目的
Hadoopやsparkなどの分散処理基盤でlouvain法を実行するためのソースコードをあさっていたところ、Sotera defence社のdistributed-graph-analyticsというのを見つけたので、調査します。
前回hadoop(giraph)で動かしたので、今度はspark(graphx)で動かしてみます。
https://github.com/Sotera/distributed-graph-analytics
概要
sotera-DGAのspark(graphx)版で、louvain法を使ってkarateクラブのデータをクラスタリングしてみます。
sparkのデータ入出力先にはhadoop(疑似分散環境)のHDFSを指定します。
環境
| OS/ライブラリなど | バージョン |
|---|---|
| CentOS | 7.0 |
| sotera/distributed-graph-analytics | 0.0.1 |
| Java | 1.8.0_45 |
| Gradle | 2.12 |
| spark | 1.6.2 |
| CDH | 5.0 |
手順
Hadoop(CDH5)とgradleのインストール
下記のとおり
http://qiita.com/k_ishi/items/6ea2d4cce090e47b374a#%E7%94%A8%E8%AA%9E
sparkのinstall
http://qiita.com/oic0310/items/d708639b9fe4d92b6d79
を参考にしてspark-1.6.2をインストールしました。
sparkの起動
sudo /usr/local/lib/spark/sbin/start-master.sh
sudo /usr/local/lib/spark/sbin/start-slaves.sh
karateクラブのデータの生成と配置など
/user/hdfs/input/karate.txtにkarateクラブのデータを配置します。
sparkジョブのsubmit
実行パラメータの読み込み部分にバグがあって、そのままだとCLASS NOT FOUNDとなり動作しません。
https://github.com/Sotera/distributed-graph-analytics/issues/89
用意されている起動スクリプトは、起動に必要な複数のjarファイルを一つ一つ指定しながらsubmitするようになっていますが、下記のようにライブラリを一つのjarにまとめてsubmitすると動きました。
https://github.com/ken57/distributed-graph-analytics/commit/691e287e1f041d7ab5522a3d8cfb1b74718bf353
# ビルド
cd distributed-graph-analytics
gradle fatJar
cp dga-graphx/build/libs/dga-graphx-0.1.jar /var/lib/hadoop-hdfs/
# hdfsユーザになる
sudo su - hdfs
export HADOOP_CONF_DIR=/etc/hadoop
spark-submit --executor-cores 2 --num-executors 2 --executor-memory 1G --driver-memory 1G --class com.soteradefense.dga.graphx.DGARunner --master yarn-client dga-graphx-0.1.jar louvain -i /user/hdfs/input/karate.txt -o /user/hdfs/output -s /usr/local/lib/spark -n NameGoesHere -m spark://vm-cluster:7077 --ca hdfs.url="hdfs://vm-cluster:8020/" --ca parallelism=2 --ca spark.master.url="spark://vm-cluster:7077" --ca spark.home="/usr/local/lib/spark/"
どうも、hadoopの疑似分散モードを使用していると、yarn-clusterモードでsparkのジョブをsubmitできないようなので、yarn-clientモードでsubmitしています。
実行結果
出力されるファイルの形式はこんな感じです。
(34,{community:23,communitySigmaTot:96,internalWeight:0,nodeWeight:34})
(4,{community:4,communitySigmaTot:58,internalWeight:0,nodeWeight:12})
...
(16,{community:23,communitySigmaTot:96,internalWeight:0,nodeWeight:4})
実行結果を図にするとこんな感じですね。
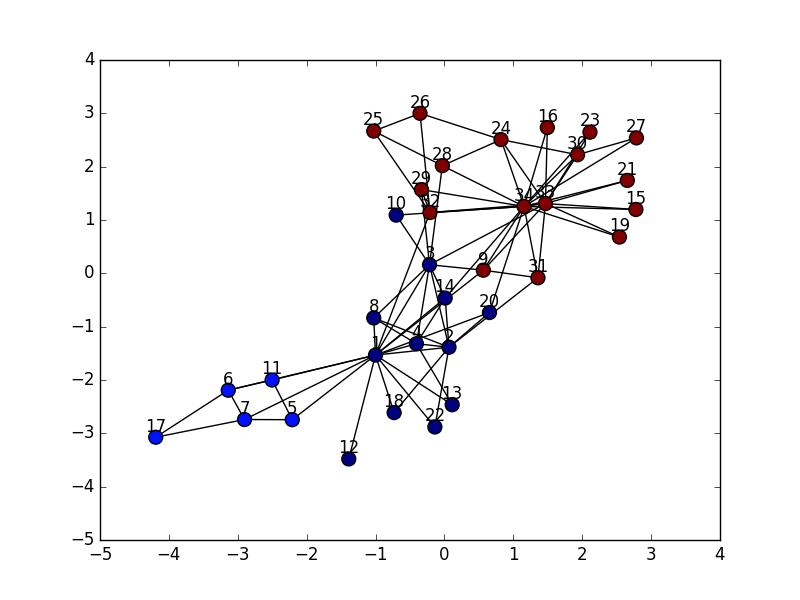
実行結果はgiraphの時のちょっと違った感じになっています。
モジュラリティQは0.402で、giraphのパラメータ調整後の0.419より少し低いですね。
オプションのパラメータをいじっても結果は変わりませんでした。
どうも、計算方法自体がちょっと違いそうな感じがします。。。
アルゴリズムの説明を読んだ感じ、louvain法のノードの選択とグラフの状態のアップデートを同時並行でやってるから、直列のアルゴリズムに近い結果を得ることはできても、同じ結果にはならないとのこと・・・(要調査)
https://github.com/Sotera/distributed-graph-analytics/tree/master/dga-graphx
giraphのほうにはこんなこと書いてないけど、なんか方針が違うんだろうか。。。
まとめ
現時点ではパラメータ読み込み部分にバグがあったりするし、プロジェクトの更新もしばらく止まっているので、参考にするだけにして1から自分で書いたほうがよさそうな気がしてきます・・・.
scalaならgradleじゃなくてsbt使いたいし。