目的
- データエンジニアにとってテーブル毎のサイズ(使用容量)を見たいニーズが多いと思いますが、DatabricksのUnity Catalogで管理するテーブルに対してサイズを一覧表示する方法です。
- system.information_schema.tablesのstorage_pathと、データを保管するAzure Data Lake Storage Gen2 (ADLS)のPythonライブラリを使用してサイズを算出しデータフレームに表示します。
動作環境
下記の環境で動作を確認しています。
- Databricks ノートブックのサーバーレス コンピューティング
- サーバーレス クライアント イメージ 2 (Azureライブラリのpip installは不要です)
- 実行するとAzure DatabricksやADLSの操作課金が発生しますのでご注意下さい。
- ストリーミングテーブルは表示されません(storage_pathがnullのため)。
実装
(1) ノートブックのサーバーレス コンピューティングを選択
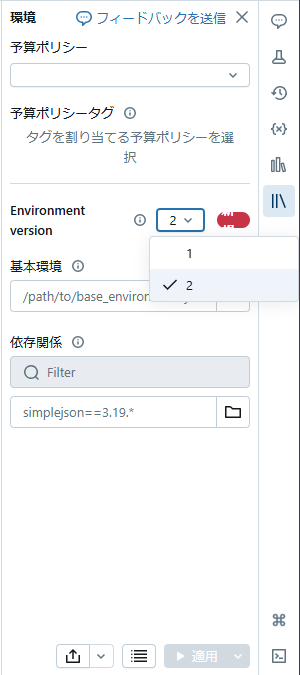
(2) サーバーレス クライアント イメージ 2 を選択し適用する
(3) ADLSのアカウント名、コンテナ名、SASトークンを設定しコードを実行
import re
from azure.storage.filedatalake import DataLakeServiceClient
from pyspark.sql.functions import udf
from pyspark.sql.types import DoubleType
# 環境設定
account_name = "your account name"
file_system_name = "your container name"
# sas_token
credential = "your sas token"
# 抽出するテーブル一覧の条件をカスタマイズして指定(下記はsamplesカタログを除外)
list_table_query = "SELECT * FROM system.information_schema.tables where table_catalog != 'samples' and storage_path is not null"
def extract_blob_path(url):
match = re.search(r"abfss://[^/]+/(.+)", url)
if match:
return match.group(1)
return None
def get_total_size_gb_of_folder(service_client, file_system_name, folder_path):
total_size = 0
paths = service_client.get_file_system_client(file_system_name).get_paths(path=extract_blob_path(folder_path))
for path in paths:
if not path.is_directory:
total_size += path.content_length
return round(total_size / (1024 ** 3), 2) # Convert bytes to GB
# サイズ算出関数をUDFとして宣言
@udf(returnType=DoubleType())
def get_folder_size_udf(folder_path):
return get_total_size_gb_of_folder(service_client, file_system_name, folder_path)
service_client = DataLakeServiceClient(account_url=f"https://{account_name}.dfs.core.windows.net", credential=credential)
tables_df = spark.sql(list_table_query)
tables_df = tables_df.withColumn("total_size_GB", get_folder_size_udf(tables_df["storage_path"]))
# サイズの降順でデータフレームを表示
display(tables_df.select("table_catalog", "table_schema", "table_name", "total_size_GB", "storage_path").sort("total_size_GB", ascending=False))
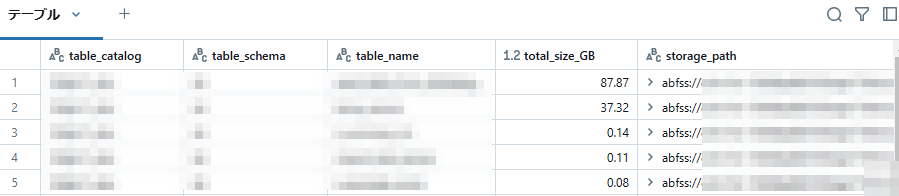
(4)下記のようにGB単位のサイズを確認することができます。
使用状況を確認したり、サイズや容量課金が大きいテーブルを特定することができます。