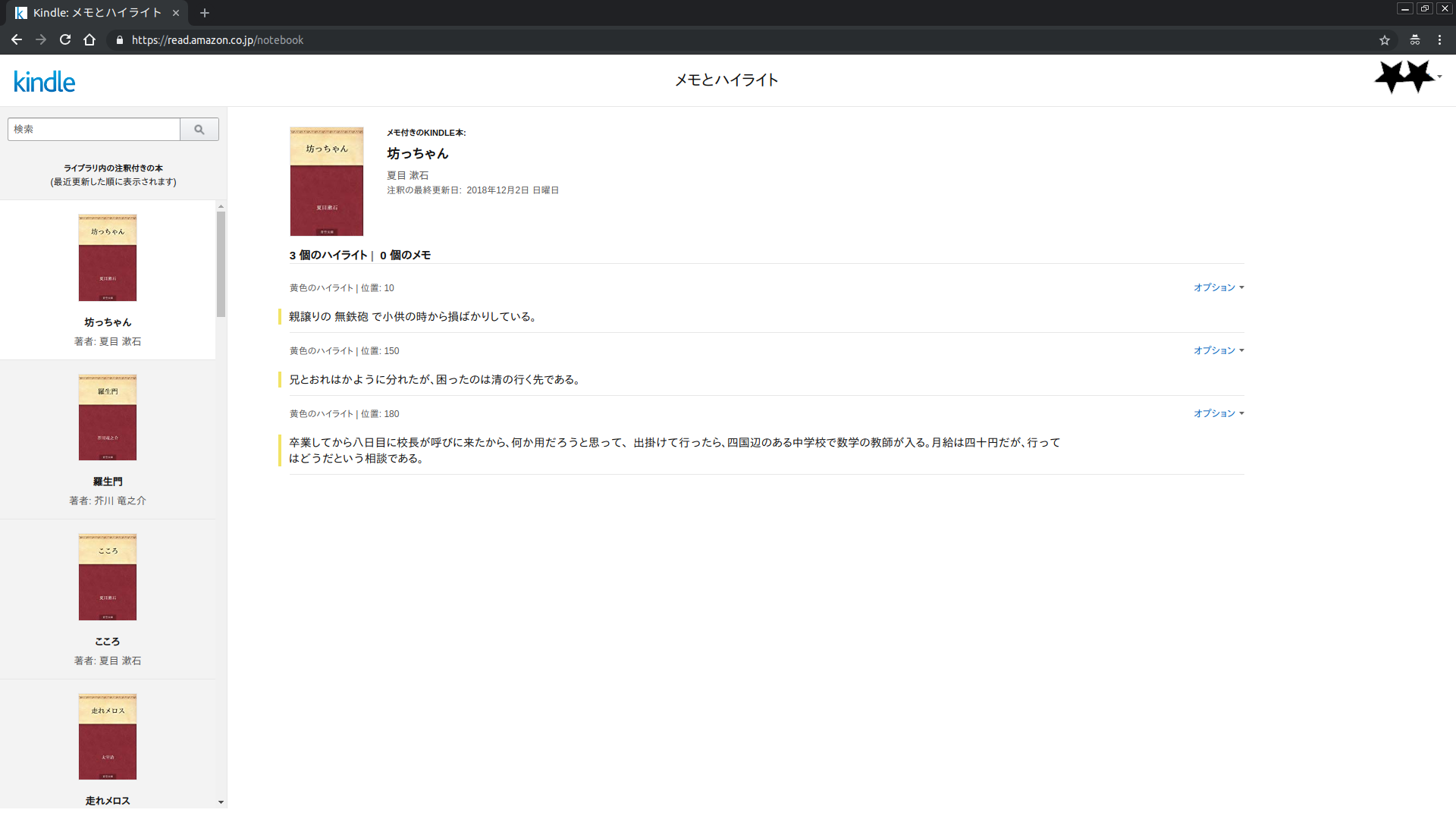
左のレーンから本を選んでクリックするとその右にハイライトが表示される仕掛けです。
したがって、レーンから本をクリック → ハイライトを取得 → レーンから(次の)本をクリック → …
のサイクルを回すことで自分がハイライトしたすべての情報を取得することができます。
実装は次のようになります。
async function getAllBooksInformation(page){
// 本の全量を知るために本のDOMをすべて取得
let books = await page.$$(SELECTORS.MAIN.BOOKS);
let res = [];
if(!books || books.length <= 0){return res;}
for(i = 0; i < books.length; i++){
// レーンから本を順番にクリックし、ハイライトを取得
res.push(await getBookInformation(books[i], page));
}
return res;
}
async function getBookInformation(book, page){
// 本をクリックし、ハイライトが表示されるまで待機
// 表示される情報は変わるが、DOM自体は変わらないためかDOMContentLoadedイベントは発火しない。
await book.click();
await page.waitFor(WAITING_TIME);
// ハイライトに加え、Amazonの購入ページのURL、 タイトル、著者名も取得
let url = await page.$eval(SELECTORS.MAIN.URL, asin => {
return asin.href
});
let title = await page.$eval(SELECTORS.MAIN.TITLE, title => {
return title.textContent;
});
let auther = await page.$eval(SELECTORS.MAIN.AUTHER, auther => {
return auther.textContent;
});
let highlights = await page.$$eval(SELECTORS.MAIN.HIGHLIGHTS, highlights => {
return highlights.map(highlight => {return highlight.textContent});
});
return {
url: url,
title: title,
auther: auther,
highlights: highlights,
};
}
4. Page.$evalとPage.$の使い分け
DOMの操作をする$evalと$、2つのメソッドの使い分けで躓いたので、軽く触れたいと思います。
※コードの書き方なんかドキュメント読めばわかる!という方は実行結果まで進んでください。
違いは?
Page.$evalとPage.$どちらもセレクタで任意のDOMを指定して操作できます。名前は似ていますが、返却されるオブジェクトの型が異なるので用途によって使い分けるとコードがスッキリすると思います。
では、Serializableを返却するpage.$evalから。
1. page.$eval(selector, pageFunction[, ...args])
今回の実装では本のURLやタイトルを取得する際に使っています。
let url = await page.$eval(SELECTORS.MAIN.TITLE, asin => {
return asin.textContent;
});
このメソッドはSeiralizableクラスを返却するので、DOMが持っているtextContentや属性の情報を取得したい場合はこちらで十分だと思います。
しかし、関数の情報は失われます。この問題を解決するのがElementHandleクラスを返却するpage.$です。
2. page.$(selector)
ElementHandleクラスを返却し、click()などのイベントで発火する関数の情報も保持されます。
今回の実装では使っていませんが、例えば次のように使うことができます。
// (例)page.$を使ってログインボタンをクリック
await page.$(SELECTORS.SIGN_IN.SUBMIT, button => {
button.click();
});
ただし、Page.$を使えばイベントで発火する情報が保持されましたが、このメソッドでtextContentなどの情報が失われたわけではありません。
Page.$を使う場合は直接Serializableを返せないため、次のように一度別の変数で受けてやる必要があり、第2引数の意味がなくなってしまっているので冗長かつ不自然に見えますが、Page.$を使って取得することは可能です。
// (例)page.$を使ってtextContentを取得
let tempTitle = await page.$(SELECTORS.MAIN.TITLE, button => button);
let title = tempTitle.textContent;
複数のDOMを操作する
ここまで説明してきたPage.$evalとPage.$はどちらも任意のDOMを操作できますが、いずれも該当DOM複数があった場合は一番最初に見つけたDOMを対象とします。該当DOMすべてを対象とするメソッドはそれぞれ
page.$$eval(selector, pageFunction[, ...args])
page.$$(selector)
が用意されています。ハイライトを取得するところと、クリックするためのDOMを取得するところで使っています。使い方はそれぞれpage.$eval、page.$と似ていますが、page.$$evalに渡す関数の第二引数がリストになっていることに注意してください。各DOMから同じプロパティを取得するためにはmapしてやる必要があります。
let highlights = await page.$$eval(SELECTORS.MAIN.HIGHLIGHTS, highlights => {
return highlights.map(highlight => {
return highlight.textContent});
});
let books = await page.$$(SELECTORS.MAIN.BOOKS);
結局どう使い分けるべきか?
Page.$の方が汎用性が高そうですが、上で述べたように文字情報を取得するのは変だと思うので、文字情報を取得するときはPage.$valを、イベントドリブンな関数を使う場合はPage.$でDOMを操作するのが良いと思います。
実行結果
これを実行すると次の結果を得られました。
[
{
"url": "https://www.amazon.co.jp/dp/B009IXJVVO",
"title": "坊っちゃん",
"auther": "夏目 漱石",
"highlights": [
"親譲りの 無鉄砲 で小供の時から損ばかりしている。",
"兄とおれはかように分れたが、困ったのは清の行く先である。",
"卒業してから八日目に校長が呼びに来たから、何か用だろうと思って、出掛けて行ったら、四国辺のある中学校で数学の教師が入る。月給は四十円だが、行ってはどうだという相談である。"
]
},
{
"url": "https://www.amazon.co.jp/dp/B009IWXL8E",
"title": "羅生門",
"auther": "芥川 竜之介",
"highlights": [
"雨は、羅生門をつつんで、遠くから、ざあっと云う音をあつめて来る。夕闇は次第に空を低くして、見上げると、門の屋根が、斜につき出した 甍 の先に、重たくうす暗い雲を支えている。",
"どうにもならない事を、どうにかするためには、手段を選んでいる 遑 はない。",
"下人は、手段を選ばないという事を肯定しながらも、この「すれば」のかたをつけるために、当然、その後に来る可き「 盗人 になるよりほかに仕方がない」と云う事を、積極的に肯定するだけの、勇気が出ずにいたのである。",
"下人の眼は、その時、はじめてその死骸の中に 蹲っている人間を見た。 檜皮色 の着物を着た、背の低い、 瘦 せた、 白髪頭 の、猿のような老婆である。"
]
},
{
"url": "https://www.amazon.co.jp/dp/B009IXKPVY",
"title": "こころ",
"auther": "夏目 漱石",
"highlights": [
"幸いにして先生の予言は実現されずに済んだ。",
"「若い時っていつ頃ですか」と私が聞いた。",
"私は想像で知っていた。しかし事実としては知らなかった。"
]
},
{
"url": "https://www.amazon.co.jp/dp/B009IY56Q2",
"title": "走れメロス",
"auther": "太宰 治",
"highlights": [
"メロスには竹馬の友があった。セリヌンティウスである。",
"中途で倒れるのは、はじめから何もしないのと同じ事だ。",
"ぬ。私は、信頼に報いなければならぬ。いまはただその一事だ。走れ!"
]
}
︙
]
感想
私のようなクローラ初心者でも作ることができたので、かなり扱いやすいライブラリだと感じました。
今回は
- テキスト入力
- クリック
- ページから文字列取得
の処理に終始しクローラを作りましたが、他にも
- DOM単位でキャプチャを撮る
- ページをまるごとpdf化
- 複数の(Chromeの)タグを操作
- iPhoneを始めとする各種モバイル端末エミュレータでの実行
などなど色々便利そうな操作も可能です。
画面の差分検知の自動化や、(主にPCで使う)web アプリケーションと(モバイル端末の)アプリ両方の開発を進めているプロジェクトでのE2Eテストに重宝すると思います。
また、pythonに移植したpypuppeteerなるものもあるらしいのでpythonメインの方にもぜひ触ってみてほしいです。
本エントリはここまでです。最後までお読みいただきありがとうございました。