データの前処理、特徴量作成、目的変数
3月も終盤を迎え、もうすぐ4月に突入しますね。未経験からITエンジニアを目指して私もそろそろ半年経とうとしています。
一通り学習も終え、転職活動を続けているのですがまだまだ私のスキル不足であるためになかなか転職活動に区切りがうてません。
最近では、実務も見据えて生のデータを扱いデータ分析を行っています。
まだまだ稚拙ですが、スキルのアウトプットとしてこちらに足跡を残していこうと思います。
いつもながらのことですがブログ初心者ですので読みづらかったり、表記に誤りがございましたら大変申し訳ありません。
目次
1.はじめに
2.データの前処理
3.特徴量作成
4.目的変数
5.終わりに
1.はじめに
今まではコンペで使用される綺麗なデータばかりを扱っていましたが、実際業務で扱うデータはコンペのデータみたいに綺麗に整っているわけではないため、様々な漢字、ひらがな、カタカナ、数字、記号、半角英字、全角英字が入り混じった生のデータを使って分析を行うことにしました。
今回使用させていただいたデータは「SIGNATE」様が提供する賃貸料予測につかう企業から提供されたデータを使用。
情報公開ポリシーにはデータセットの公開は不可でしたが、自身で作成したモデルや予測結果については公開OKであったためデータの前処理の話も絡めてブログに記します。
2.データの前処理
生のデータを触っていると、特徴量を作成するための加工がとにかく地味で大変な作業です。
一つのセルに複数項目が入力されていたり、記号と漢字が入り混じっていたり数字もオブジェクト型で入力されていたりととにかく形式がごちゃ混ぜです。
ここではよく使った正規表現や新しく学習したデータ加工のテクニックを記載していきます。
train_df["アクセス"] = train_df["アクセス"].str.extract(r'(\d+)')
train_df["最寄り駅への徒歩時間"] = train_df["アクセス"].str.extract(r'(\d+)').astype(float)
train_df["最寄り駅からの距離(km)"] = train_df["アクセス"].apply(lambda x:float(x)/60)
print(train_df["最寄り駅への徒歩時間"])
print(train_df["最寄り駅からの距離(km)"])
1行目では「正規表現」を使って数字のみ取り出しています。
(r'(\d+)とコードに記載することでextractメソッドを使って数字だけ抽出するという作業です。
正規表現の表を作成されている方の記事も見つけたので詳しい内容は下記リンクを参照ください。
「アクセス」のカラム内容は「都営〇〇線徒歩4分」などと入力されているため正規表現で一気に数字だけ抜くという作業を行い、2行目は抜き出した数字をfloat型に変換しています。3行目で距離計算を行い確認のため出力。
import datetime
now = datetime.datetime.now()
year_now = now.year
month_now = now.month
train_df["築年数"] = train_df["築年数"].astype(str).str.replace("年", "").str.replace("月", "").str.replace("ヶ", "").str.replace("新築", "")
train_df["築年数"] = pd.to_numeric(train_df["築年数"], errors="coerce")
train_df = train_df.dropna(subset=["築年数"])
train_df["築年数"] = (year_now - train_df["築年数"]) * 12 + month_now
築年数のデータを数値に変換しつつ計算しています。
datetimeライブラリをインポートし、現在の年数と月を計算で使うための箱を作成しました。
replaceメソッドで「築年数」に含まれる文字列を消し、数字だけ抽出、最後の行で築年数を分析できる形で計算しています。
ここでは2種類のコードの紹介をしましたが、生のデータは漢字・カタカナ・数字・英字・記号がとにかくごちゃ混ぜになっているので、とにかく加工が大変でした。元データの中身を都度確認しながら必要な特徴量を作成するためにどの文字を消してどれを残してという選別作業も加工作業も大変な作業です。
今回は3万件くらいのデータでしたがビッグデータになると途方もない作業になるのが予想されますね...
for文を回して処理する方法も試したのですが、セル内部のデータの項目にばらつきがあるためうまくいかずエラー解消が出来ませんでした。
3.特徴量作成
上記の加工作業を経て今回作成した特徴量は
・賃料
・築年数
・最寄り駅への徒歩時間
・最寄り駅からの距離(km)
・部屋面積
・周辺地域の各施設距離
・ワンホットエンコーディングで処理した間取り情報
賃貸料予測は部屋の間取りや面積、アクセス時間などが大きく寄与すると考えて作成しています。
周辺地域の情報は非常に項目が多かったため、6種類に絞って特徴量を作成しました。
4.目的変数
今回はXGBoostとLinearRegressionのモデルで学習しました。
最初は目的変数を「賃料」で設定し、分析を行っています。
from xgboost import XGBRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
#目的変数を賃料に設定しデータを分割
X = train_df.drop(["賃料"], axis=1)
y = train_df["賃料"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
model = XGBRegressor(n_estimmators=100,
max_depth=20,
subsample=0.8,
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
y_test_array = np.array(y_test)
y_pred_array = np.array(y_pred)
percent_error = np.abs(y_test_array - y_pred_array) / y_test_array * 100
mean_percent_error = np.mean(percent_error)
print("平均予測誤差率:{:.2f}%".format(mean_percent_error))
print("RMSE:", rmse)
print(y_pred)
予測結果は

次にLinearRegressionで予測
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
y_test_array = np.array(y_test)
y_pred_array = np.array(y_pred)
percent_error = np.abs(y_test_array - y_pred_array) / y_test_array * 100
mean_percent_error = np.mean(percent_error)
print("平均予測誤差率:{:.2f}%".format(mean_percent_error))
print("RMSE:", rmse)
print(y_pred)
予測結果は

どちらも誤差が少し大きく、心元ない結果となりました。
そこで、どの特徴量が分析に大きく寄与しているのか調べてみることに。
coef = pd.Series(model.coef_, index=X.columns)
importance = coef.abs().sort_values(ascending=False)
fig, ax = plt.subplots(figsize=(8, 6))
importance.plot(kind='barh', ax=ax,)
plt.xlabel('Features')
plt.ylabel('Coefficient')
plt.title('Feature Importance')
plt.show()
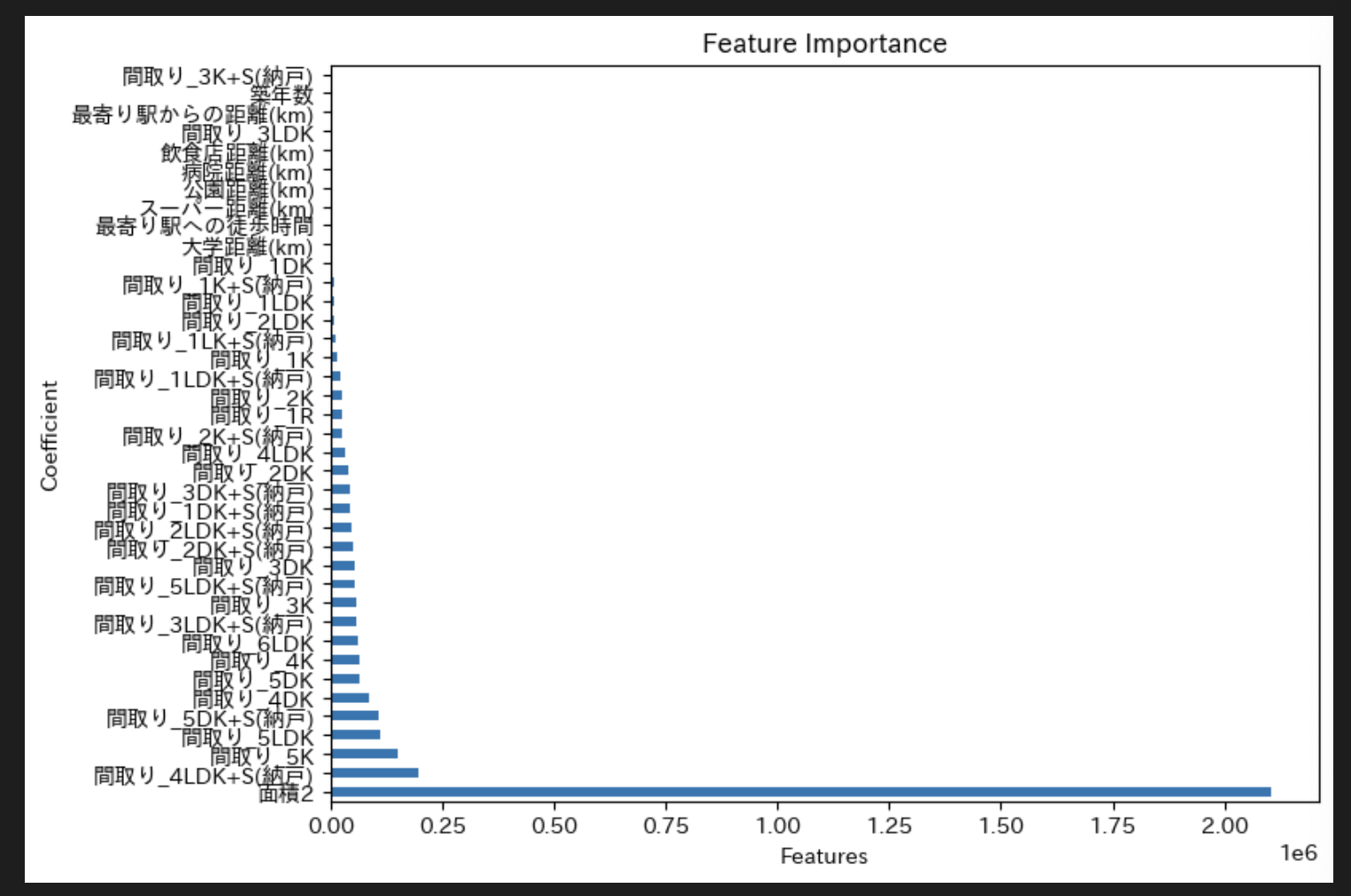
特徴量「面積2」が大きく寄与していることが判明しました。
ただ、分析の結果はあまり良い数字ではなかったため、今度はハイパーチューニングやモデルの変更、特徴量の作成を見直してもう一度トライしてみようと思います。
5.終わりに
実際に生のデータを扱ってみて、分析を行うための作業は時間も労力もかかるものであることを再認識しました。
データ加工と特徴量作成の大切さ、どの特徴量がどれだけ分析に影響を与えているのかをちゃんと調べることの大切さを改めて感じ、もっと効率の良い加工方法を身につけていければなと考えてます。
今回も読んでくださってありがとうございます。
読みづらい記事とは思いますが誰かの参考になれば幸いです。