SQL Serverにはsys.tablesやsys.objectsといったカタログ ビュー (Transact-SQL)というものが用意されています
カタログ ビューは、SQL Server データベース エンジンによって使用される情報を返します。
とあるように、カタログビューを使う事で、テーブル、列を始めとするSQL Serverが管理する各種情報を参照することが可能です
このカタログビューを使って、テーブル一覧や、列の情報をSQLによって取得できるようになります
※以下SQLを実行しているのは、Microsoftから提供されている Northwind データベースです
作成方法は、最後に記載しておきます
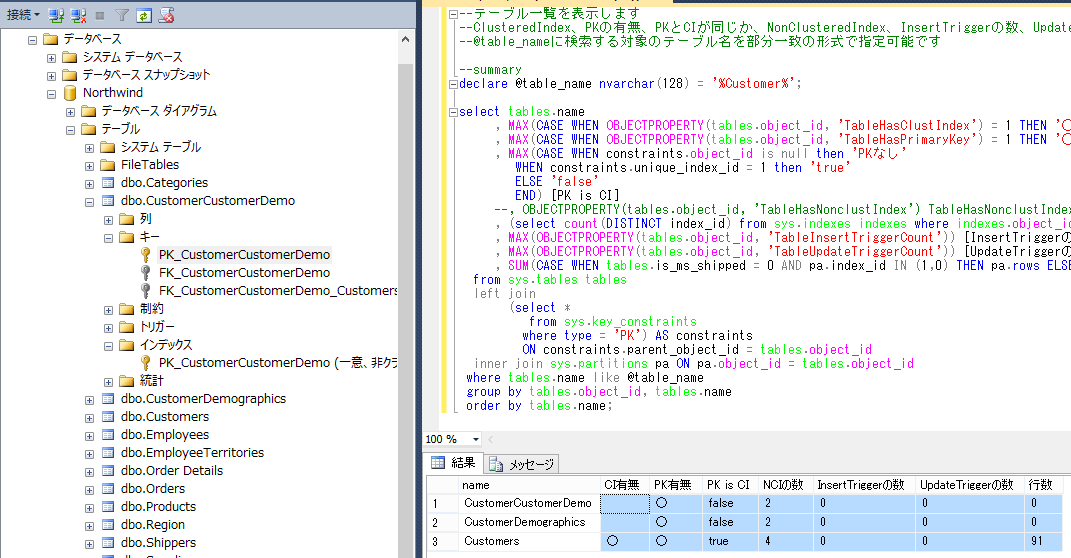
テーブルの一覧
--テーブル一覧を表示します
--ClusteredIndex、PKの有無、PKとCIが同じか、NonClusteredIndex、InsertTriggerの数、UpdateTriggerの数、レコード数を表示します
--@table_nameに検索する対象のテーブル名を部分一致の形式で指定可能です
--summary
--ここにテーブル名の検索条件を指定します
declare @table_name nvarchar(128) = '%Customer%';
select tables.name
, MAX(CASE WHEN OBJECTPROPERTY(tables.object_id, 'TableHasClustIndex') = 1 THEN '○' ELSE '' END) [CI有無]
, MAX(CASE WHEN OBJECTPROPERTY(tables.object_id, 'TableHasPrimaryKey') = 1 THEN '○' ELSE '' END) [PK有無]
, MAX(CASE WHEN constraints.object_id is null then 'PKなし'
WHEN constraints.unique_index_id = 1 then 'true'
ELSE 'false'
END) [PK is CI]
--, OBJECTPROPERTY(tables.object_id, 'TableHasNonclustIndex') TableHasNonclustIndex
, (select count(DISTINCT index_id) from sys.indexes indexes where indexes.object_id = tables.object_id and index_id <> 1) [NCIの数]
, MAX(OBJECTPROPERTY(tables.object_id, 'TableInsertTriggerCount')) [InsertTriggerの数]
, MAX(OBJECTPROPERTY(tables.object_id, 'TableUpdateTriggerCount')) [UpdateTriggerの数]
, SUM(CASE WHEN tables.is_ms_shipped = 0 AND pa.index_id IN (1,0) THEN pa.rows ELSE 0 END) [行数]
from sys.tables tables
left join
(select *
from sys.key_constraints
where type = 'PK') AS constraints
ON constraints.parent_object_id = tables.object_id
inner join sys.partitions pa ON pa.object_id = tables.object_id
where tables.name like @table_name
group by tables.object_id, tables.name
order by tables.name;
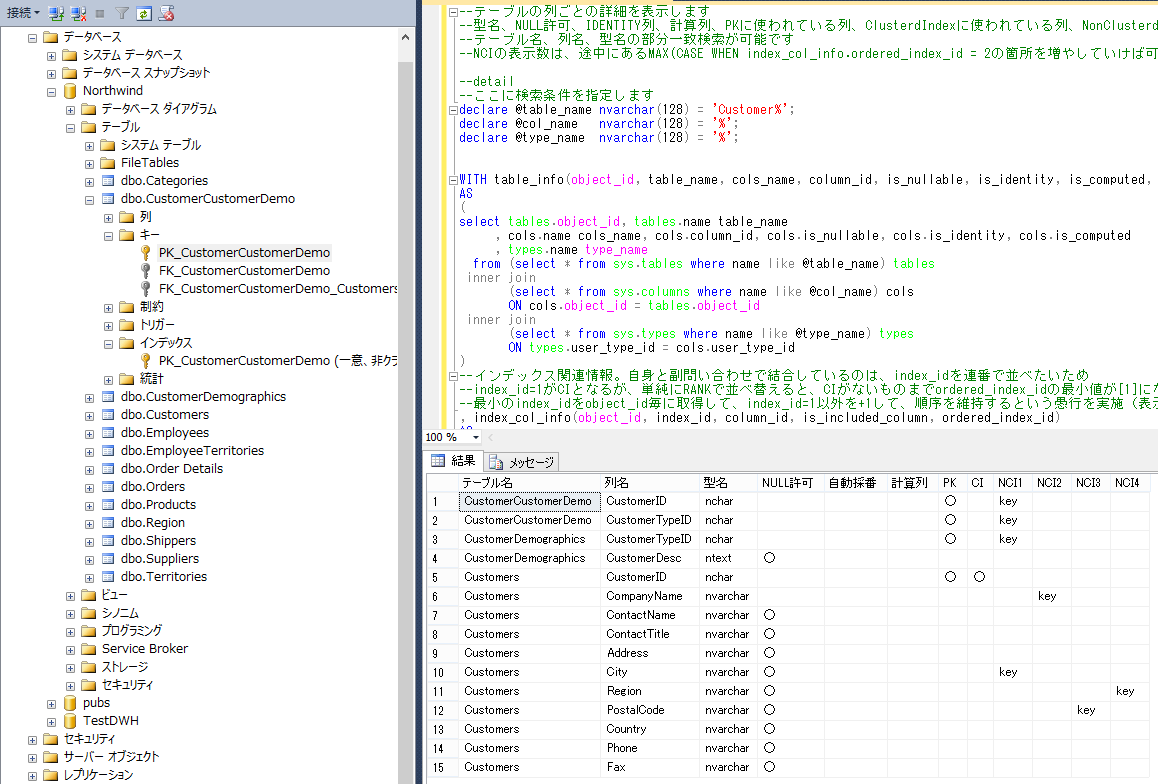
列情報の一覧
--テーブルの列ごとの詳細を表示します
--型名、NULL許可、IDENTITY列、計算列、PKに使われている列、ClusterdIndexに使われている列、NonClusterdIndex(keyがインデックスキーで、incが付加列)の情報を一覧で表示します
--テーブル名、列名、型名の部分一致検索が可能です
--NCIの表示数は、途中にあるMAX(CASE WHEN index_col_info.ordered_index_id = 2の箇所を増やしていけば可能ですが、きれいなやり方ではないです
--detail
--ここにテーブル名、列名の検索条件を指定します
declare @table_name nvarchar(128) = '%Customer%';
declare @col_name nvarchar(128) = '%';
declare @type_name nvarchar(128) = '%';
WITH table_info(object_id, table_name, cols_name, column_id, is_nullable, is_identity, is_computed, type_name)
AS
(
select tables.object_id, tables.name table_name
, cols.name cols_name, cols.column_id, cols.is_nullable, cols.is_identity, cols.is_computed
, types.name type_name
from (select * from sys.tables where name like @table_name) tables
inner join
(select * from sys.columns where name like @col_name) cols
ON cols.object_id = tables.object_id
inner join
(select * from sys.types where name like @type_name) types
ON types.user_type_id = cols.user_type_id
)
--インデックス関連情報。自身と副問い合わせで結合しているのは、index_idを連番で並べたいため
--index_id=1がCIとなるが、単純にRANKで並べ替えると、CIがないものまでordered_index_idの最小値が[1]になってしまう
--最小のindex_idをobject_id毎に取得して、index_id=1以外を+1して、順序を維持するという愚行を実施(表示時に色々面倒になるので、ここで終わらせたい)
, index_col_info(object_id, index_id, column_id, is_included_column, ordered_index_id)
AS
(
select a.object_id, a.index_id, a.column_id, a.is_included_column
, (CASE WHEN b.min_index_id = 1 THEN 0 ELSE 1 END) + b.ordered_index_id as ordered_index_id
from sys.index_columns a
inner join
(select object_id
, index_id
, RANK() OVER (PARTITION BY object_id ORDER BY index_id) ordered_index_id
, (select MIN(index_id) from sys.index_columns c where c.object_id = d.object_id) min_index_id
from sys.index_columns d
group by object_id, index_id) AS b
on b.object_id = a.object_id and b.index_id = a.index_id
)
select MAX(tables.table_name) [テーブル名]
, MAX(tables.cols_name) [列名]
, MAX(tables.type_name) [型名]
, MAX(CASE WHEN tables.is_nullable = 1 THEN '○' ELSE '' END) [NULL許可]
, MAX(CASE WHEN tables.is_identity = 1 THEN '○' ELSE '' END) [自動採番]
, MAX(CASE WHEN tables.is_computed = 1 THEN '○' ELSE '' END) [計算列]
, MAX(CASE WHEN index_col_info_for_pk.object_id IS NOT NULL and tables.column_id = index_col_info_for_pk.column_id THEN '○' ELSE '' END) PK
, MAX(CASE WHEN index_col_info.ordered_index_id = 1 THEN '○'
ELSE '' END) CI
--この下を増やしていけば何個でも表示可能だが、ホントは検索対象に引っかかったNCIの数だけに絞ったほうが見やすいと思う
, MAX(CASE WHEN index_col_info.ordered_index_id = 2 AND index_col_info.is_included_column = 0 THEN 'key'
WHEN index_col_info.ordered_index_id = 2 AND index_col_info.is_included_column = 1 THEN 'inc'
ELSE '' END) NCI1
, MAX(CASE WHEN index_col_info.ordered_index_id = 3 AND index_col_info.is_included_column = 0 THEN 'key'
WHEN index_col_info.ordered_index_id = 3 AND index_col_info.is_included_column = 1 THEN 'inc'
ELSE '' END) NCI2
, MAX(CASE WHEN index_col_info.ordered_index_id = 4 AND index_col_info.is_included_column = 0 THEN 'key'
WHEN index_col_info.ordered_index_id = 4 AND index_col_info.is_included_column = 1 THEN 'inc'
ELSE '' END) NCI3
, MAX(CASE WHEN index_col_info.ordered_index_id = 5 AND index_col_info.is_included_column = 0 THEN 'key'
WHEN index_col_info.ordered_index_id = 5 AND index_col_info.is_included_column = 1 THEN 'inc'
ELSE '' END) NCI4
from table_info tables
left join index_col_info ON index_col_info.object_id = tables.object_id and index_col_info.column_id = tables.column_id
left join
(select *
from sys.key_constraints
where type = 'PK') AS constraints
ON constraints.parent_object_id = tables.object_id
left join index_col_info index_col_info_for_pk
ON index_col_info_for_pk.object_id = tables.object_id
and index_col_info_for_pk.index_id = constraints.unique_index_id
group by tables.table_name, tables.column_id
order by tables.table_name, tables.column_id;
改めてカタログビュー
上記のデータを表示するために、sys.objectsを始めとするカタログビューを使用しています
今回使用したカタログビューと関連情報について簡単に説明します
概要
sys.objectsにsqlserverが管理しているだいたいのものが入っている感じです
このキーが[object_id]で、他のsys.XXXはこの[object_id]で参照します
sys.XXXによっては、列の定義が[sys.objects]を継承しているものもあります
なのでまずは、[sys.objects]をざっくり眺めて、やりたいことに関連ありそうなsys.XXXを
オブジェクト カタログ ビュー (Transact-SQL)
から探すと、意外と簡単に目的達成できそうです
sys.objects (Transact-SQL)
データベース内で作成されるユーザー定義のスキーマ スコープ オブジェクトごとに 1 行のデータを格納します。
DDL トリガーはスキーマ スコープではないため、sys.objects では表示されません。 DML と DDL の両方を含むすべてのトリガーは、sys.triggers に格納されます。 sys.triggers には、さまざまな種類のトリガーの名前スコープ ルールを混在させて格納できます。
sys.tables (Transact-SQL)
sys.objects から継承した列を含む
SQL Server 内のユーザー テーブルごとに 1 行のデータを返します。
sys.columns (Transact-SQL)
ビューやテーブルなど、列を持つオブジェクトの列ごとに 1 行のデータを返します。 以下に、列を持つオブジェクトの種類の一覧を示します。
- テーブル値アセンブリ関数 (FT)
- インライン テーブル値 SQL 関数 (IF)
- 内部テーブル (IT)
- システム テーブル (S)
- テーブル値 SQL 関数 (TF)
- ユーザー テーブル (U)
- ビュー (V)
今回使った列
object_id:この列が属するオブジェクトのID(sys.objectsを参照する)
column_id:列のID。オブジェクト内で一意。列IDは連続した値にならないことがある
system_type_id:列のシステム型のID
user_type_id:ユーザーが定義した列の型のID(基本的には、system_type_idと同じものがはいる?)型の名前を取得するには、sys.types (Transact-SQL)カタログビューと結合する
is_nullable
is_identity
is_computed
sys.types (Transact-SQL)
システム型とユーザー定義の型ごとに 1 行のデータを格納します。
system_type_id:243がユーザ定義型(と思われる)
user_type_id:データーベース内で一意。システムデータ型の場合は、user_type_id = system_type_idとなる
sys.indexes (Transact-SQL)
テーブル、ビュー、テーブル値関数など、テーブル オブジェクトのインデックスまたはヒープごとに 1 行のデータを格納します。
sys.index_columns (Transact-SQL)
sys.indexes インデックスまたは順序付けられていないテーブル (ヒープ) の一部である列ごとに 1 つの行を含みます。
index_id:列が定義されているインデックスのID
index_column_id:インデックス列の ID です。 index_column_id は、index_id 内でのみ一意です。(index_id内でのみ一意)
column_id:object_id 内の列の ID です。column_id は、object_id 内でのみ一意です。(sys.columnsと一致する)
is_descending_key:1:降順
is_included_column:1:付加列
OBJECTPROPERTY (Transact-SQL)
指定したプロパティに対する値を返してくれる
よくわらかないのでサンプルを記載しておきます
select tables.name
, CASE OBJECTPROPERTY(tables.object_id, 'TableHasClustIndex') = 1 THEN '○' ELSE '' END [CI有無]]
from sys.tables tables
order by tables.name;
[TableHasClustIndex]など、指定するプロパティを変更すれば、そのオブジェクトの設定値が取得できます
色んなプロパティがありますが、OBJECTPROPERTY (Transact-SQL)を参照してください
sys.key_constraints (Transact-SQL)
主キー制約または一意制約であるオブジェクトごとに 1 行のデータを格納します。 sys.objects.type が PK と UQ のオブジェクトが含まれます。
unique_index_id:この制約を設定するために作成された、親オブジェクトに対応する一意インデックスの ID。
parent_object_id:sys.objectsに含まれている 親のID
共通テーブル式(CTE)
各ステートメントの実行スコープ内で定義される一時結果セットと考えることができます
誤解を与えかねないですが、簡単に記載すると、そのSQL内で参照可能なViewを定義するようなものです
ケース別による使い方も紹介されています
WITH common_table_expression (Transact-SQL)
データベース オブジェクト
Microsoft SQL Server Compact データベースで定義されている、いくつかのデータベース オブジェクトの最大サイズ制限を示しています。
テーブルのレコード数とか簡単にみたいなと思う事はよくあって、毎回調べたりしてました(sys.XXXってなんだか面倒な感じがしていたので)
でも見てみるとそこまで面倒ではなかったので、ここを参考にいろいろ試して貰えればと思います
参考:方法 : サンプル データベースをインストールする
こちらの手順に従えば基本OKですが、SQL Server 2012以上に入れる場合の注意事項(sp_dboptionが使えないので、ALTER DATABASEにするだけですが)ついて手順とともに簡単にまとめておきます
- Northwind and pubs Sample Databases for SQL Server 2000の Web サイトにアクセスして、インストーラをダウンロード
- インストールを実行するとコンピューターのルート フォルダーに、SQL Server 2000 Sample Databases フォルダーが追加されます (C:\SQL Server 2000 Sample Databases など)
- SSMSを開き、DBを作成したいSQL Serverに接続
- フォルダー内の、instnwnd.sqlと、instpubs.sqlをSSMSで開く
- それぞれのSQL内にsp_dboptionというコマンドがありますが、2008までしか使えないので、以下のように修正
/*
exec sp_dboption 'Northwind','trunc. log on chkpt.','true'
exec sp_dboption 'Northwind','select into/bulkcopy','true'
*/
alter database Northwind set recovery simple
/*
execute sp_dboption 'pubs' ,'trunc. log on chkpt.' ,'true'
*/
alter database pubs set recovery simple
※設定しているコマンドの意味
'trunc. log on chkpt.','true'
SQL Server 2000 で起動し、trunc. log on chkpt. オプションに true を指定すると、データベースの復旧モデルは SIMPLE に設定されます。オプションに false を指定すると、復旧モデルは FULL に設定されます。
'select into/bulkcopy','true'
Microsoft SQL Server 2000 から使用を開始し、データベースの現在の復旧モデルが FULL に設定されている場合、select into/bulkcopy option を使用すると復旧モデルが BULK_LOGGED に再設定されます。復旧モデルを適切な方法で変更するには、ALTER DATABASE ステートメントの SET RECOVERY 句を使用します。
修正したSQLを実行すると、データベースが作成されます