概要
SNSにおけるコンテンツ検索にて、検索を行うユーザとソーシャルグラフ的に近いユーザが投稿したコンテンツを優先的に提示するパーソナライズ検索をElasticsearchで実現する方法について考えます。
グラフクラスタリングの結果をソート時の関数に使用することで、直接つながったユーザのコンテンツだけでなく、2次以上の距離のあるユーザのコンテンツも優先的に提示できるようにします。
SNSのソーシャルグラフのデータはなかなかオープンデータとして公開されていないので、科学論文の著者の共著・引用関係のデータを使用してパーソナライズ検索のデモを試作してみます。
環境
| 使用したソフトウェアなど | version | 備考 |
|---|---|---|
| Elasticsearch | 5.1.1 | |
| Citation-network | v1 | https://cn.aminer.org/citation |
| python | 3.4 | |
| python-louvain | 0.5 |
使用するソーシャルグラフのデータ
今回は、下記にてオープンデータとして公開されている科学論文の著者の共著・引用関係のデータCitation-network V1を利用することにします。
https://cn.aminer.org/citation
Citation-network V1には、下記のような形式で論文の
「タイトル、著者、公開年、分野、番号、引用している論文の番号、アブストラクト」が載っています。
# *Information geometry of U-Boost and Bregman divergence (タイトル)
# @Noboru Murata,Takashi Takenouchi,Takafumi Kanamori,Shinto Eguchi (著者)
# t2004 (論文を公開した年)
# cNeural Computation (分野)
# index436405 (論文の番号)
# %94584 (引用している論文の番号)
# %282290
# %605546
# %620759
# %564877
# %564235
# %594837
# %479177
# %586607
論文の共著・引用関係から、著者同士のソーシャルグラフを生成します。参考
なお、著者が書いた論文同士の関係から、著者同士の関係にマッピングしていることにご注意ください。
グラフクラスタリング
図1のように著者Aが何らかの単語という単語(例:computer)で検索を行うときに、ソーシャルグラフ的に近い著者B,D,C,Eあたりの論文が優先的に提示されるようにします。
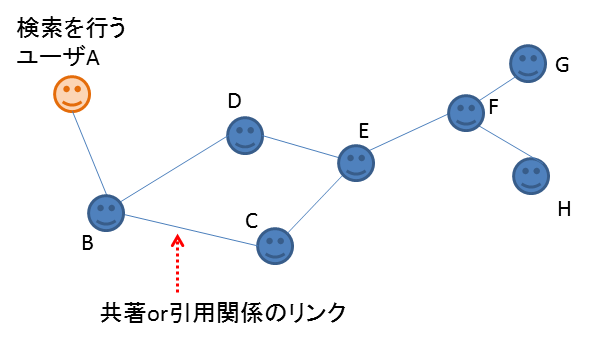
図1.共著・引用関係のネットワーク
グラフクラスタリングの結果をソート時の関数に使用することで、直接つながった著者の論文だけでなく、2次以上の距離のある著者の論文も優先的に提示できるようにします。
クラスタリングとは、似た性質を持つデータをまとめて、いくつかのグループに分けることです。
グラフクラスタリングでは、リンク関係に基づいてデータのグループ分けを行います。
グラフクラスタリングに関する細かい話は、このあたりの記事などが参考になると思います。
Citation-network V1から生成したソーシャルグラフに対して、louvain法でクラスタリングします。
クラスタリング結果は下記のようになりました。

python-louvainでのクラスタリングで、3時間くらいかかりました。
「system modeling」「wireless newtwork」「nonlinear system control」とかが大きな分野になっているみたいですね。あと、「fuzzy」とかも結構大きな分野になっているのは1990年代の論文が多いからですかね・・・
クラスタの分野のタグはクラスタに含まれる論文のタイトルで使用されている単語のTF・IDF値をもとに決めています。参考
Elasticsearchのデータ構造
下記のようなインデックスを作ります。
authorsインデックス
「_id」に著者名
「class」にlouvain法で求めた著者のクラスタ番号が入ります。
curl -XPUT localhost:9200/authors -d '
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"user": {
"_all": {
"enabled": false
},
"_source": {
"enabled": true
},
"_routing": {},
"properties": {
"class": {
"type": "string",
"index": "not_analyzed",
"store": "yes"
}
}
}
}
}'
papersインデックス
論文のデータが入ります。
classに第一著者が所属するクラスタが入る点にご注意ください。
curl -XPUT localhost:9200/papers -d '
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"paper": {
"_all": {
"enabled": false
},
"_source": {
"enabled": true
},
"_routing": {},
"properties": {
"class": {
"type": "string",
"index": "not_analyzed",
"store": "yes"
},
"title": {
"type": "string",
"store": "yes"
},
"first_author": {
"type": "string",
"index": "not_analyzed",
"store": "yes"
},
"authors": {
"type": "string",
"store": "yes"
},
"venue": {
"type": "string",
"store": "yes"
},
"abstract": {
"type": "string",
"store": "yes"
},
"year": {
"type": "string",
"store": "yes"
},
"references": {
"type": "string",
"store": "yes"
}
}
}
}
}'
検索クエリ
スコア検索式
a \times wordScore + (1.0 - a) \times clusterScore
wordScore: クエリとドキュメントに含まれる単語の関連度のスコア
clusterScore:クラスタの一致度によるスコア。検索を行うユーザと、論文の第一著者のクラスタが一致していれば1.0, 一致していなければ0.0となる。
a: wordScoreとclusterScoreのどちらを重視するかを決める値です。とりあえず0.2にしました。(clusterScoreを重視)
実際のクエリ
検索を行うユーザは、Citation-network V1に含まれる著者とします。
{{検索を行うユーザ名}}にauthorsインデックスに含まれる著者名を設定します。
{{検索を行うユーザ名}}をもとに、Terms Lookupで著者が所属するクラスタ番号を取得しています。
function_scoreで、論文のクラスタ番号と{{検索を行うユーザ名}}のクラスタ番号が一致しているかに応じたスコアを付けています。
{
"size": 10,
"from": 0,
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "{{検索したいワード}}",
"fields": ["title", "abstract", "venue"]
}
},
"functions": [
"filter": {
"terms": {
"class": {
"index": "authors",
"type": "author",
"id": "{{検索を行うユーザ名}}",
"path": "class"
}
}
},
"script_score": {
"script": "0.2 * _score + (1.0 - 0.2) * 1.0;"
}
}, {
"script_score": {
"script": "0.2 * _score;"
}
}],
"score_mode": "first",
"boost_mode": "replace"
}
}
}
例
たとえば、network関連のクラスタに所属するHon_F._Liさんが、
検索ワード「evaluation」で検索すると、下記のようにnetwork関連の性能評価の論文がトップのほうに出てきます。
# 上位五件の論文タイトル
"title": "Compositional performance modelling with the TIPPtool",
"title": "Efficient steady-state analysis of second-order fluid stochastic Petri nets",
"title": "Cell/packet loss behavior in a statistical multiplexer with bursty input",
"title": "The available capacity of a privately owned workstation environment",
"title": "Short communication: Product-forms and functional rates",
そして、database関連のクラスタに所属する Morris_Changさんが、
検索ワード「evaluation」で検索すると、下記のようにdatabase関連の性能評価の論文がトップのほうに出てきます。
# 上位五件の論文タイトル
"title": "Measuring the effects of distributed database models on transaction availability measures",
"title": "Special issue: high speed networks and their performance",
"title": "Performance analysis of centralized databases with optimistic concurrency control",
"title": "Overload effects and their prevention",
"title": "Performance comparison of IO shipping and database call shipping: schemes in multisystem partitioned databases",
titleにevaluationって入ってないですが、abstractとvenueに入ってます。。。
実験のために作成したスクリプトなど
下記におきました・・・が、時間がないので使い方とかはあとでREADMEに書きます。多分。
https://github.com/ken57/personalize_search_experiment
その他
ツイッターとかがソーシャルネットワークのデータをオープンデータとして公開してくれていたら、もう少しわかりやすくて面白い例を出せたのではという感じがします。
louvain法はクラスタの階層構造を得ることができるので、「サブクラスが合っていたらさらにスコアを加点」みたいなことをやるともっとよい結果が得られるかもしれません。