income > 50k
今回はKaggle内のデータ「income > 50k」を使用して予測モデルを作成しました。
これは年収推定のモデルを作成できるデータセットのようで、今回はLinearSVCでチャレンジしてみたいと思います。
#ライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#データの読み込み
train = pd.read_csv("/kaggle/input/income/train.csv")
test = pd.read_csv("/kaggle/input/income/test.csv")
#学習データの先頭5行出力
train.head()

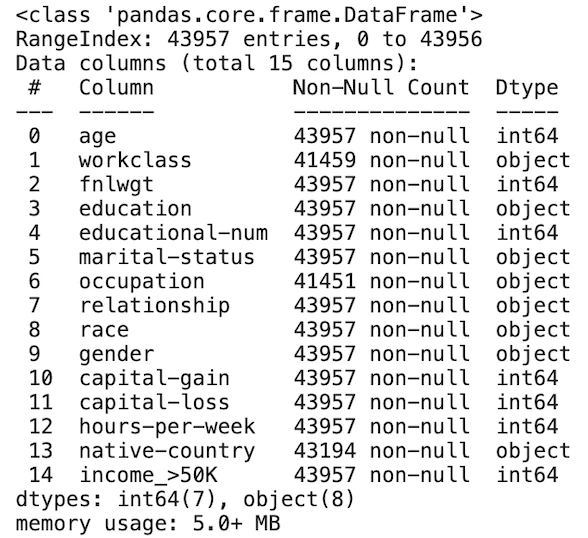
#データタイプの確認などのデータ全体像の把握
train.info()
#テストデータの全体確認
test
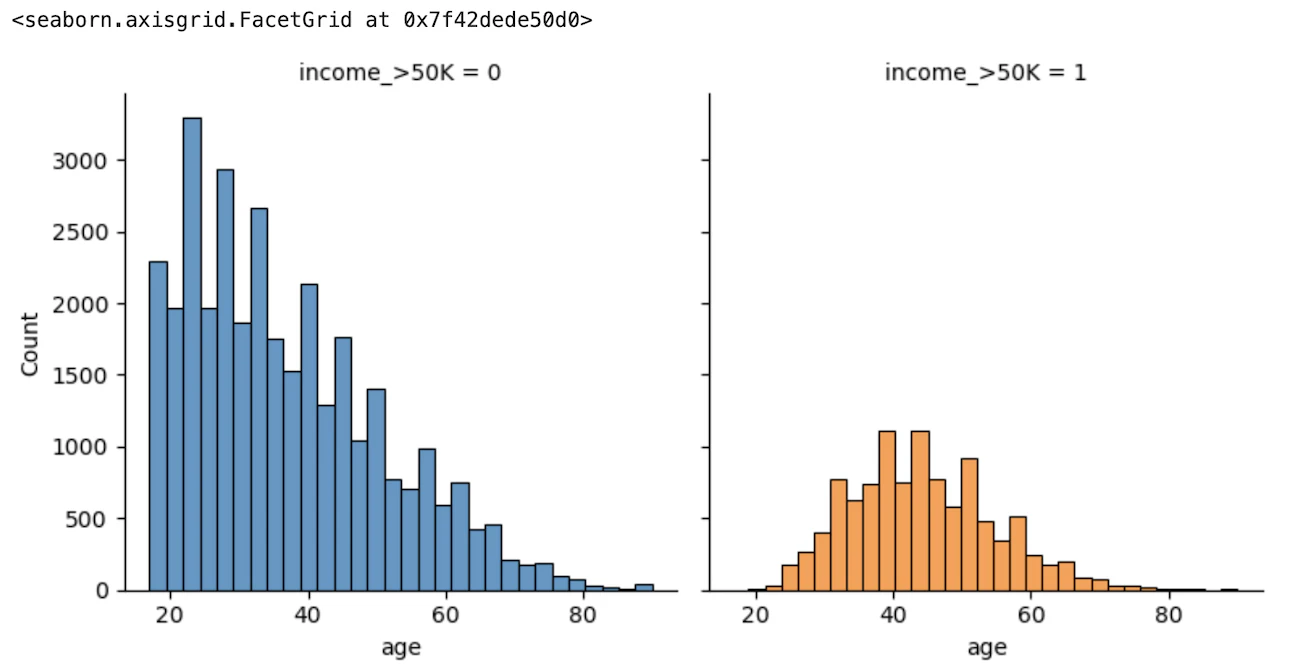
#年齢別にデータの可視化
flg = sns.FacetGrid(train_df, col="income_>50K", hue="income_>50K", height=4)
flg.map(sns.histplot, "age", bins=30, kde=False)
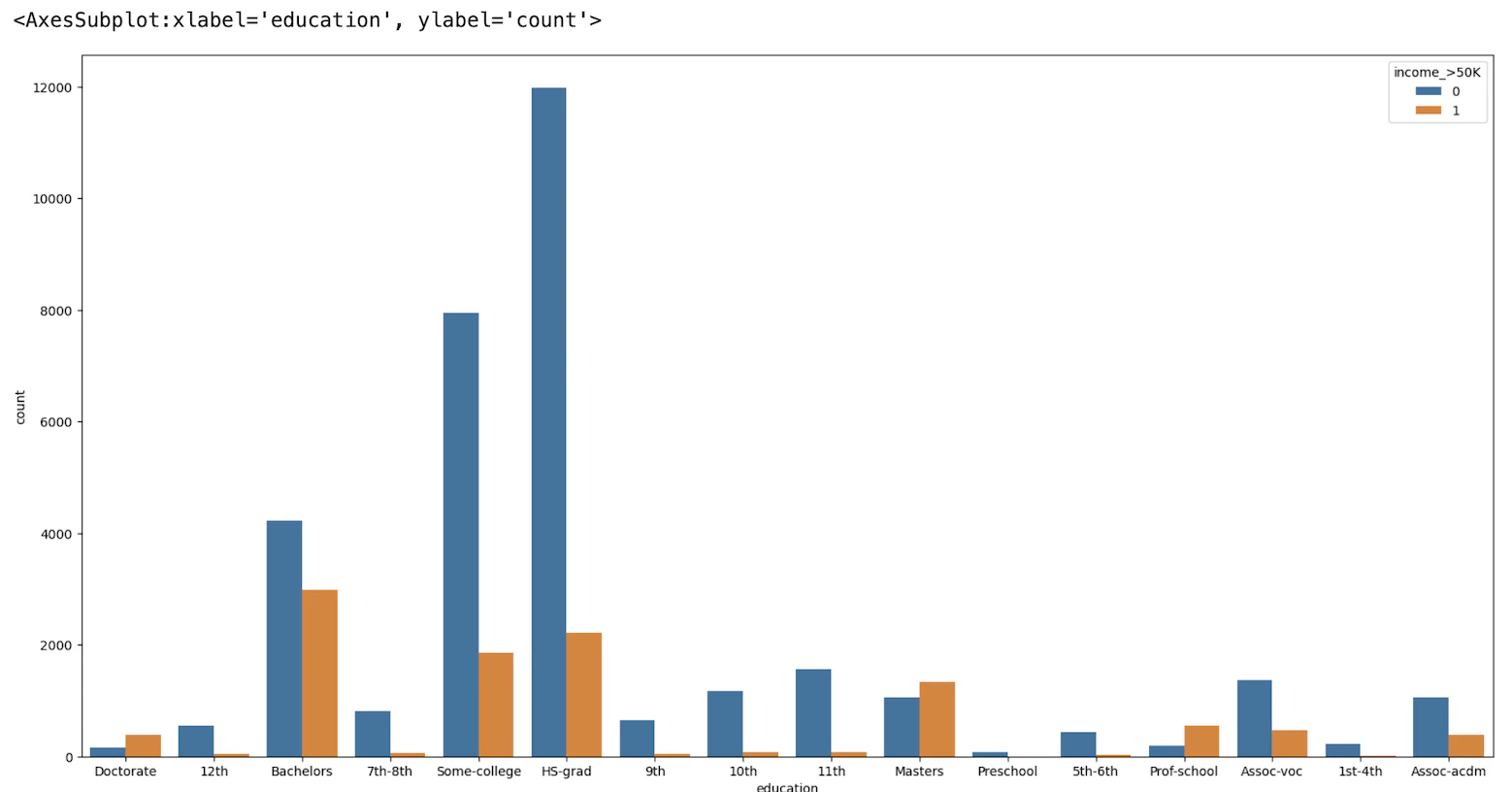
#キー”education”のデータを可視化
plt.figure(figsize=(20,10))
sns.countplot(x="education", hue="income_>50K", data=train_df)
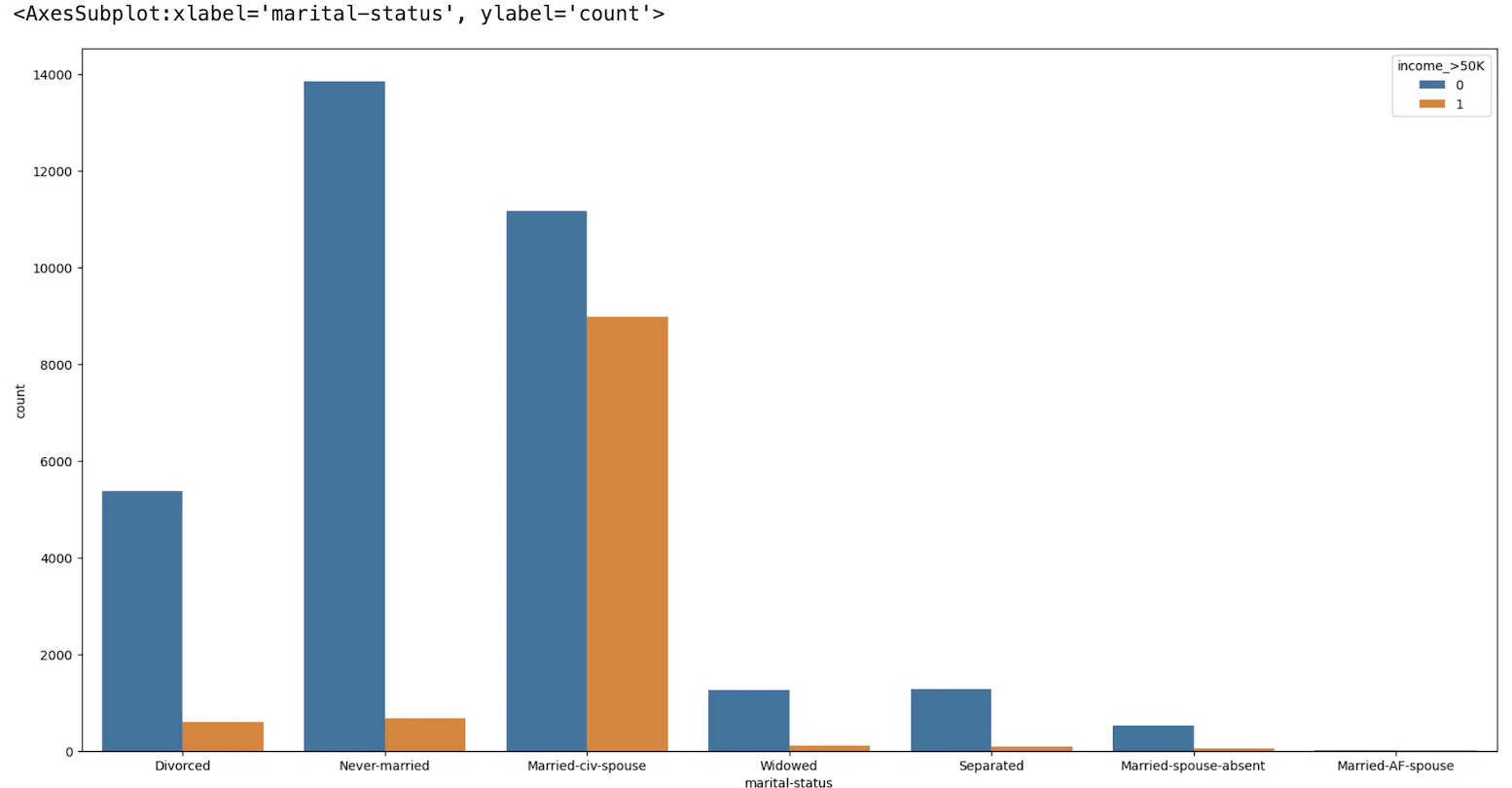
#"marital-status"を可視化
plt.figure(figsize=(20,10))
sns.countplot(x="marital-status", hue="income_>50K", data=train_df)
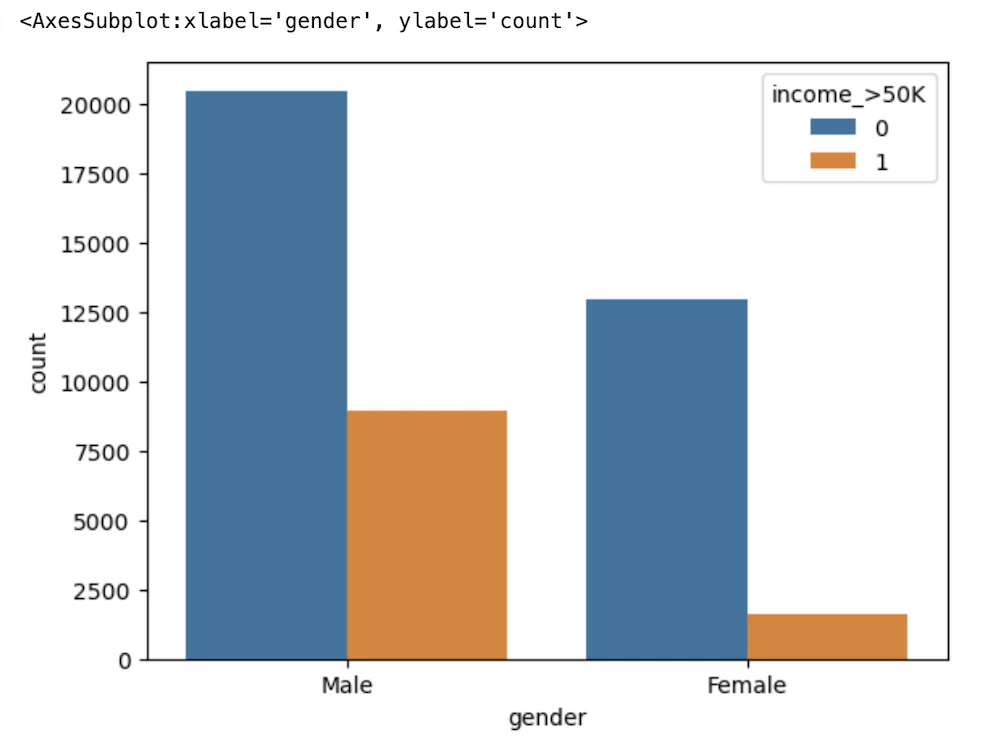
#"gender"を可視化
sns.countplot(x="gender", hue="income_>50K", data=train_df)
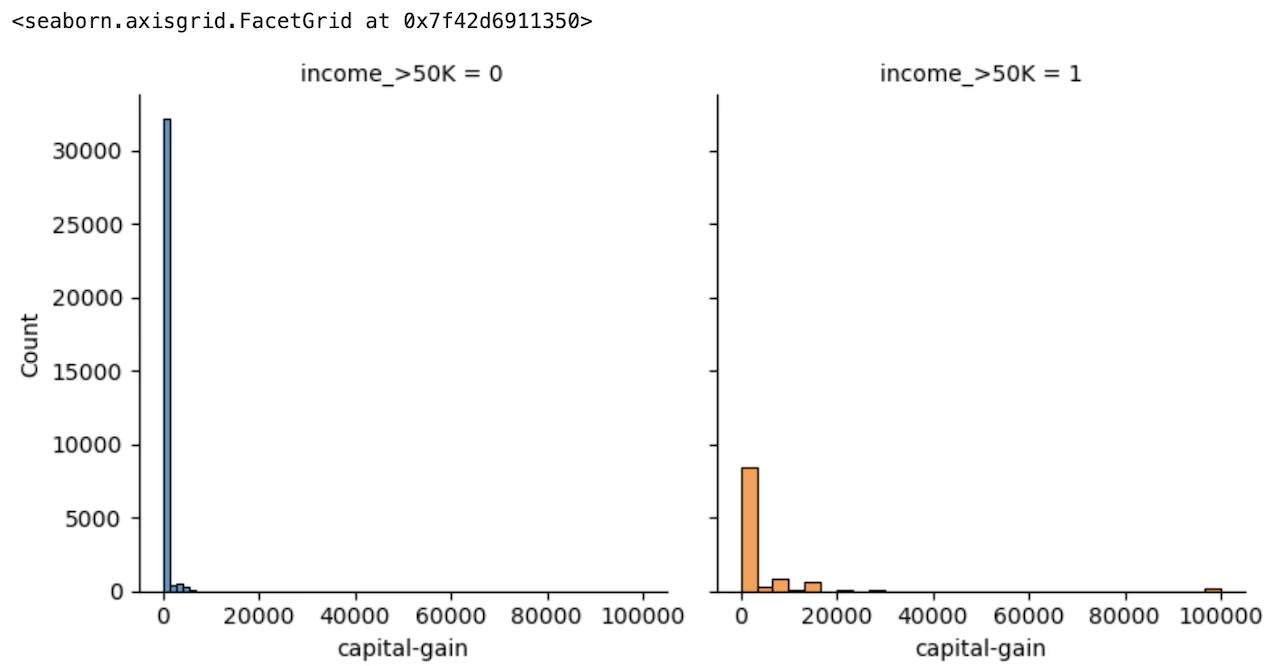
#"capital-gain"を可視化
flg = sns.FacetGrid(train_df, col="income_>50K", hue="income_>50K", height=4)
flg.map(sns.histplot, "capital-gain", bins=30, kde=False)
#不要と思われるカラムの削除
train_df = train.drop(["fnlwgt", "educational-num", "occupation", "race", "hours-per-week", "relationship", "workclass",
"native-country"], axis=1)
#欠損値の確認
train_df.isnull().sum()

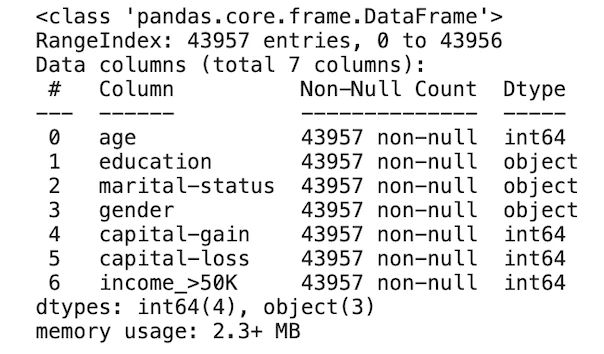
#加工したデータのデータタイプを再確認
train_df.info()
#ワンホットエンコーディング
train_df = pd.get_dummies(train_df, columns=["education", "marital-status",
"gender"])
#オブジェクト型のデータが数値データになっているのを確認
train_df

#モデルのインポート
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_df.drop(["income_>50K"], axis=1), train_df["income_>50K"], test_size=0.2, random_state=42)
#モデルに学習、予測結果を表示
model = LinearSVC()
model.fit(X_train, y_train)
pred = model.predict(X_test)
acc = accuracy_score(y_test, pred) * 100
print(pred)
print(acc)

結果は「80.9%」の予測精度となりました。
可視化作業には seabornを初めて使ったのですが、直感的で分かりやすいコーディングで大変便利さを感じました。
もっと技術をつける必要性を感じましたので毎日学習・研鑽を頑張っていこうと思います。
読んでくださってありがとうございました。